一、Dashboard(仪表盘,总览页面)
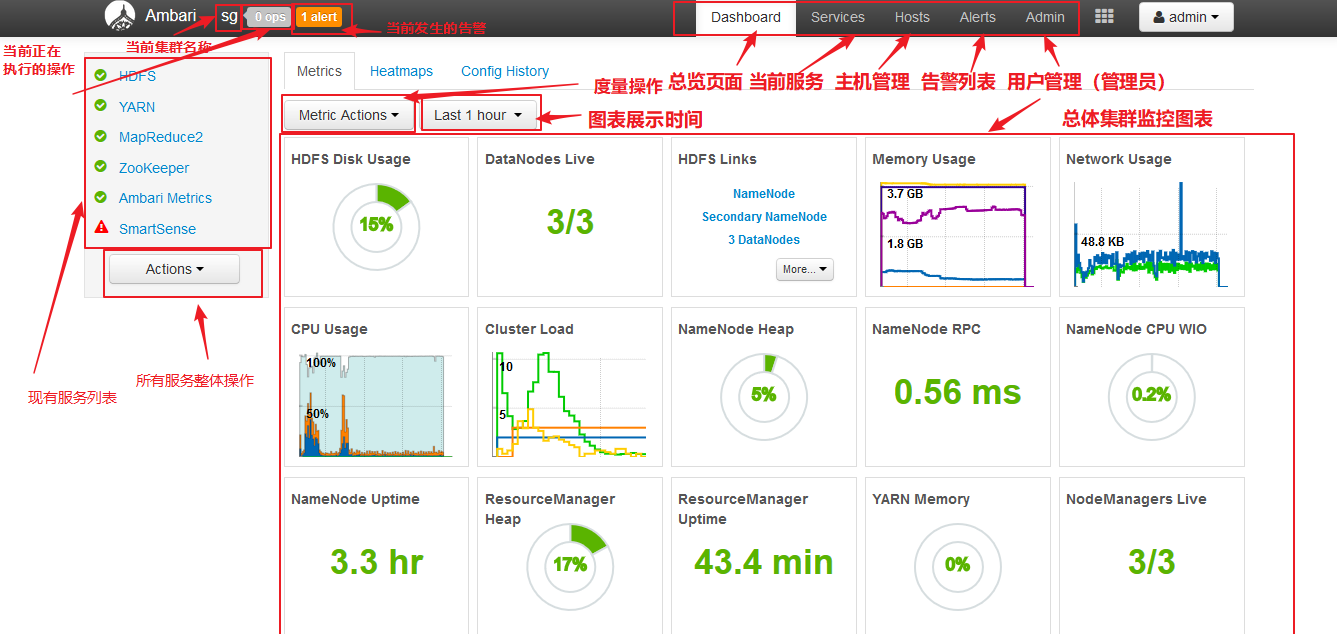
【总览】
【集群操作】
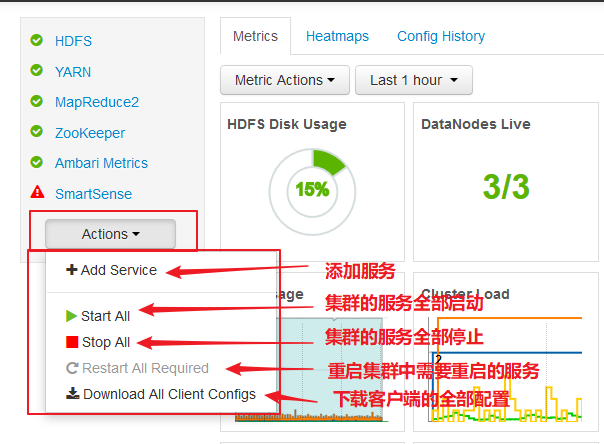
【配置文件下载】
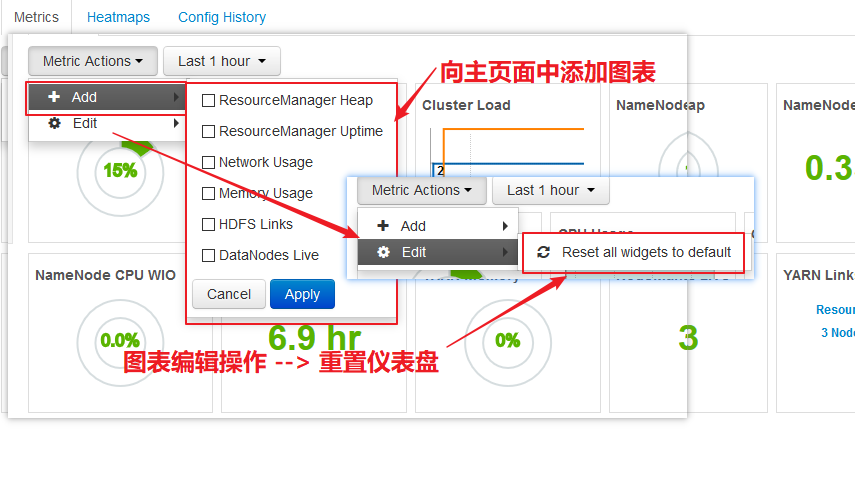
【图表操作】
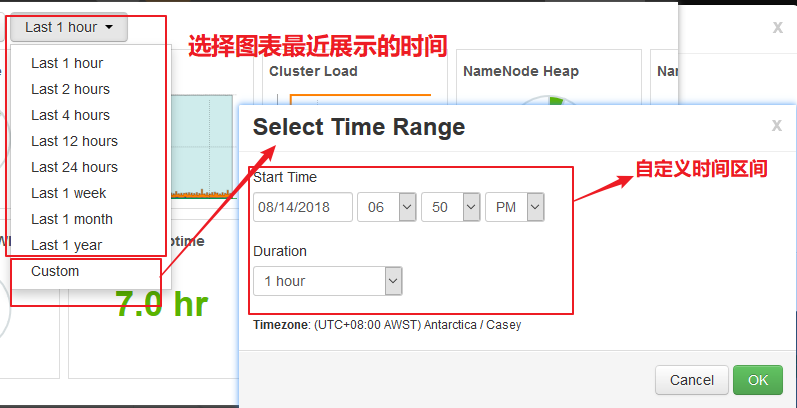
【图表时间配置】
【集群总体监控图表】

Memory Usage:整个集群的内存使用情况,包括 cached,swapped,used,和shared。
Network usage:整个就群的网络流量,包括上行和下行;
CPU Usage:集群的CPU使用情况;
Cluster Load:集群整体加载信息,包括节点数目,总CPU个数,正在运行的进程
【HDFS层面】
【HDFS Disk Usage】

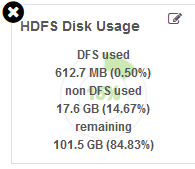
左图:整个集群的磁盘使用情况。
右图:DFS的使用情况;non DFS的使用情况;磁盘实际剩余空间。
总共:100G空间。
如果配置了dfs.datanode.du.reserved = 30G。
那么,HDFS可以理所应当的占据70GB的空间。
这个时候,如果系统文件或者其他文件已经使用了40GB。
那么就意味着,最多给HDFS的空间只剩下60GB了!!
