1散列的价值在于它的速度:散列使得查询变快,它将键key保存在某处,而我们知道存储一组数组最快的数据结构是数组,所以用它来表示键的信息(注意,数组保存的是键的信息,不是键本身),由于数组是固定的,当我们希望在Map中存放不确定数量的对象时,数组本身不保存键本身,而是通过键生成一个数字,将其作为数组下标,这个下标数字就是散列码,由你自定义的hashCode()散列函数生成;
2为了解决数组容量固定问题,不同的键可以产生相同的下标,也就是可能有冲突,所以说数组多大不重要,任何键总能在数组中找到它的位置。
3 查询一个值的过程就是首先计算散列码,然后使用散列码查询数组(如果数值固定,就可能保证没有散列码冲突,那就有了一个完美的散列函数),通常冲突由外部链接处理:数组并不保存值,而是保存值的list,然后对list中值使用equals()方法进行线性查询,当然最后这部分线性比较匹配会比较慢,但如果散列函数好的话,数组每个位置就只会有较少的值。因此并不是查询整个list,而是根据hashcode散列码跳到某个位置,只对该位置保存的list面很少的元素进行比较。这便是HashMap很快的原因;下面写一个简单的hashMapDemo简要说明一下怎么使用散列码来快速查到key,解决冲突的: 1 散列表中槽位,通常称为桶位(bucket), 2 为了使散列分布均匀,桶的数量通常使用 3 对于put()方法,hashCode()只对key使用,根据该key计算出的index位置如果是null,表示还没有元素被散列至此,所以要在该位置保存一个对象,就要先new 一个list(如果不为空则就用这个位置现存的list)然后遍历该list,查看是否有相同元素,如果有则替换位新元 素,如果没有,添加到list末尾; 4 get()用相同方式计算散列码为index,然后去index位置获取到元素list,遍历list,获取出以key位键的value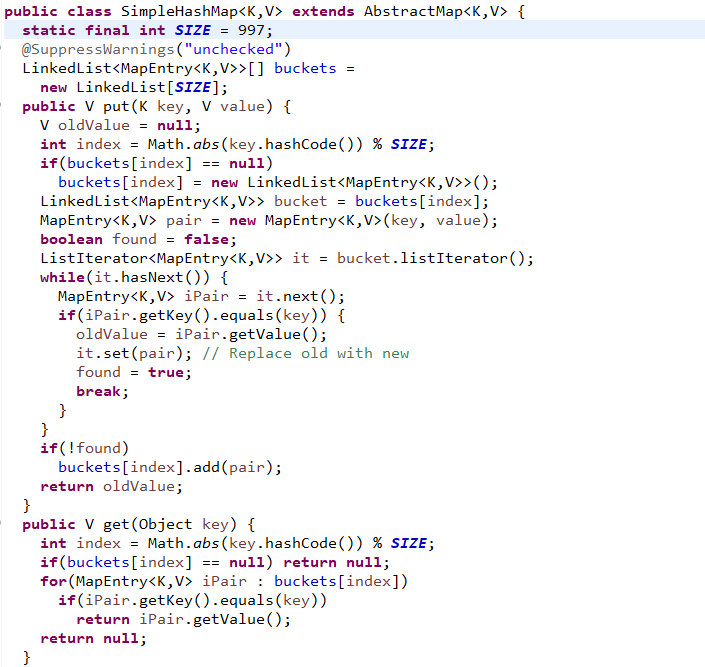 4 hashCode设计要点 1 hashCode 方法不应该依赖于对象中异变的数据,因为该对象里面的数据一旦变化,hashCode()就会产生不同散列码,相当于产生一个不同键; 2 也不应该让hashCode()依赖具有唯一性的对象信息; 3 散列码应该基于对象中有意义的内容; 4 散列码更应该关注的是速度快,不用太关注独一无二(不同对象的散列码可以相同),只要hashCode()和 equals()能确认对象身份即可; 5 生成键的索引前hashCode()值还要做进一步处理,所以散列码生成范围并不重要,int即可; 6 好的HashCode() 应该能产生分部均匀的散列码 7 编写合理HashCode()指导方法: (1) 给INT 变量的result赋值非0常量 (2)为对象内每个有意义的域(即每个可以做equals()操作的域)计算出一个int散列码
4 hashCode设计要点 1 hashCode 方法不应该依赖于对象中异变的数据,因为该对象里面的数据一旦变化,hashCode()就会产生不同散列码,相当于产生一个不同键; 2 也不应该让hashCode()依赖具有唯一性的对象信息; 3 散列码应该基于对象中有意义的内容; 4 散列码更应该关注的是速度快,不用太关注独一无二(不同对象的散列码可以相同),只要hashCode()和 equals()能确认对象身份即可; 5 生成键的索引前hashCode()值还要做进一步处理,所以散列码生成范围并不重要,int即可; 6 好的HashCode() 应该能产生分部均匀的散列码 7 编写合理HashCode()指导方法: (1) 给INT 变量的result赋值非0常量 (2)为对象内每个有意义的域(即每个可以做equals()操作的域)计算出一个int散列码 
(3)合并计算结果result=37*result+c;