一、秒杀业务为什么这么难做
秒杀系统,库存只有一份,所有人会在集中的时间读和写这些数据。
例如:
- 小米手机每周二的秒杀,可能手机只有1万部,但瞬间进入的流量可能是几百几千万。
- 12306抢票,票是有限的,但是抢票的人很多,都读取相同的库存。读写冲突,锁非常严重,这是业务难的地方。
那我们怎么优化秒杀业务呢?
二、优化方向
(以上的两个场景要优化有两个方向)
- 将请求尽量拦截在系统上游(不要让锁冲突落到数据库上去)。传统的秒杀系统之所以挂,是因为请求都压到后端数据层,数据读写冲突严重,并发高响应慢,几乎所有请求都超时,流量最大,下单成功的有效流量非常小。以12306为例,一趟火车其实只有2000张票,但是抢到的人却有200万,基本没人能买票成功,请求有效率为0.
- 充分利用缓存,秒杀买票,这是一个典型的读多写少的应用场景,大部分请求是车次/票查询,下单和支付才是写请求。一趟火车只有2000张票,200万人来买,最多2000人下单成功,其他人都是查库存,写入操作的比例是0.1%,而读取的操作比例是99.9%,非常适合缓存来做优化。
三、常见秒杀架构
常见的秒杀架构基本是这样的
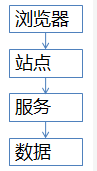
- 浏览器端,最上层,会执行一些JS代码
- 站点层,这一层会访问后端数据,将操作响应返回给浏览器
- 服务层,向上游屏蔽底层数据细节,提供数据访问
- 数据层,最终的“库存”会存放在这里,mysql是一个典型(当然还有缓存),这张图虽然简单,但是能形象的说明大流量高并发的秒杀业务架构(根据笔者从业的经验,基本所有公司的软件架构都脱离不了这几层,大同小异),后面详细解 析各层级怎么优化。
四、各层优化细节
- 第一层:客户端怎么优化(浏览器层,APP层)
大家应该都玩过微信摇一摇抢红包,是每一次摇一摇,就会往后端发送请求么?
回顾一下我们12306刚出来那年抢票的场景,点击“查询”按钮之后,系统卡在那里或者响应非常慢,这时用户就会再次点击”查询“,继续点点点,可是这样有用么?徙增系统负载,如果真实购买用户只有200W,那一个用户多点击5次,
就有1000万,多出来80%的用户怎么整?
-
- 产品层面优化:用户点击查询或者购票操作后,按钮置灰,禁止用户重复提交。
- JS层面优化:限制用户在x秒内只能提交一次请求。
上面说到摇红包,就算我们疯狂的把手机甩飞了,系统也只是在x秒才向系统发送请求。
这就是所谓的“将请求尽量拦截在系统上游”,越上游越好,浏览器层,APP层就给拦住,这样就挡住了多出那80%的用户请求。
但是,这种办法只能拦截住普通的用户,对于高端的程序猿们来说是拦不住的,firebug一抓包,http长啥样都知道了,js是拦不住程序员写for循环调用http接口的,这部分请求如何处理?
- 第二层:站点层面的请求拦截
怎么防止程序猿们for循环请求呢?有去重依据么?ip?cookie-id?这类“秒杀”业务都需要登录,用我们加了密的uid即可。在站点层面,对uid进行请求计数和去重,一个uid在5秒内只允许1个请求(例如生成uid时加入时间戳),
这样就可以拦截住程序猿们的for循环请求。
5秒只透过一个请求,那其他请求怎么办?缓存,页面缓存,同一个uid访问频度做页面缓存,x秒内到达站点请求,均返回同一个页面。 如此限流,既能保证用户体验又能保证系统的健壮性。
(页面缓存不一定要保证所有站点返回一致的页面,直接放在每个站点的内存也可以,优点是简单。缺点是http请求落到不同的站点,返回的车票数据可能不一样。)
这是站点层请求拦截和缓存的优化
如果,有黑客控制了10万个肉鸡,不同的uid,同时发送请求的话,我们怎么办?站点层按照uid限流已经拦截不住了。
- 第三层:服务层拦截
(反正不要让请求落到数据层上)
服务层如何来拦截呢?请求队列,对于写入操作的请求,每次只透有限的请求去数据层,这个有限取决于有多少部小米手机或多少张火车票。如果库存不够则全部返回“已售完”。
对于读取的请求如何优化?用cache抗 ,不管是mecached还是redis,单机抗个每秒10万都没问题,如此限流,只有非常少的写入请求,和非常少的读取缓存mis的请求会透到数据层去,又有99.9%的请求被拦住了。
- 第四层:数据层
浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了请求队列与数据缓存,每次透到数据层的请求都是可控的。db基本没什么压力了,还是那句话,库存是有限的,透这么多请求来数据库没有意义。
全部透到数据库,100万个下单,0个成功,透3000到数据库,全部成功。请求有效率为100%。
总结:
再重复一下关于秒杀系统的两个优化思路:
- 尽量将请求拦截在系统上游(越上游越好)
- 读多写少的应用多使用缓存(缓存抗读压力)
- 浏览器和APP:做限速
- 站点层:按照uid限速,做页面缓存
- 服务器:按照业务做写请求队列控制流量,做数据缓存
- 数据层:闲庭信步
- 并且结合业务做优化。
文章内容来源于微信公众号“架构师之路”,欢迎大家关注。
我在文章中看到了几个技术点:memcache,请求队列。有时间我好好研究一下,再整理到自己的博客上。
如果大家有什么好的想法,可以留言,我肯定会学习并实践好再拿出来分享。
非常感谢。
如果对您有帮助,请点赞!