本来讲道理,HDFS有70GB的空间可以挥霍,但是现在空间只有60GB。
是不是说,有10GB应当给HDFS用的空间,却被其他东西使用了?
这个10GB的空间,就是Non - DFS!
如果dfs.datanode.du.reserved配置了0GB。
那么就意味着,只要不是HDFS使用的空间,都是NonDFS!!
【NameNode Heap】
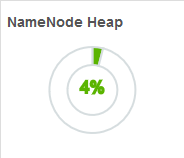
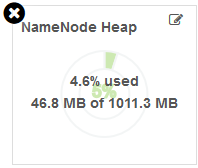
NameNode的JVM堆使用情况。
【NameNode CPU WIO】
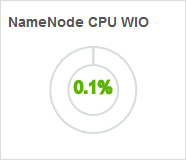
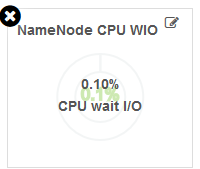
NameNode节点的CPU WIO。表示CPU空闲等待IO的情况,参数越高,说明CPU在长时间等待磁盘、网络等IO的操作而空闲。IO瓶颈较大。
【NameNode RPC】
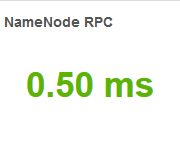
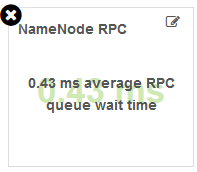
RPC请求在队列中的平均滞留时间。
【NameNode Uptime】
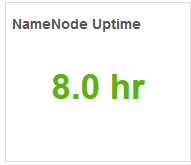
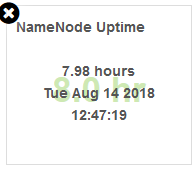
NameNode累计上线时间,以及上线时间点。
【DataNodes Live】
DataNode的状态。
【HDFS Links】
HDFS相关页面的快速链接。
【Yarn 层面】

YARN Memory:Yarn集群的内存使用率。
【ResourceManager Heap】
