进阶实践4: mapper,reducer输出数据压缩
框架提供的压缩能力
|
能否指定压缩 |
能否指定压缩方式 |
作用 |
|
|
Mapper输出 |
Yes |
Yes |
减少shuffle网络传输的数据量 |
|
Reducer输出 |
Yes |
yes |
减少占用的HDFS容量 |
重点是修改run.sh
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 3 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 7 INPUT_FILE_PATH="/05_mr_compression_input/The_Man_of_Property.txt" 9 OUTPUT_PATH="/05_mr_compression_output" 13 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH 17 # Compress output of map and reduce 18 19 $HADOOP_CMD jar $STREAM_JAR_PATH 21 -input $INPUT_FILE_PATH 23 -output $OUTPUT_PATH 25 -mapper "python map.py mapper_func WLDIR" 27 -reducer "python red.py reduer_func" 29 -jobconf "mapred.reduce.tasks=5" # 最终结果可以看到5个压缩文件
-jobconf "mapred.compress.map.output=true" 33 -jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" # map输出结果进行压缩 34 35 -jobconf "mapred.output.compress=true" 37 -jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" # reduce输出结果进行压缩 38 39 -cacheArchive "hdfs://master:9000/w.tar.gz#WLDIR" # 将HDFS上已有的压缩文件分发给Task 41 -file ./map.py # 分发本地的map程序到计算节点 43 -file ./red.py # 分发本地的reduce程序到计算节点
-D 方式指定
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 3 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 5 INPUT_FILE_PATH="/05_mr_compression_input/The_Man_of_Property.txt" 6 OUTPUT_PATH="/05_mr_compression_output" 7 9 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH 11 # Compress output of map and reduce 12 13 $HADOOP_CMD jar $STREAM_JAR_PATH 15 -D mapred.reduce.tasks=5 #指定多个reduce,看输出结果是否为5个压缩文件 17 -D mapred.compress.map.output=true 19 -D mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec 21 -D mapred.output.compress=true 23 -D mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec 24 25 -input $INPUT_FILE_PATH 27 -output $OUTPUT_PATH 29 -mapper “python map.py mapper_func WLDIR” 31 -reducer “python red.py reducer_func” 33 -cacheArchive “hdfs://master:9000/w.tar.gz#WLDIR” 34 35 -file ./map.py 37 -file ./red.py
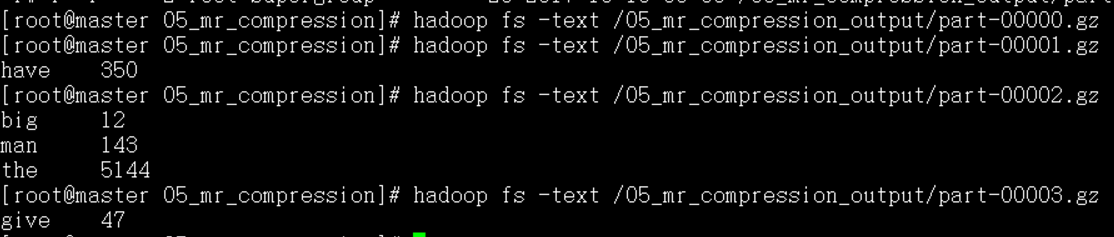
查看job运行完成后的reduce结果

对于输出的5个压缩文件,通过hadoop fs –text 可以查看gz压缩文件中的内容
MR进阶实践5: 通过输入压缩文件,控制map个数
对于压缩文件,Inputformat将不进行split, 每个压缩文件对应1个map。因此将实践4输出的压缩文件,当做Map的输入文件,就可以验证map个数是否等于输入压缩文件个数
注意:mapreducer的输入数据源可以是一个目录下的多个文件
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" INPUT_PATH="/05_mr_compression_output" # 上一个task的输出目录,所有文件都作为数据源,包括5个压缩文件,log文件,SUCCESS文 # 件夹, 由于log和SUCCESS是上一个文件的历史记录信息,会被框架自动过滤,因此只会启动处理压缩文件的5个 # map OUTPUT_PATH="/output cat" #$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # To verify map number by input compressed files $HADOOP_CMD jar $STREAM_JAR_PATH -input $INPUT_PATH -output $OUTPUT_PATH -mapper "cat" # 不做任何处理,将输入数据直接输出 -jobconf "mapred.reduce.tasks=0" # 不需要任何reducer操作
