利用DM工具Weka进行数据挖掘(分类)的完整过程:
(有关Weka的使用详见:ML 与 DM 工具 Weka 的使用)
0 问题背景
- 任务:根据给定数据集创建分类器。
- 训练数据集:100 predictive attributes A1,…,A100和一个类标C。每一个属性是介于0-1之间的浮点数。类标C有三个可能的值{0,1,2}。给定的数据文件有101列,6270行。
- 测试数据集:100 predictive attributes A1,…,A100 ,每一个属性是介于0-1之间的浮点数。给定的数据文件有10列,500行。
训练数据如下图所示:
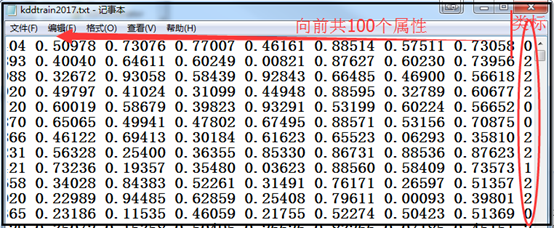
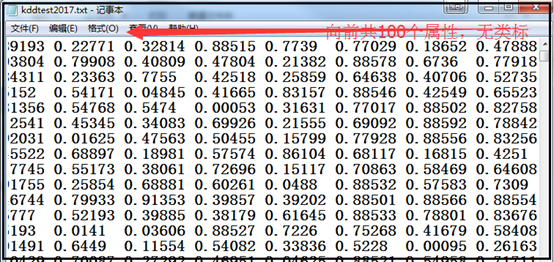
测试数据如下图所示:
1 使用平台
Weka 3-8-1 + Eclipse
2 数据预处理
对于数据挖掘的数据预处理部分,一般有数据清理、数据集成、数据集成和数据规约等处理。由于实验提供的数据已经进行了归一化处理,不存在缺失值,异常值等情况,不需要进行数据清理和集成等工作。
(1)实验数据为txt格式,需要转换成weka支持的arff格式,利用Java编程实现简单的数据格式转换,具体代码见txt2arff.Java。


package dmtask1; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; public class txt2arff { public static void main(String[] args) { // TODO Auto-generated method stub try { BufferedReader br=new BufferedReader(new FileReader("./ExperimentalData/kddtest2017.txt")); // BufferedReader br=new BufferedReader(new FileReader("./ExperimentalData/kddtrain2017.txt")); String line=null; BufferedWriter bw=new BufferedWriter(new FileWriter("./ExperimentalData/kddtest2017.arff")); // BufferedWriter bw=new BufferedWriter(new FileWriter("./ExperimentalData/kddtrain2017.arff")); bw.write("@relation kddtest2017"); // bw.write("@relation kddtrain2017"); bw.newLine(); for(int i=0;i<100;i++){ bw.write("@attribute Feature"+i+" real"); bw.newLine(); } bw.write("@attribute class {0,1,2}"); bw.newLine(); bw.write("@data"); bw.newLine(); while((line=br.readLine() )!= null){ //------------------------test-- String[] str=line.split(" ");//test 文件是 分割 for(int i=0;i<str.length;i++){ bw.write(str[i]+","); } bw.write("?"); //------------------------test-- //------------------------train-- // String[] str=line.split(" ");//train 文件是空格分割 // for(int i=0;i<str.length;i++){ // if (i == 0){ // bw.write(str[i]); // } // else{ // bw.write(","+str[i]); // } // } //------------------------train-- bw.newLine(); } br.close(); bw.close(); System.out.println("OK! Finished!!"); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); }catch (IOException e) { // TODO: handle exception e.printStackTrace(); } } }
(2)实验数据具有100维度,应该会存在冗余特征,且数据都是数值型数据,因此考虑使用信息增益(InfoGainAttributeEval)的方法对数据进行降维处理。利用Java编程实现将数据分别降为10维度到100维度,共十组数据,具体代码见 DimenReductionByInfoGain.Java。(需要导入weka.jar包)
package dmtask1; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileReader; import java.io.FileWriter; import weka.attributeSelection.InfoGainAttributeEval; import weka.attributeSelection.Ranker; import weka.core.Instances; public class DimenReductionByInfoGain { public static void main(String[] args) { // TODO Auto-generated method stub try{ /* * 1.读入训练 */ BufferedReader br_train = new BufferedReader(new FileReader( "./ExperimentalData/kddtrain2017.arff")); Instances trainIns = new Instances(br_train); trainIns.setClassIndex(trainIns.numAttributes()-1); /* * 2.