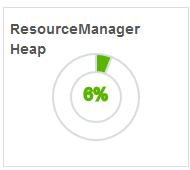
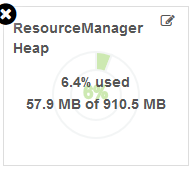
RM的JVM堆使用情况。
【ResourceManager Uptime】

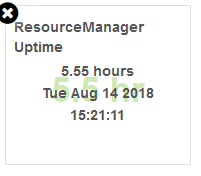
RM累计上线时间,以及上线时间点。
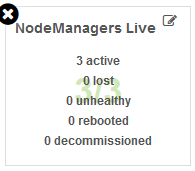
【NodeManagers Live】
NM的节点状态监控。

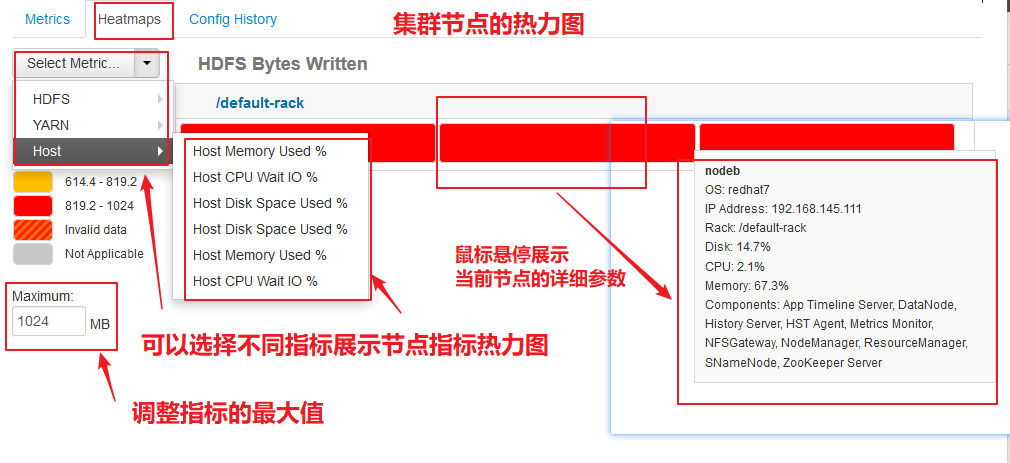
【节点热力图】
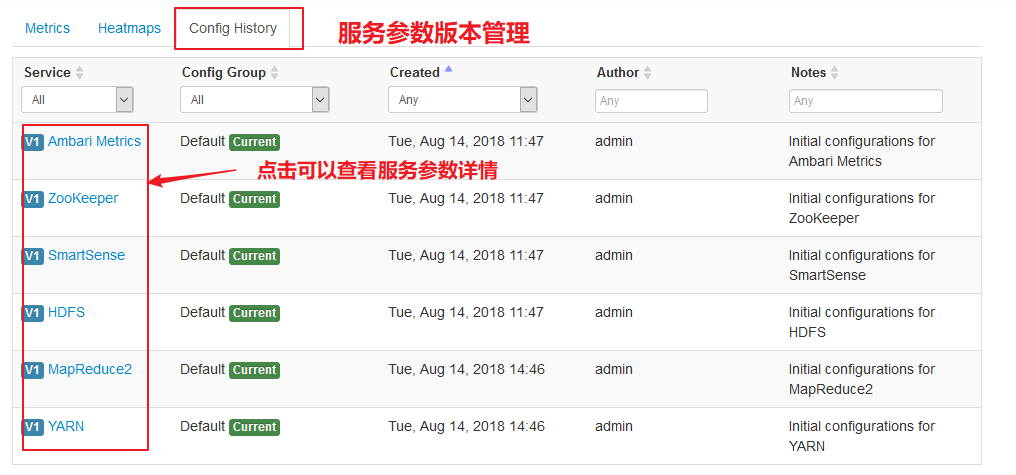
【服务参数版本管理】
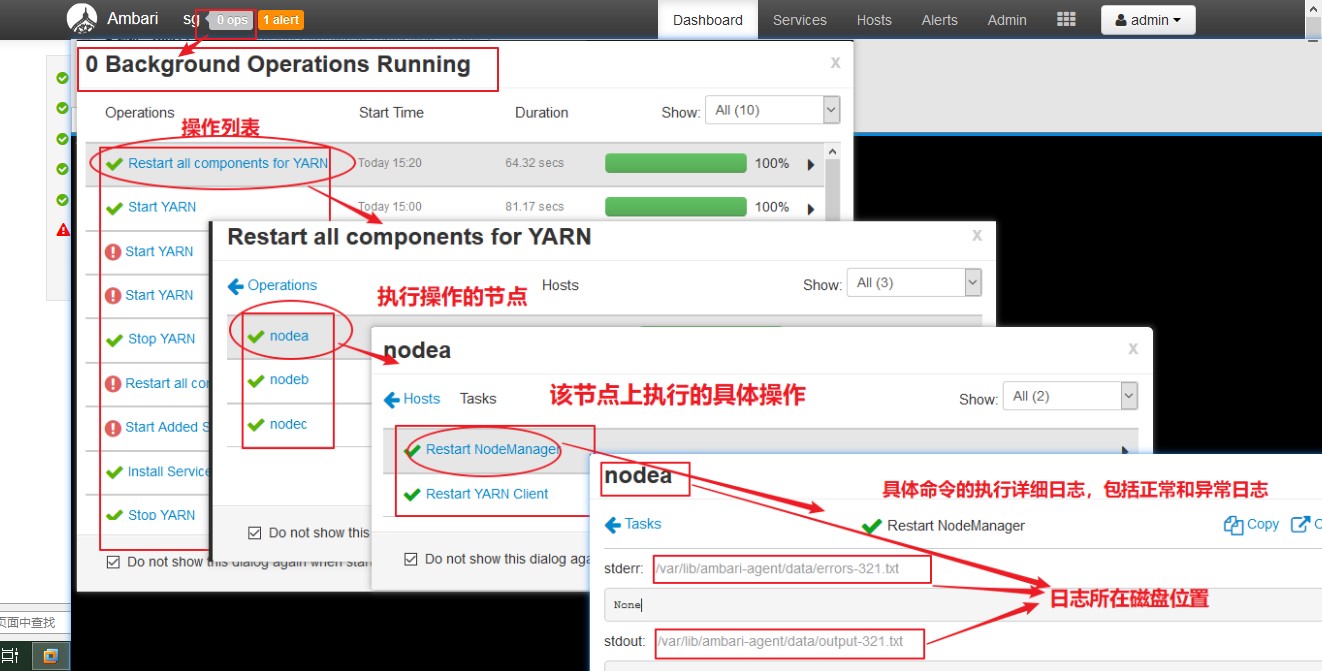
【查看操作】
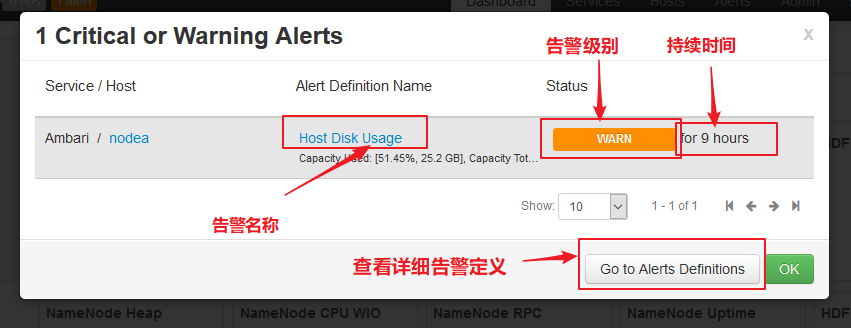
