MR进阶实践1: -file 分发多个文件
【-file 适合场景】分发文件在本地,小文件
-file分发原理
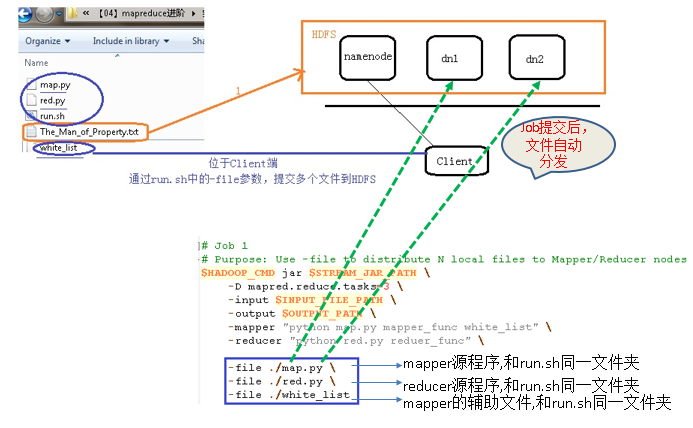
run.sh文件: 通过多个-file, 将多个本地文件分发到Hadoop集群中的compute node
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH="/02_filedistribute_input/The_Man_of_Property.txt" OUTPUT_PATH="/02_filedistribute_output" $HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH # job1: use -file to distribute 3 local file to cluster # these 3 files will bestored in the same directory in each datanode $HADOOP_CMD jar$STREAM_JAR_PATH -input $INPUT_FILE_PATH -output $OUTPUT_PATH -mapper "python map.py mapper_funcwhite_list" -reducer "python red.pyreducer_func" -file ./map.py -file ./red.py -file ./white_list
修改reducer个数为三个 (第一种 -jobconf)
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH="/02_filedistribute_input/The_Man_of_Property.txt" OUTPUT_PATH="/02_filedistribute_output" $HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH # job1: use -file todistribute 3 files # these 3 files will be stored in the same directory in each datanode $HADOOP_CMD jar$STREAM_JAR_PATH -input $INPUT_FILE_PATH -output $OUTPUT_PATH -mapper "python map.py mapper_funcwhite_list" -reducer "pythonred.py reducer_func" -jobconf “mapred.reduce.tasks=3” # deprecated option, not suggested -file ./map.py -file ./red.py -file ./white_list
修改reducer为3个(第二种 -D)
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH="/02_filedistribute_input/The_Man_of_Property.txt" OUTPUT_PATH="/02_filedistribute_output" $HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH # job1: use -file todistribute 3 files # these 3 