初始化搜索算法(search method)及属性评测算法(attribute evaluator) */ Ranker rank = new Ranker(); InfoGainAttributeEval eval = new InfoGainAttributeEval(); /* * 3.根据评测算法评测各个属性 */ eval.buildEvaluator(trainIns); /* * 4.按照特定搜索算法对属性进行筛选 * 在这里使用的Ranker算法仅仅是属性按照InfoGain的大小进行排序 */ for(int k = 0; k < 10; k ++){ String name="./ExperimentalData/kddtrain2017_"; name += (k+1)*10; name += ".arff"; BufferedWriter bw_train = new BufferedWriter(new FileWriter(name)); rank.setNumToSelect((k+1)*10); int[] attrIndex = rank.search(eval, trainIns); // 训练文件降维 bw_train.write("@relation kddtrain2017_"+(k+1)*10); bw_train.newLine(); for (int i = 0; i < (k+1)*10; i++) { bw_train.write("@attribute Feature" + attrIndex[i] + " real"); bw_train.newLine(); } bw_train.write("@attribute class {0,1,2}"); bw_train.newLine(); bw_train.write("@data"); bw_train.newLine(); br_train.close(); br_train = new BufferedReader(new FileReader("./ExperimentalData/kddtrain2017.arff")); String line = br_train.readLine(); while (line.startsWith("@")) { line = br_train.readLine(); } while (line != null) { String str[] = line.split(" "); for (int i = 0; i < (k+1)*10; i++) { bw_train.write(str[attrIndex[i]] + ","); } bw_train.write(str[str.length - 1]); bw_train.newLine(); line = br_train.readLine(); } bw_train.close(); } System.out.println("OK"); }catch(Exception e){ e.printStackTrace(); } } }
3 数据训练(分类)
Weka已经提供了良好的分类器接口,首先我们直接使用Weka内置的一些常用的分类器进行训练集的分类训练。
执行步骤:
(1)启动Weka,选择 Explorer 应用,在 Preprocess 选项卡点击 open file :选择../ kddtrain2017.arff
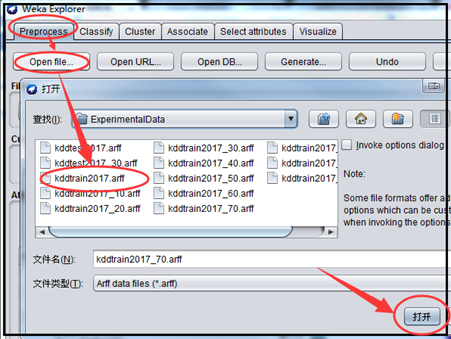
(2)打开Classify选项卡,在Classifier中选择分类器;在Test options 中选择评价模型效果的方法,在此选择Cross-validation,Folds填10 即进行十重交叉验证。选择好后点击start进行分类实验,在Classifier output中显示分类器的输出结果。
下表给出训练数据在10个不同维度的12个基分类器下的十重交叉验证的结果:
表1 训练数据在10个不同维度的12个基分类器下的十重交叉验证精确率
|
Dimension Classifies |
100 |
90 |
80 |
70 |
60 |
50 |
40 |
30 |
20 |
10 |
|
|
bayes. |
BayesNet |
0.888 |
0.888 |
0.888 |
0.888 |
0.888 |
0.888 |
0.888 |
0.889 |
0.885 |
0.863 |
|
NaiveBayes |
0.738 |
0.738 |
0.740 |
0.738 |
0.740 |
0.741 |
0.741 |
0.748 |
0.769 |
0.704 |
|
|
functions. |
Logistic |
0.767 |
0.768 |
0.770 |
0.772 |
0.772 |
0.775 |
0.778 |
0.779 |
0.770 |
0.606 |
|
SMO jiu |
0.787 |
0.790 |
0.792 |
0.792 |
0.794 |
0.794 |
0.794 |
0.797 |
0.783 |
0.650 |
|
|
lazy. |
IB1 |
0.825 |
0.841 |
0.870 |
0.892 |
0.916 |
0.938 |
0.975 |
0.996 |
0.994 |
0.985 |
|
meta. |
Bagging |
0.974 |
0.974 |
0.975 |
0.975 |
0.975 |
0.975 |
0.975 |
0.975 |
0.973 |
0.961 |
|
Logitboost |
0.913 |
0.913 |
0.913 |
0.913 |
0.913 |
0.913 |
0.913 |
0.913 |
0.912 |
0.892 |
|
|
rules. |
DecisionTable |
0.844 |
0.844 |
0.844 |
0.844 |
0.844 |
0.844 |
0.844 |
0.848 |
0.848 |
0.843 |
|
JRip |
0.966 |
0.964 |
0.971 |
0.970 |
0.970 |
0.968 |
0.966 |
0.968 |
0.961 |
0.953 |
|
|
trees. |
J48 |
0.967 |