【查看告警】
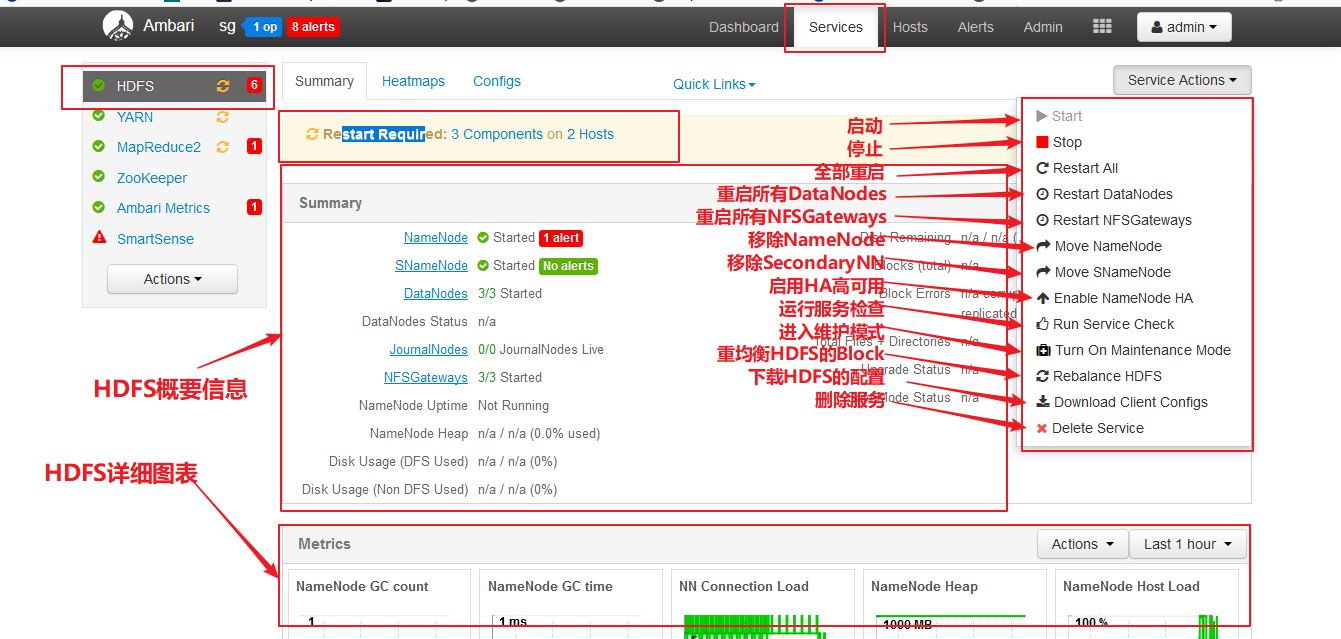
二、服务面板
下面是HDFS的主面板,其他的类似。
三、参数配置、组、版本
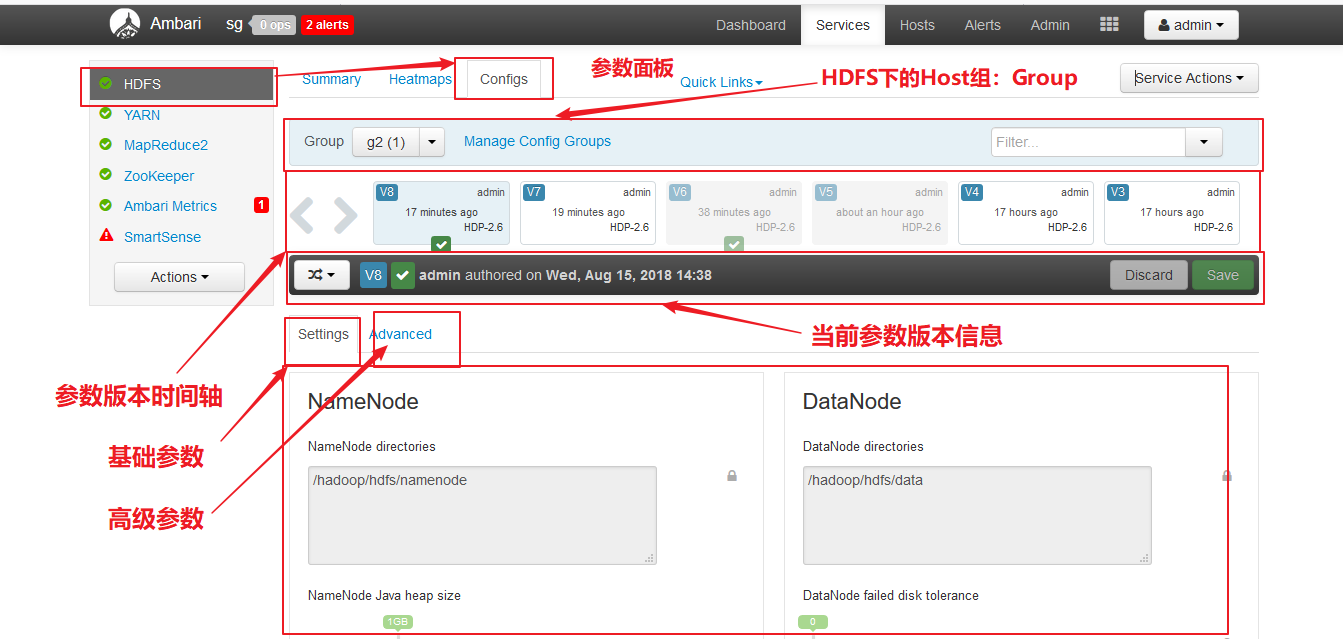 【服务配置版本与组的时间上关系】
【服务配置版本与组的时间上关系】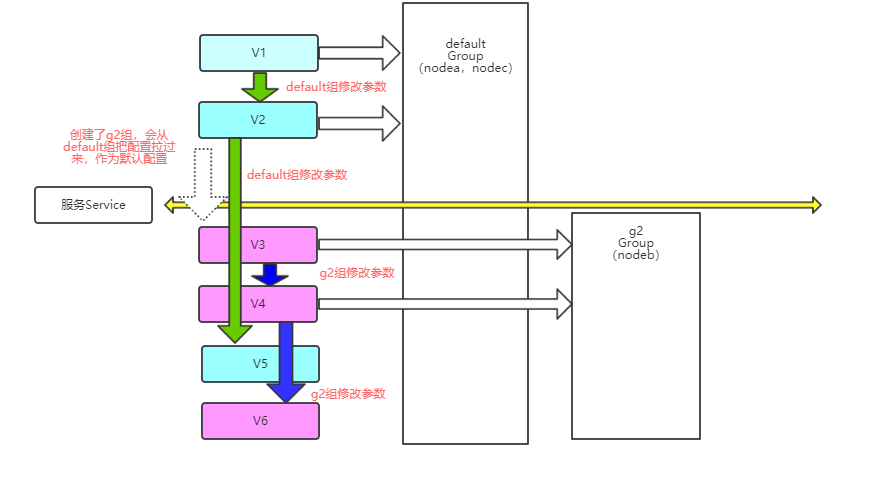


可以把Default理解为主版本(master版本),默认所有的节点配置都是按照这个来。
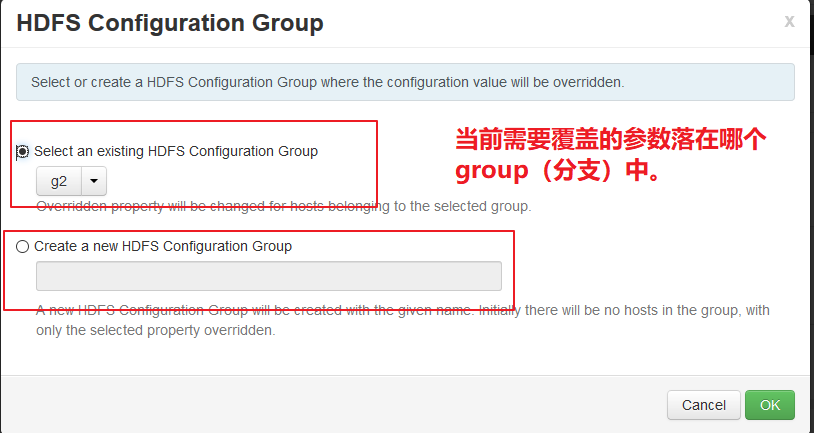
可以对这个主版本创建一个分支,也就是创建一个group。group中存储额外override覆盖的参数。
group中的参数会在哪个节点中生效取决于该group中配置了哪些host。