files will bestored in the same directory in each datanode $HADOOP_CMD jar$STREAM_JAR_PATH -D mapred.reduce.tasks=3 -input $INPUT_FILE_PATH -output $OUTPUT_PATH -mapper "python map.py mapper_funcwhite_list" -reducer "pythonred.py reducer_func" -file ./map.py -file ./red.py -file ./white_list
datanode上观察分发的文件
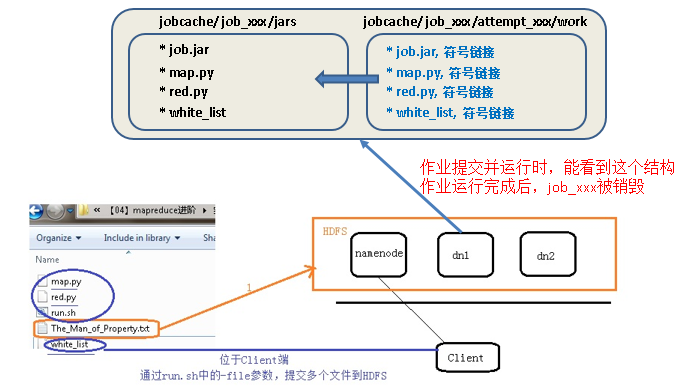
1、作业专属目录
作业开始后,会创建专属目录, taskTracker/root/jobcache/job_xxxxxxxx

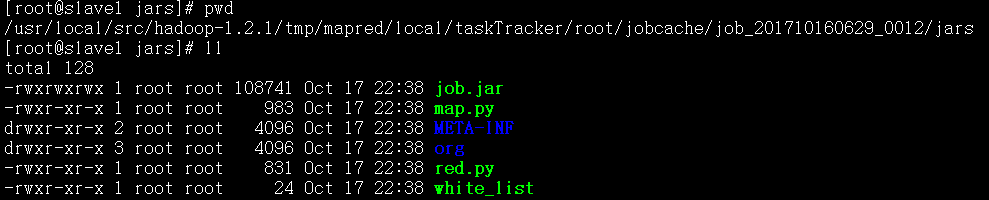
2、分发给作业的文件
被放置在同一目录,taskTracker/root/jobcache/job_xxxx/jars
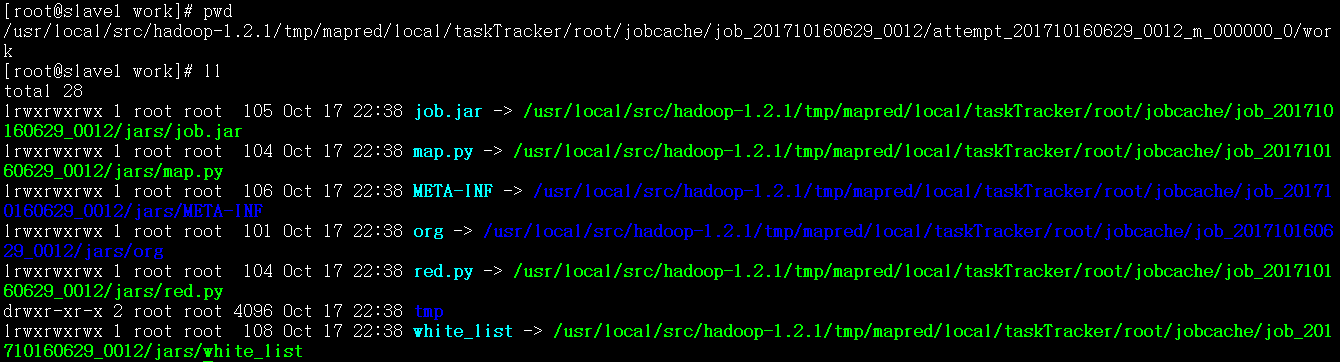
3、每一个正在运行的mapper, reducer构建attempt目录
每一个运行的mapper, reducer会构建一个attempt目录,taskTracer/root/jobcache/job_xxx/attempt_yyyyy/work , 生成符号链接文件,指向jars中的具体文件

MR进阶实践2: -cacheFile 将放在HFDS上的文件分发给计算节点
1、将mapreduce程序运行时需要的某一个辅助文件提前上传到HDFS
例如:将实践1中的white_list上传到HDFS,本地文件在上传后直接删除
# hadoop fs -put ./white_list / # rm -rf ./white_list
2、修改run.sh, 设置-cacheFile
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH="/03_cachefiledistribute_input/The_Man_of_Property.txt" OUTPUT_PATH="/03_cachefiledistribute_output" $HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH # job2: use -cacheFileto distribute HDFS file to compute node $HADOOP_CMD jar$STREAM_JAR_PATH -input $INPUT_FILE_PATH -output $OUTPUT_PATH -mapper "python map.py mapper_func WH" #这里也一定要用WH符号链接,因为作业开始运行后创建的attemps目录中只能看到WH,和map.py符号链接位于同一目录 -reducer "pythonred.py reducer_func" -cacheFile “hdfs://master:9000/white_list#WH” #WH一定要,每个attemp中要生成该符号链接,指向Tasktracer/distcache中的whitelist -file ./map.py -file ./red.py
3、运行run.sh,提交任务,观察数据节点上的文件分发
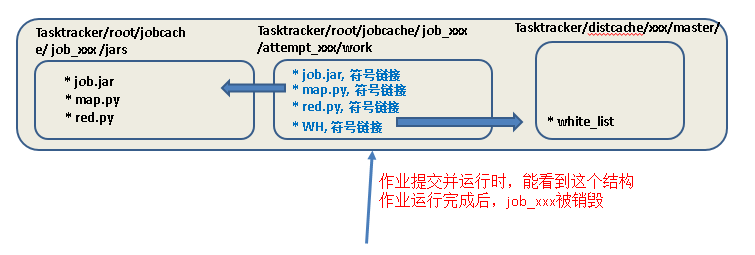