0.967 |
0.967 |
0.966 |
0.966 |
0.966 |
0.966 |
0.967 |
0.967 |
0.959 |
|
RandomForest |
0.989 |
0.990 |
0.989 |
0.990 |
0.990 |
0.990 |
0.990 |
0.990 |
0.988 |
0.980 |
|
|
RandomTree |
0.928 |
0.934 |
0.937 |
0.946 |
0.944 |
0.953 |
0.959 |
0.953 |
0.954 |
0.953 |
|
|
|
REPTree |
0.957 |
0.957 |
0.957 |
0.957 |
0.957 |
0.957 |
0.957 |
0.958 |
0.956 |
0.949 |
由上表看出,降维处理后的数据,大多数分类器在30维的时候达到了最好效果,IB1可以达到99.6%的准确率。由此可以看出数据中有些属性属于冗余属性,影响分类效果。
选出的前30维特征为:(62,67,28,23,81,74,51,22,44,19,53,84,50,25,79,82,99,72,8,9,60,5,1,65,11,20,87,26,97,95)
(3)参数优化
鉴于数据在IBK降到30维时效果最好,我们在这个分类器上做以下参数优化,以下是k取不同值时IBK分类器的准确率:
表2 30维的训练数据集在k取不同值时IBK分类器的准确率
|
k |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
precision |
0.996 |
0.995 |
0.996 |
0.995 |
0.995 |
0.995 |
0.995 |
由上表可知,当k=1与3时,准确率最高。
4 数据测试
根据上述结果,我们最终决定采取IB1分类器在30维数据上建立模型并对将为后的测试集进行预测,预测结果存储在TestResult.txt,具体代码见dmTest.Java。(需要导入weka.jar包)
package dmtask1; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import weka.attributeSelection.InfoGainAttributeEval; import weka.attributeSelection.Ranker; import weka.classifiers.Classifier; import weka.classifiers.Evaluation; import weka.classifiers.lazy.IB1; import weka.core.Instances; public class dmTest { public static void main(String[] args) { // TODO Auto-generated method stub try { BufferedReader br_train = new BufferedReader(new FileReader( "./ExperimentalData/kddtrain2017.arff")); BufferedWriter bw_train = new BufferedWriter(new FileWriter( "./ExperimentalData/kddtrain2017_30.arff")); BufferedReader br_test = new BufferedReader(new FileReader( "./ExperimentalData/kddtest2017.arff")); BufferedWriter bw_test = new BufferedWriter(new FileWriter( "./ExperimentalData/kddtest2017_30.arff")); // // 1.载入文件 Instances trainIns = new Instances(br_train); trainIns.setClassIndex(trainIns.numAttributes() - 1); Instances testIns = new Instances(br_test); testIns.setClassIndex(testIns.numAttributes() - 1); // 2.初始化搜索算法(search method)及属性评测算法(attribute evaluator) Ranker rank = new Ranker(); InfoGainAttributeEval eval = new InfoGainAttributeEval(); // 3.根据评测算法评测各个属性 eval.buildEvaluator(trainIns); // System.out.println(rank.search(eval,trainIns)); // 4.按照特定搜索算法对属性进行筛选 // 在这里使用的Ranker算法仅仅是属性按照InfoGain的大小进行排序,取前num个属性 int num = 30; rank.setNumToSelect(num); int[] attrIndex = rank.search(eval, trainIns); // 训练文件降维 bw_train.write("@relation kddtrain2017_30"); bw_train.newLine(); for (int i = 0; i < num; i++) { bw_train.write("@attribute Feature" + attrIndex[i] + " real"); bw_train.newLine(); } bw_train.write("@attribute class {0,1,2}"); bw_train.newLine(); bw_train.write("@data"); bw_train.newLine(); br_train.close(); br_train = new BufferedReader(new FileReader("./ExperimentalData/kddtrain2017.arff")); String line = br_train.readLine(); while (line.startsWith("@")) { line = br_train.readLine(); } while (line != null) { String str[] = line.split(" "); for (int i = 0; i < num; i++) { bw_train.write(str[attrIndex[i]] + ","); } bw_train.write(str[str.length - 1]); bw_train.newLine(); line = br_train.readLine(); } // 测试文件降维 bw_test.write("@relation kddtrain2017_30"); bw_test.newLine(); for (int i = 0; i < num; i++) { bw_test.write("@attribute Feature" + attrIndex[i] + " real"); bw_test.newLine(); } bw_test.write("@attribute class {0,1,2}"); bw_test.newLine(); bw_test.write("@data"); bw_test.newLine(); br_test.close(); br_test = new BufferedReader(new FileReader("./ExperimentalData/kddtest2017.arff")); line = br_test.readLine(); while (line.startsWith("@")) { line = br_test.readLine(); } while (line != null) { String str[] = line.split(","); System.out.println(); for (int i = 0; i < num; i++) { bw_test.write(str[attrIndex[i]] + ","); } bw_test.write(str[str.length - 1]); bw_test.newLine(); line = br_test.readLine(); } br_test.close(); br_train.close(); bw_test.close(); bw_train.close(); System.out.println("OK"); //输出选择的维度 for (int i = 0; i < num; i++) { System.out.print(attrIndex[i] + ","); } // 训练数据 br_train = new BufferedReader(new FileReader( "./ExperimentalData/kddtrain2017_30.arff")); br_test = new BufferedReader(new FileReader( "./ExperimentalData/kddtest2017_30.arff")); trainIns = new Instances(br_train); trainIns.setClassIndex(trainIns.numAttributes() - 1); testIns = new Instances(br_test); testIns.setClassIndex(testIns.numAttributes() - 1); //采用IB1分类器 Classifier cfs1 = new IB1(); cfs1.buildClassifier(trainIns); Evaluation testingEvaluation = new Evaluation(testIns); int length = testIns.numInstances(); for (int i = 0; i < length; i++) { testingEvaluation.evaluateModelOnceAndRecordPrediction(cfs1, testIns.instance(i)); } File writename = new File("./TestResult.txt"); writename.createNewFile(); // 创建新文件 BufferedWriter out = new BufferedWriter(new FileWriter(writename)); for (int i = 0; i < length; i++) { out.write((int) cfs1.classifyInstance(testIns.instance(i)) + " "); } br_test.close(); br_train.close(); out.close(); System.out.println("OK"); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
测试结果,即TestResult.txt文件内容:

至此,Java 的文件结构为:
关于IB1,是IB Instance-Based的缩写, KNN是Instance-based learning(也被称为Lazing learning)中一种。所以IBk使用的算法其实是KNN。KNN 算法的思路非常简单直观:如果一个样本在特征空间中的 k 个最相似 ( 即特征空间中最邻近 ) 的样本中的大多数属于某一个类别,则该样本也属于这个类别。其基本原理是在测试样本到达的时候寻找到测试样本的 k 临近的样本,然后选择这些邻居样本的类别最集中的一种作为测试样本的类别。IB1中就只找一个邻居。IBk中的k则是用来设定邻居数目的。这类的分类算法可以根据每个测试样本的样本信息来学习模型,这样的学习模型可能更好的拟合局部的样本特性。
5 总结
通过本次实验,使我对如何在weka中进行分类分析以及其中的一些分类算法有了更多的了解。并且通过学习,对数据挖掘的一般流程和一些经典的算法也有了进一步的理解,可能我选择的方法存在过拟合,但根据实践经验适当的过拟合是要好于欠拟合的。由于我选择的是一个分类器进行分类,在后面的学习中,会进一步学习研究下集成分类器的效果。
GitHub地址:
https://github.com/shenxiaolinZERO/PracticeOf0/tree/master/DMTask1