在默认的Default组的config面板中,参数都可以直接修改,这里改的是master主版本的配置。
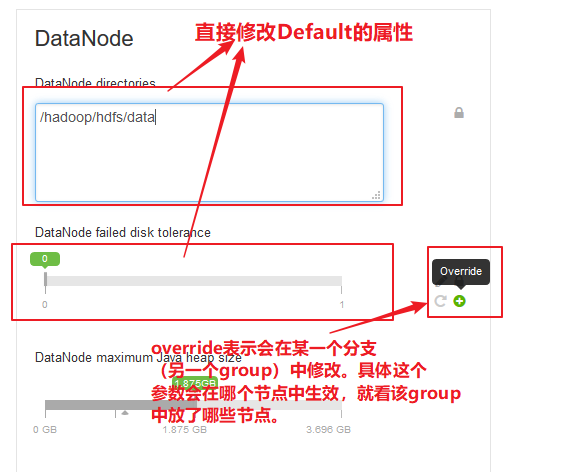
核心参数不允许Override。
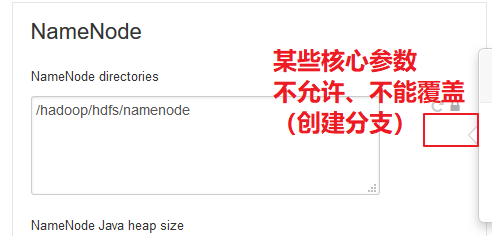
也可以Override这个参数,一旦点击,就会提示说在哪个group中改这个参数。
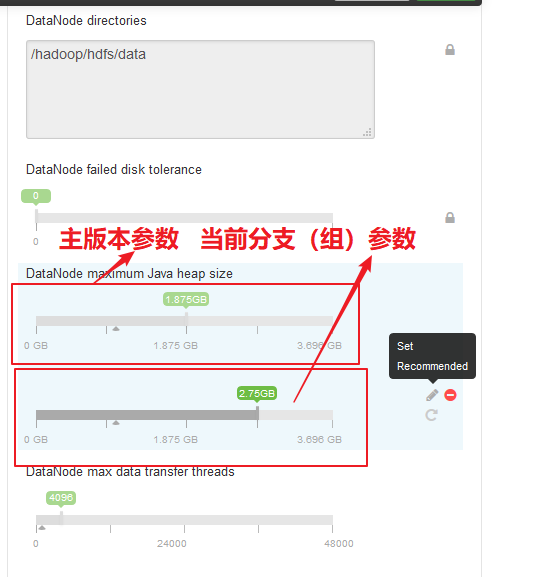
在分支组中的配置面板如下: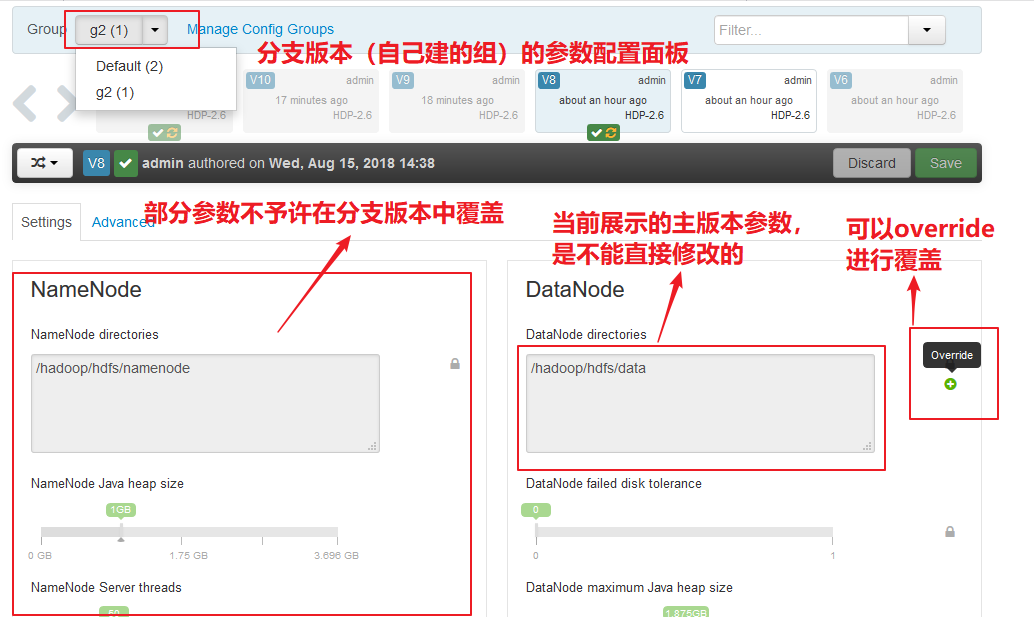
四、Host主机管理
主机列表视图:
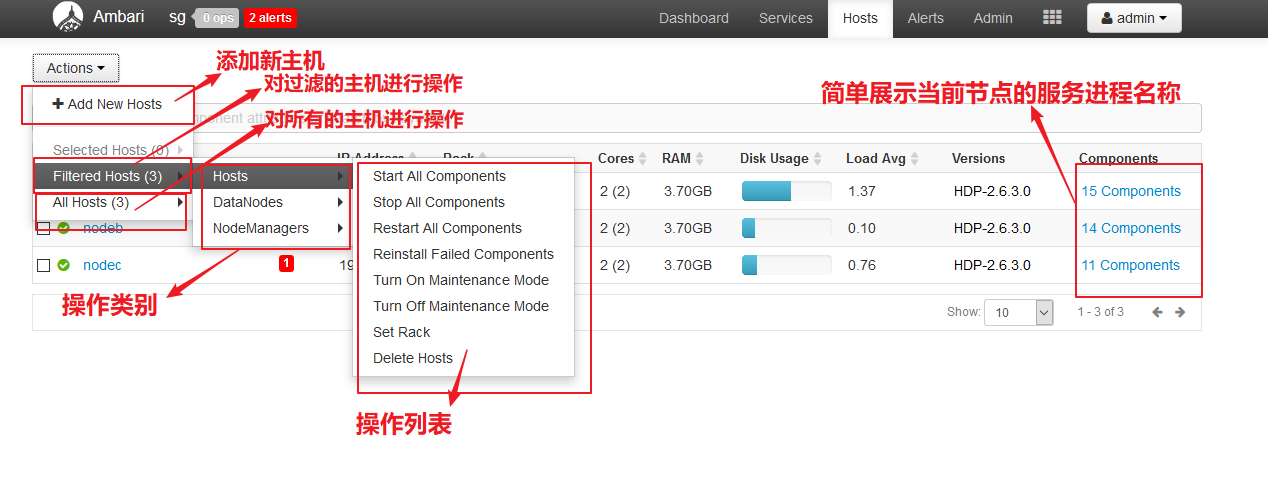
主机视图:

五、告警管理
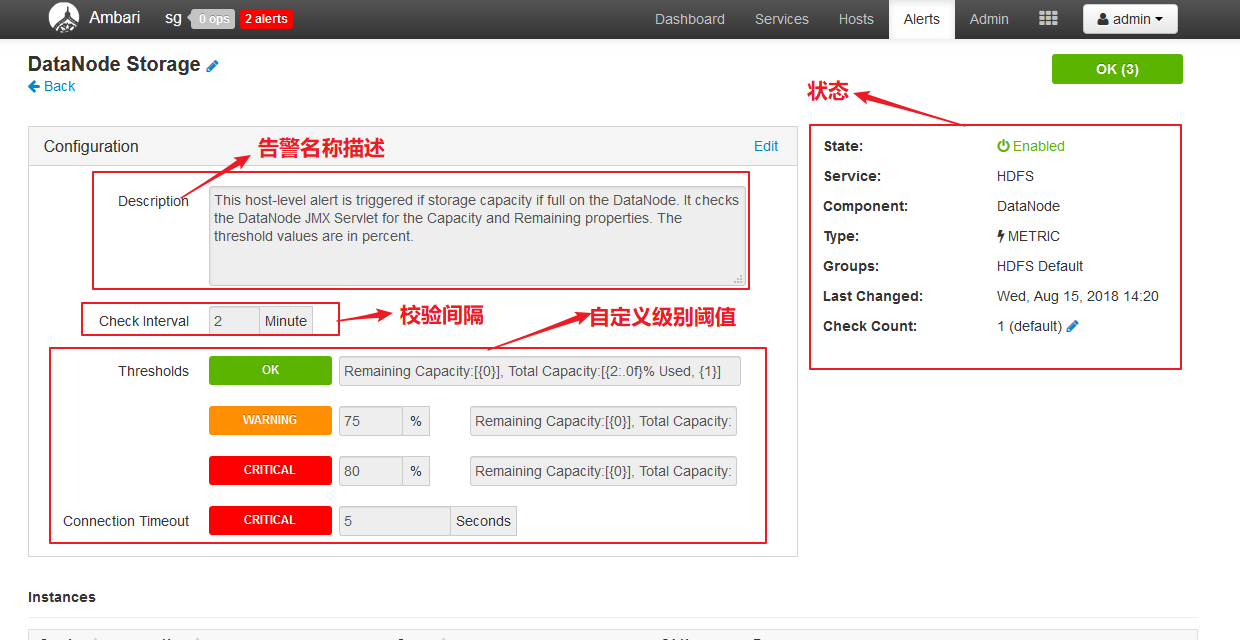
告警列表视图:

告警详情:
六、Ambari管理