MR进阶实践6: 输入多个文件,单Reducer排序
本质:全局排序
要点:需要注意的是mapper后的排序以及reducer前的归并排序,都是对key进行字符串排序,因此会出现1, 10,110,2这样的排序结果,因此要在mapper和reducer中进行一定处理,才能得到类似数字的排序结果
|
原始数据 |
Mapper处理后数据 |
排序后Reducer前数据 |
Reducer后数据 |
|
1 |
1001 |
1001 |
1 |
|
2 |
1002 |
1002 |
2 |
|
10 |
1010 |
1003 |
3 |
|
20 |
1020 |
1010 |
10 |
|
3 |
1003 |
1020 |
20 |
Mapper: 对一行的key,value, 进行加1000操作,然后再将key转为字符串
Reducer: 对一行的key,value, 进行int(key)-1000操作,然后在将key转为字符串
# /a.txt 1 hadoop 3 hadoop 5 hadoop 7 hadoop ………………………….. 99 hadoop # /b.txt 2 java 4 java 6 java 8 java ………………………….. 100 java
run.sh
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 3 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 4 6 INPUT_FILE_PATH_A="/a.txt" 7 INPUT_FILE_PATH_B="/b.txt" # 2个数据源全部读取, inpuformat进行split 8 OUTPUT_SORT_PATH="/output_allsort_01" 9 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH 10 11 # 单Reducer实现全局排序 12 $HADOOP_CMD jar $STREAM_JAR_PATH 13 -D mapred.reduce.tasks=1 # 单个recuder,利用框架自动排序的能力,完成全局排序 14 -input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B # 指定多个输入路径 15 -output $OUTPUT_SORT_PATH 16 -mapper "python map_sort.py" 17 -reducer "python red_sort.py" 18 -file ./map_sort.py 19 -file ./red_sort.py
map_sort.py
1 #!/usr/local/bin/python 2 import sys 3 base_count = 1000 4 5 for line in sys.stdin: 6 key,val = line.strip().split(' ') 7 new_key = base_count + int(key) 8 print "%s %s" % (str(new_key), val)
reduce_sort.py
#!/usr/local/bin/python import sys base_value = 1000 for line in sys.stdin: key, val = line.strip().split(' ') print str(int(key)-1000) + " " + val
MR进阶实践7: 输入多个文件,全局逆向排序(单reducer)
本质:全局排序
分析:输入文件为多个,并且每行为key,value形式,由于MapReduce框架会自动根据key (字符串形式) 进行排序;如果只有1个Reducer,则Reducer的输入此时已经有序,直接输出即可
要点:需要注意的是mapper后的排序以及reducer前的归并排序,都是对key进行字符串排序,因此会出现1, 10,110,2这样的排序结果,因此要在mapper和reducer中进行一定处理,才能得到类似数字的排序结果
|
原始数据 |
Mapper处理后数据 |
排序后Reducer前数据 |
Reducer后数据 |
|
1 |
9998 |
9979 |
20 |
|
2 |
9997 |
9989 |
10 |
|
10 |
9989 |
9996 |
3 |
|
20 |
9979 |
9997 |
2 |
|
3 |
9996 |
9998 |
1 |
Mapper: 对一行的key,value, 进行9999-key操作,然后再将key转为字符串
Reducer: 对一行的key,value, 进行9999-int(key)操作,然后在将key转为字符串
输入数据源
# /a.txt 1 hadoop 3 hadoop 5 hadoop 7 hadoop ………………………….. 99 hadoop # /b.txt 2 java 4 java 6 java 8 java ………………………….. 100 java
run.sh
