1、集群配置思路
1)每台节点上要启动一个broker进程,因此要配置每台的server.properties
broker id, log.dirs, zookeeper.connect
2) 每台broker都要连接zookeeper将状态写入,因此要配置每台的zookeeper.properties
dataDir, zookeeper集群snapshot数据的存放地址,和zookeeper集群的配置保持一致
3)zookeeper.properties 可以在一台节点上配置,并分发给其他
4)server.properties 可以在一台节点上配置,分发给其他节点后,修改broker id为各自的id
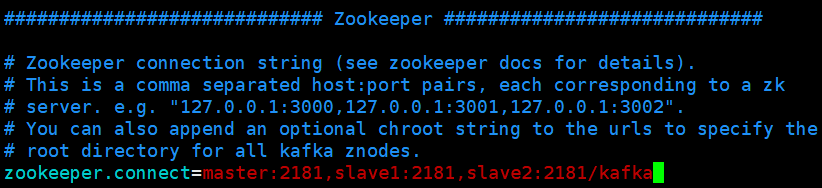
2、集群配置文件
zookeeper.properties
3台节点的配置相同

server.properties(broker0 )
其他2个节点除了broker.id,都保持相同的配置





3、集群起停
在每个节点上运行启动脚本
# ./bin/kafka-server-start.sh ./config/server.properties
在每个节点上运行停止脚本
# ./bin/kafka-server-stop.sh
4、集群操作
1) Topic查看
# ./bin/kafka-topics.sh --list --zookeeper master:2181/kafka
--zookeeper参数一定要带 (broker无状态,通过zookeeper维护kafka元数据), chroot进行过修改的话,也一定要带
2)创建Topic
3副本,3个partition
# ./bin/kafka-topics.sh --create --zookeeper master:2181/kafka --topic mytopic --replication-factor 3 --partitions 3
replication-factor 包括leader和follower在内的所有broker个数
3) 查看Topic描述
# ./bin/kafka-topics.sh --describe --zookeeper master:2181/kafka --topic mytopic

4) 删除Topic
# ./bin/kafka-topics.sh --delete --zookeeper master:2181/kafka --topic mytopic

注意:
1)server.properties中的delete.topic.enable=true, 否则只是标记为删除,并不是真正删除
2)topic的数据会被同时删除,如果因为某些原因导致topic数据不能完全删除,topic只会被marked for deletion
此时创建同名的topic就会出现名称冲突
5) 选择一个节点,启动producer,模拟消息发布
在master上启动producer进程
# ./bin/kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic ctopic
写入的数据,每行一条消息,针对每条消息(由于没有key), 随机选择1个partiton进行存储,3条消息被分别存储在了3个partition中
6) 选择一个节点,启动consumer,模拟消息订阅
# ./bin/kafka-console-consumer.sh --topic ctopic --from-beginning --zookeeper master:2181/kafka
在slave1上启动consumer,由于消息分布在3个partition中,因此consumer收到的消息只能保证同一个partition内的有序

7) 模拟broker挂掉,查看partition的leader,ISR变化
slave2挂掉前, topic的partition情况

停止slave2上的broker
# ./bin/kafka-server.stop.sh
slave2挂掉后,topic的partition情况,Partiton的leader和ISR发生了变化

zookeeper中记录broker在线情况的ids目录也发生了变化

8) 恢复broker,查看partition的leader,ISR变化
leader将维持故障后的状态,但ISR(in-sync replica)中slave2将恢复

9)如果想将leader恢复为最初的状态,则可以进行prefer-leader的重新选举
# ./bin/kafka-preferred-replica-election.sh --zookeeper master:2181/kafka
partition的leader将恢复为初始状态

注意:如果server.properties中的auto.leader.rebalance.enable=ture, 则将自动进行preferred-leader选举,自动恢复各个partition的leader为故障前的状态
10)集群节点替换
如果某个broker机器出现故障,无法重启,就需要使用新的机器来代替,主要是做两件事情
1、将新机器kafka配置文件中的broker.id设置为与原机器一样, 配置文件和原始broker保持严格一致
2、启动kafka,注意kafka保存数据的目录不会自动创建,需要手工创建