运行结束后, jobcache下的所有内容,以及distcache下的所有内容,将全部清空
MR进阶实践3: -cacheArchive 将位于HFDS上的压缩文件分发给计算节点
【使用场景】
假定有多个white_list文件,如果一个个通过-file方式上传就不太合理,可以将多个white_list文件,打包压缩为1个tar.gz文件,上传到HDFS,然后通过-cacheArchive方式,将HDFS压缩将件分发给各个compute node. 同时框架会自动将分发到各个compute node上的压缩文件进行解压
1、将本地多个white_list文件,打包为一个压缩文件w.tar.gz
目录结构:map.py, red.py, white_list_dir
|_white_list_1
|_white_list_2
注意:gzip打包后的文件,上传到HDFS,通过-cacheArchive分发到计算节点后,会自动解压为同名文件夹
打包完成后的目录结构为:map.py, red.py, white_list_dir
|_white_list_1
|_white_list_2
|_w.tar.gz
2、打包后的压缩文件上传到HDFS
# hadoop fs –put ./w.tar.gz / # hadoop fs –ls / 查看是否已经上传成功
3、修改run.sh,-cacheArchive选项
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_FILE_PATH="/03_cachefiledistribute_input/The_Man_of_Property.txt" OUTPUT_PATH="/03_cachefiledistribute_output" $HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH # job3: use -cacheArchive to distribute HDFS compressed file to compute node $HADOOP_CMD jar$STREAM_JAR_PATH -input $INPUT_FILE_PATH -output $OUTPUT_PATH -mapper "python map.py mapper_func WLDIR" #这里也一定要用WH.gz符号链接名,因为attemps中只能看到WH.gz -reducer "pythonred.py reducer_func" -cacheArchive “hdfs://master:9000/w.tar.gz#WLDIR” #WLDIR一定要,每个attemp中要生成该符号链接,指向Tasktracer/distcache中已经自动解压的文件夹,文件夹中有white_list_1,white_list_2 -file ./map.py -file ./red.py
3、重大变动:修改map.py程序
-mapper "python map.py mapper_func WLDIR"
可以看出map.py开始运行时,传入参数只能是WLDIR,表示压缩的HDFS文件分发到compute node后自动解压得到的目录
因此map.py要修改程序为遍历WLDIR字符串代表的目录,找到每个文件,然后再对每个文件做处理
4、运行run.sh,提交任务,观察数据节点上的文件分发
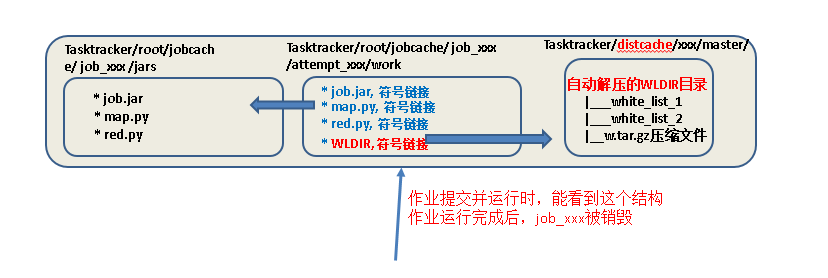
运行结束后, jobcache下的所有内容,以及distcache下的所有内容,将全部清空