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 2 3 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 4 5 INPUT_FILE_PATH_A="/a.txt" 6 INPUT_FILE_PATH_B="/b.txt" # 2个数据源全部读取, inpuformat进行split 7 OUTPUT_SORT_PATH="/output_allsort_01" 8 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH 9 10 # 单Reducer实现全局排序 11 12 $HADOOP_CMD jar $STREAM_JAR_PATH 13 -D mapred.reduce.tasks=1 14 -input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B # 指定多个输入路径 ,分隔 15 -output $OUTPUT_SORT_PATH 16 -mapper "python map_sort.py" 17 -reducer "python red_sort.py" 18 -file ./map_sort.py 19 -file ./red_sort.py
map_sort.py
#!/usr/local/bin/python import sys base_count = 9999 for line in sys.stdin: key,val = line.strip().split(' ') new_key = base_count - int(key) print "%s %s" % (str(new_key), val)
reduce_sort.py
1 #!/usr/local/bin/python 2 import sys 3 base_value = 9999 4 5 for line in sys.stdin: 6 key, val = line.strip().split(' ') 7 print str(9999-int(key)) + " " + val
MR进阶实践8: 输入多个文件,全局排序(多reducer)
本质:全局排序
分析: 单个Reducer的隐患,也算是比较明显;Reducer的负载首先会很重,如果出现问题,整个Job都要重新来过,多Reducer可以做到负载分担,但是需要保证原本1个Reducer的输入,被划分到多个Reducer后,输出结果还是有序的
|
|
|
|
|
Key: 0~50 Key: 51~100 |
Key: 0~50 |
Reducer1 |
|
Key:51~100 |
Reducer2 |
要做到这样,我们就需要手工再构建一列“key”, 专门用于做partition阶段的分桶, 由它来保证实现上面的划分
|
|
Key-new, key, value |
|
|
Key: 0~50 Key: 51~100 |
0 0~50 val |
Reducer1 |
|
1 51~100 val |
Reducer 2 |
其次在进行mapper端和reducer端排序的时候,要基于新key和原始key, 总共2列key来排序,从而实现同一reducer内部的原始key也是排序的,这样reducer端的代码只要将新增的key丢弃即可
run.sh
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 2 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 3 4 INPUT_FILE_PATH_A="/a.txt" 5 INPUT_FILE_PATH_B="/b.txt" 6 OUTPUT_SORT_PATH="/07_output_allsortNreducer" 7 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH 8 9 10 # add in new column for partition, use 2 column as key for sort 11 $HADOOP_CMD jar $STREAM_JAR_PATH 12 -input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B 13 -output $OUTPUT_SORT_PATH 14 -mapper "python map_sort.py" 15 -reducer "python red_sort.py" 16 -file ./map_sort.py 17 -file ./red_sort.py 18 -jobconf mapred.reduce.tasks=2 # 多个reducer,进行全局排序 19 -jobconf stream.map.output.field.separator=' ' 20 -jobconf stream.num.map.output.key.fields=2 #key有2列,新增+变换 21 -jobconf num.key.fields.for.partition=1 #只用key的第一列来分桶 22 -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner #指定能基于key的某些列进行分桶的特定partitioner
map_sort.py
1 #!/usr/local/bin/python 2 import sys 3 base_count = 1000 4 5 for line in sys.stdin: 6 key,val = line.strip().split(' ') 7 key = base_count + int(key) 8 9 partition_id = 1 10 if key <= (1100+1000)/2: 11 partition_id = 0 # 0~50,pid=0; 51~100, pid=1 12 print "%s %s %s" % (str(partition_id), str(key), val)
reduce_sort.py