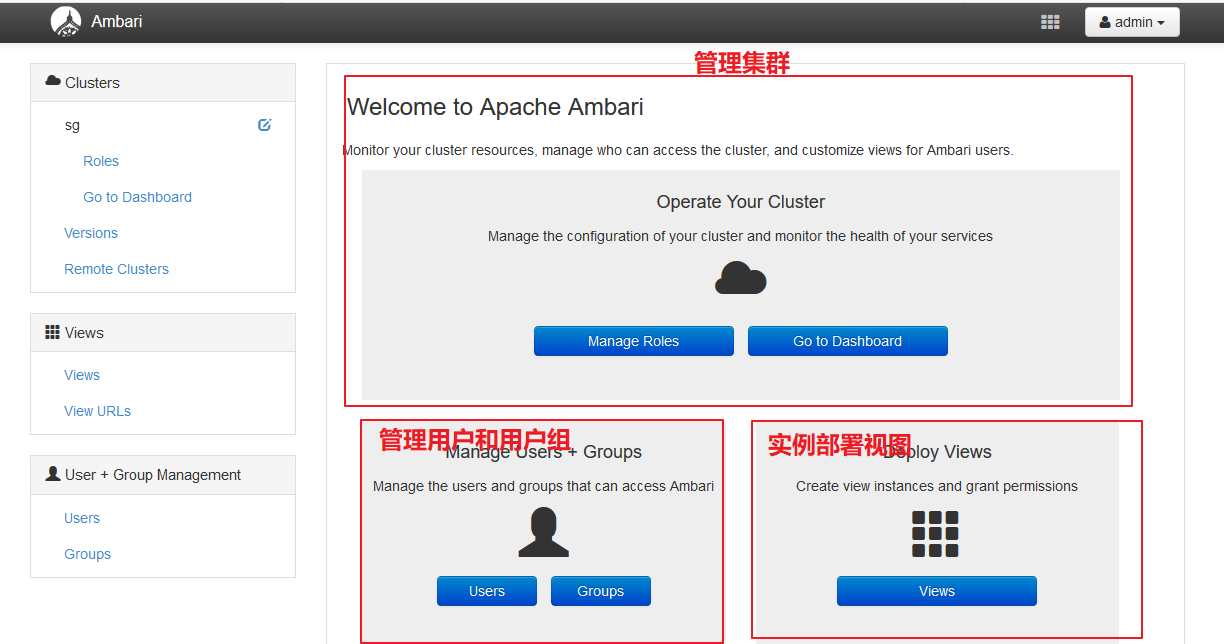
总体界面:
【自定义页面管理】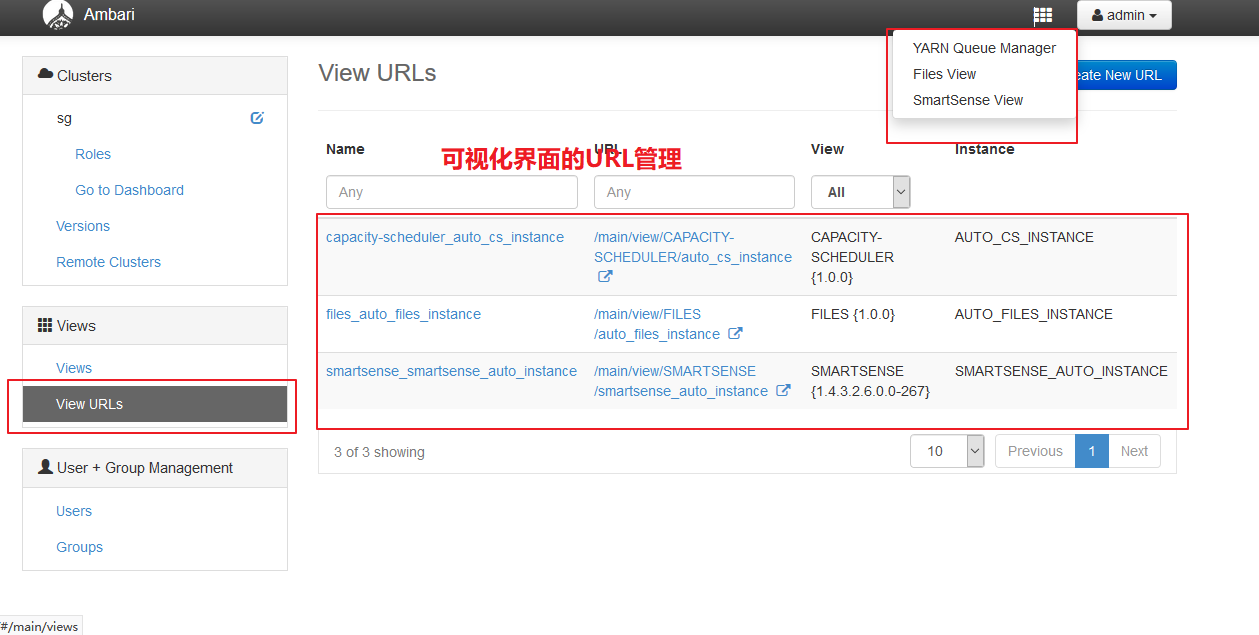
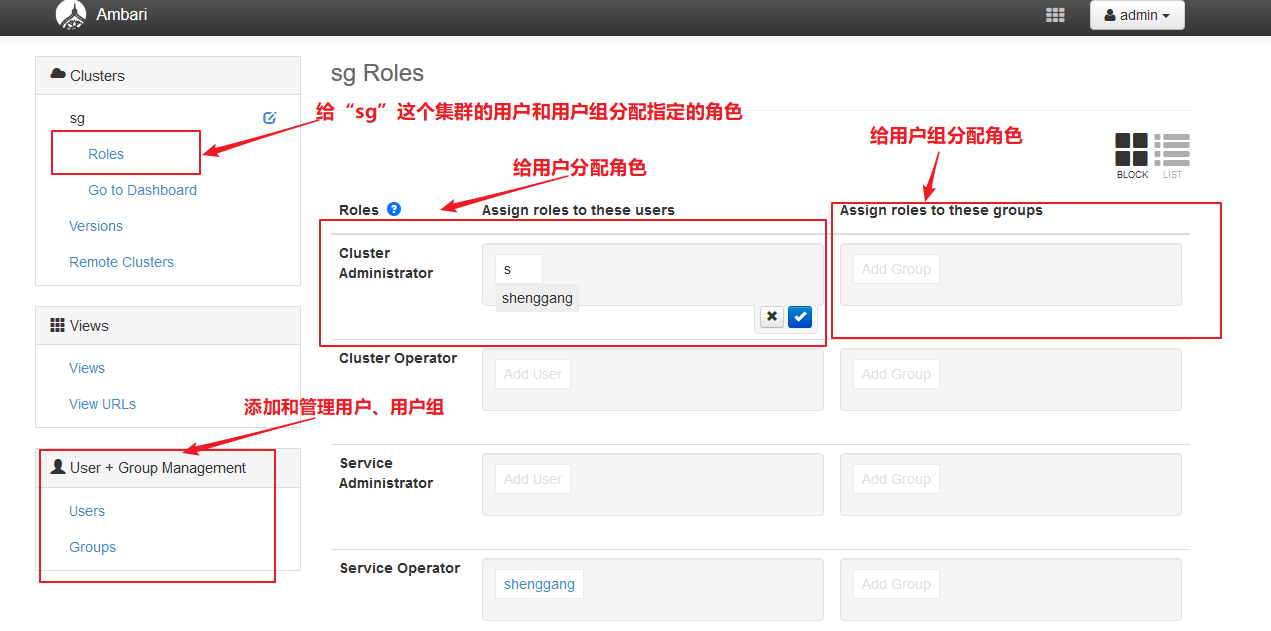
【用户和用户组角色分配】
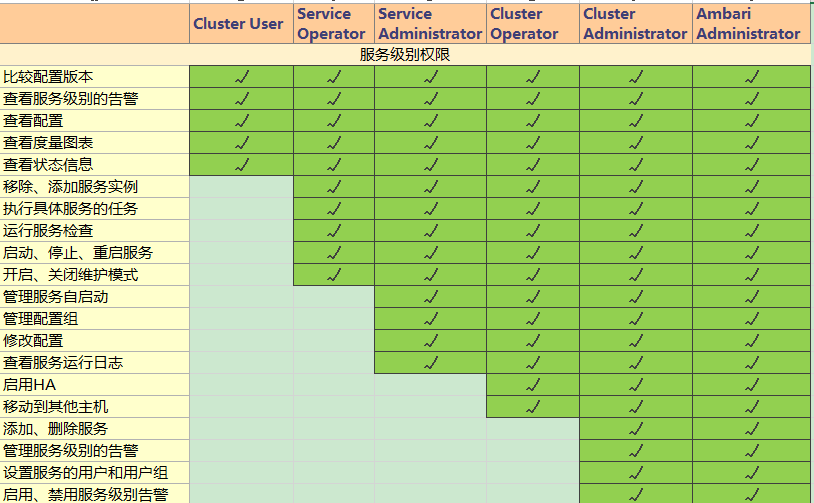
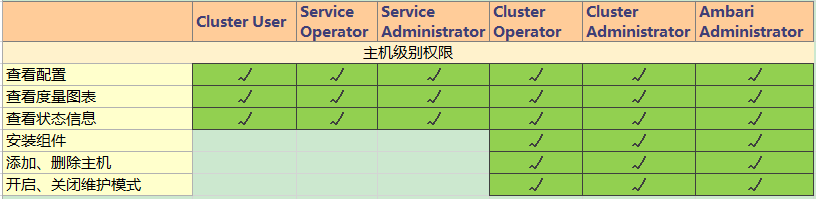
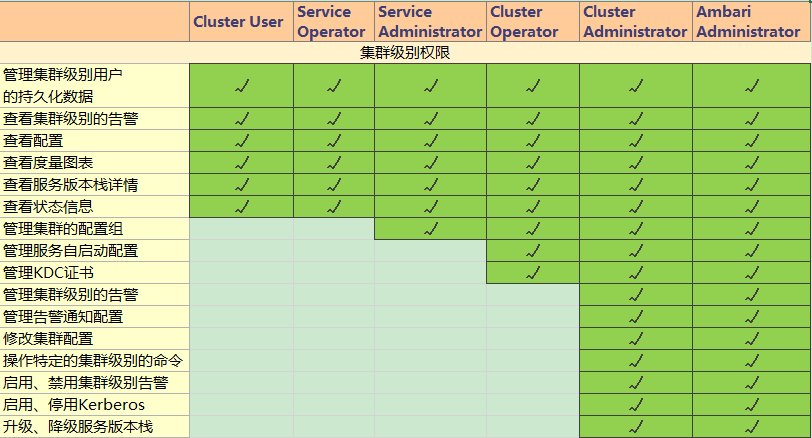
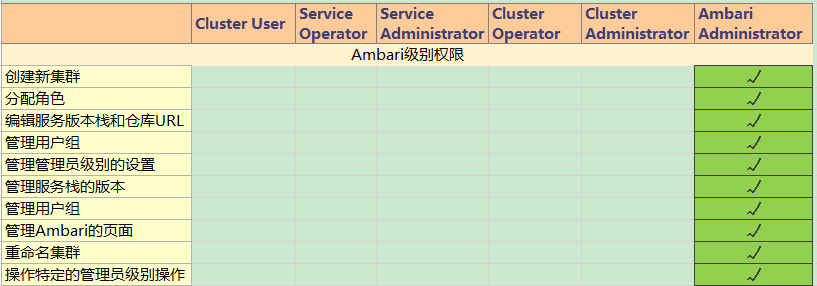
【角色权限列表】
七、扩展页面
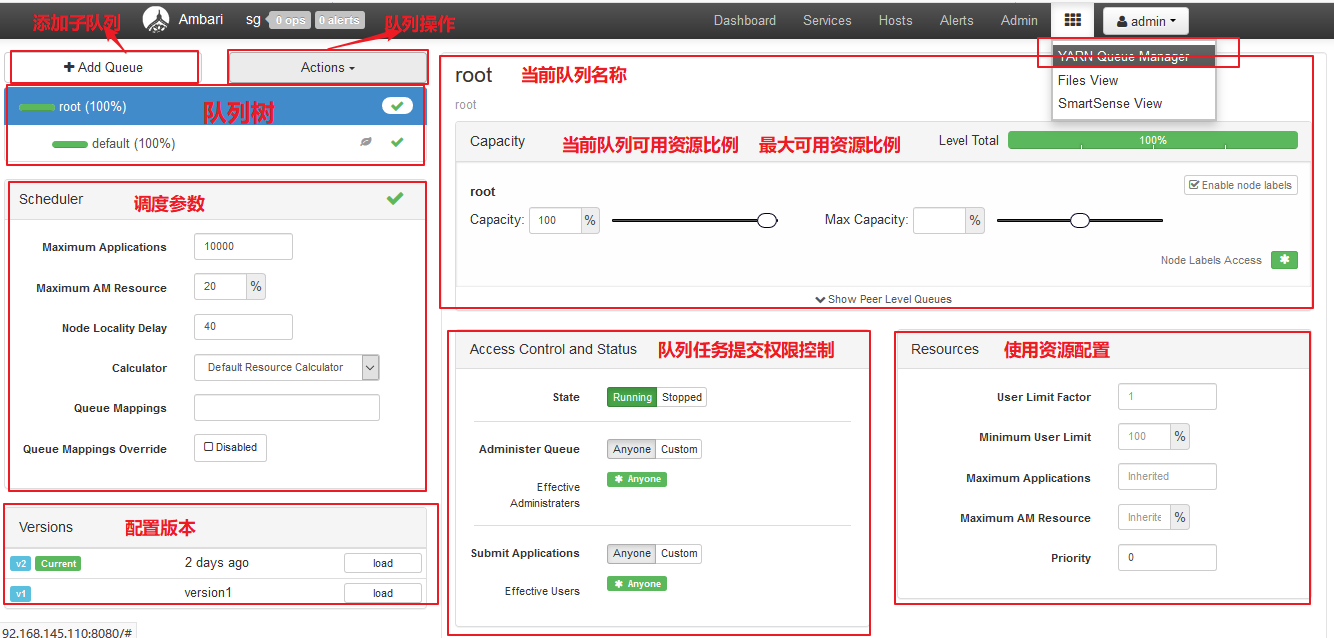
【Yarn队列管理】
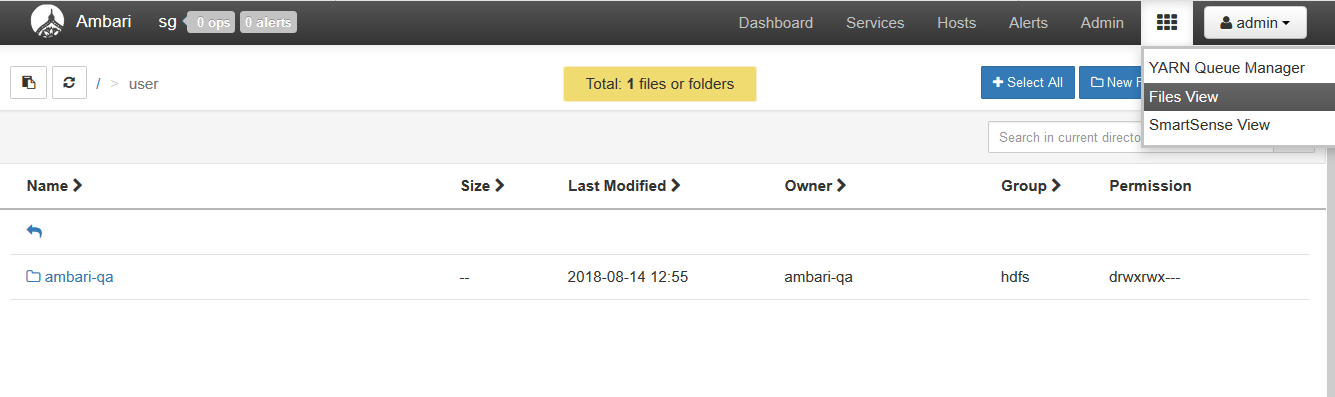
【HDFS】文件管理
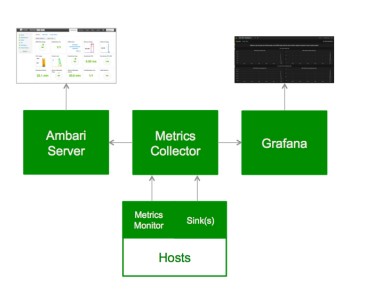
七、AMS(Ambari Metrics System)
AMS包括4个部分:
Metrics Monitors:在各个节点中收集系统级别的度量参数,然后推送给Metrics Collector。
Hadoop Sinks:内嵌在Hadoop的各个组件中,将Hadoop的度量参数推送给Metrics Collector。
Metrics Collector:一个守护进程,运行在特定的节点中,用来接收已经注册的“Publisher”的数据。
Grafana:开源的度量分析和可视化套件。数据源为Collector。

【AMS架构图】
【访问Grafana界面】
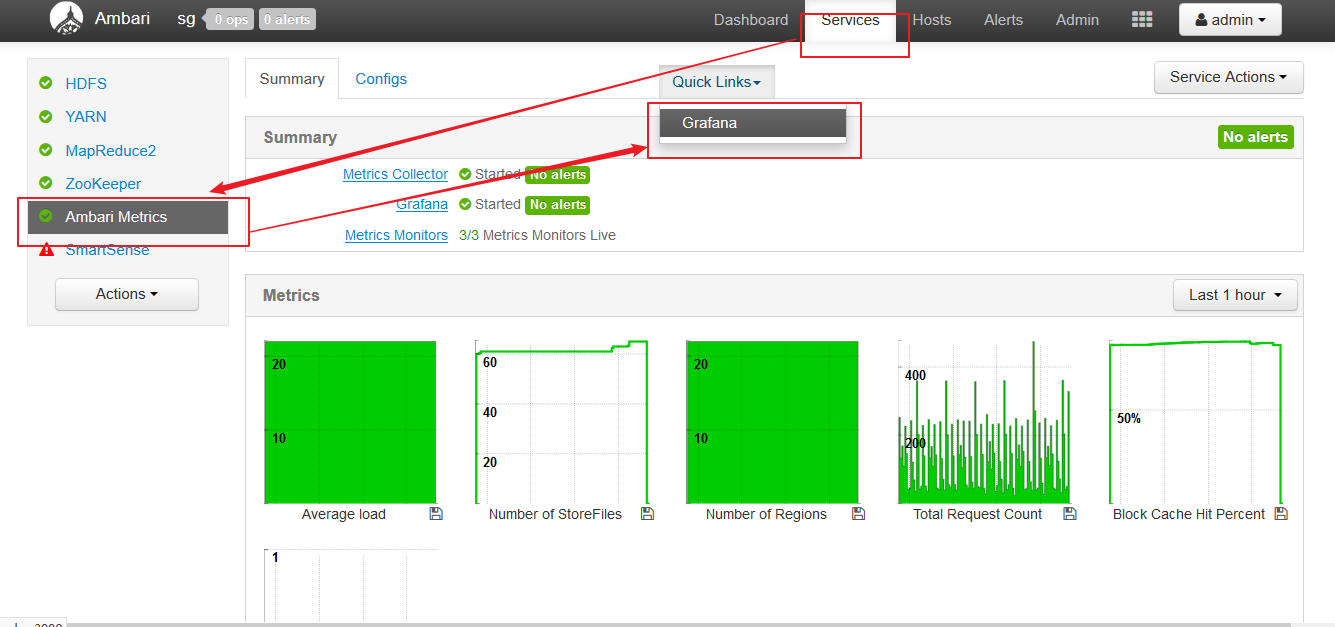
默认端口号是3000。
【Grafana简单操作】