1 #!/usr/local/bin/python 2 import sys 3 base_value = 1000 4 5 for line in sys.stdin: 6 partition_id, key, val = line.strip().split(' ') 7 print str(int(key)-1000) + " " + val #直接丢弃手工添加的partition_id
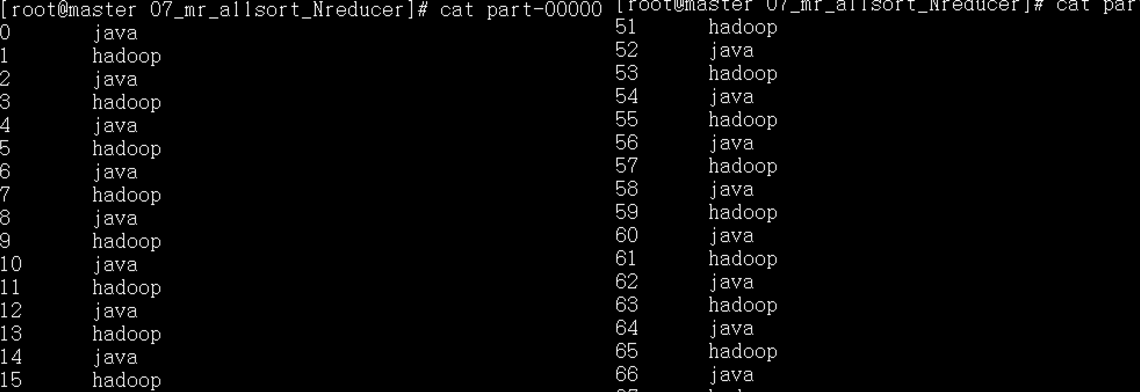
运行结果:
MR进阶实践8: 多表Join
run.sh 拆分为3个mapreduce任务
1 HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop" 2 3 STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" 4 5 INPUT_FILE_PATH_A="/a.txt" #job1的数据源 6 INPUT_FILE_PATH_B="/b.txt" #job2的数据源 7 OUTPUT_A_PATH="/output_a" 8 OUTPUT_B_PATH="/output_b" 9 OUTPUT_JOIN_PATH="/output_join" 10 11 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_A_PATH $OUTPUT_B_PATH $OUTPUT_JOIN_PATH 12 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_JOIN_PATH 13 14 15 # MapReduce Job1: 表1添加flag=1, (key, 1, value) 16 $HADOOP_CMD jar $STREAM_JAR_PATH 17 -input $INPUT_FILE_PATH_A 18 -output $OUTPUT_A_PATH 19 -mapper "python map_a.py" 20 -file ./map_a.py 21 22 # MapReduce Job2: 表2添加flag=2, (key, 2, value) 23 $HADOOP_CMD jar $STREAM_JAR_PATH 24 -input $INPUT_FILE_PATH_B 25 -output $OUTPUT_B_PATH 26 -mapper "python map_b.py" 27 -file ./map_b.py 28 29 # MapReduce Job3: cat做mapper, 每2条记录组成1个完整记录 30 # (key,1,value) (key,2, value) 31 # 使用第1列做分桶,使用1,2列做排序,通过reducer将两条记录合并 32 33 $HADOOP_CMD jar $STREAM_JAR_PATH 34 -input $OUTPUT_A_PATH,$OUTPUT_B_PATH 35 -output $OUTPUT_JOIN_PATH 36 -mapper "cat" 37 -reducer "python red_join.py" 38 -file ./red_join.py 39 -jobconf stream.num.map.output.key.fields=2 #2列做key 40 -jobconf num.key.fields.for.partition=1 #1列做分桶 41 -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
第一个作业的map_a.py, 添加flag=1
1 #!/usr/local/bin/python 2 import sys 3 4 for line in sys.stdin: 5 key,value = line.strip().split(' ') 6 print "%s 1 %s" % (key, value)
第二个作业的map_b.py, 添加flag=2
1 #!/usr/local/bin/python 2 import sys 3 for line in sys.stdin: 4 key,value = line.strip().split(' ') 5 print "%s 2 %s" % (key, value)
第3个mapreduce作业,将cat作为输入,因此mapper的输入是两张表记录的总和,并且同一个员工的两条记录在一起,并且来自表1的记录在前,来自表2的记录在后
|
Key1, 1, value1 |
|
Key1, 2, value2 |
|
Key2, 1, value1 |
|
Key2, 2 , value2 |
|
* partition基于第1列分桶,同一用户的记录就会由1个reducer处理 |
|
*key有2列,因此会基于2列key进行排序,保证表1的记录在前 |
第三个作业的reduce_join.py, 合并数据,丢弃添加的flag
1 #!/usr/local/bin/python 2 import sys 3 cur_key = None 4 tem_val = ‘’ 5 6 7 for line in sys.stdin: 8 key,flag, value = line.strip().split(' ') 9 flag = int(flag) #要做转换,否则没有任何输出 10 11 if cur_key == None and flag==1: 12 cur_key = key 13 tem_val = value 14 elif cur_key == key and flag==2: 15 print ‘%s %s %s’ %(cur_key, tem_val, value) 16 cur_key = None 17 tem_val = ‘’
最后将运行结果通过hadoop fs -get下载到本地,就可以看到两张表已经完成join操作