实例解析 - 小说爬虫
页面分析
共有三级页面
一级页面 大目录
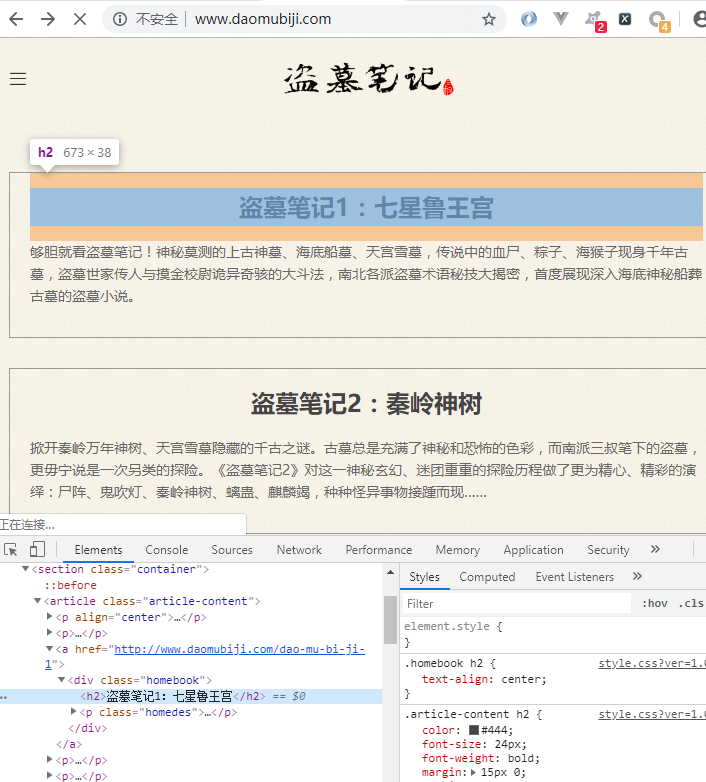
二级页面 章节目录
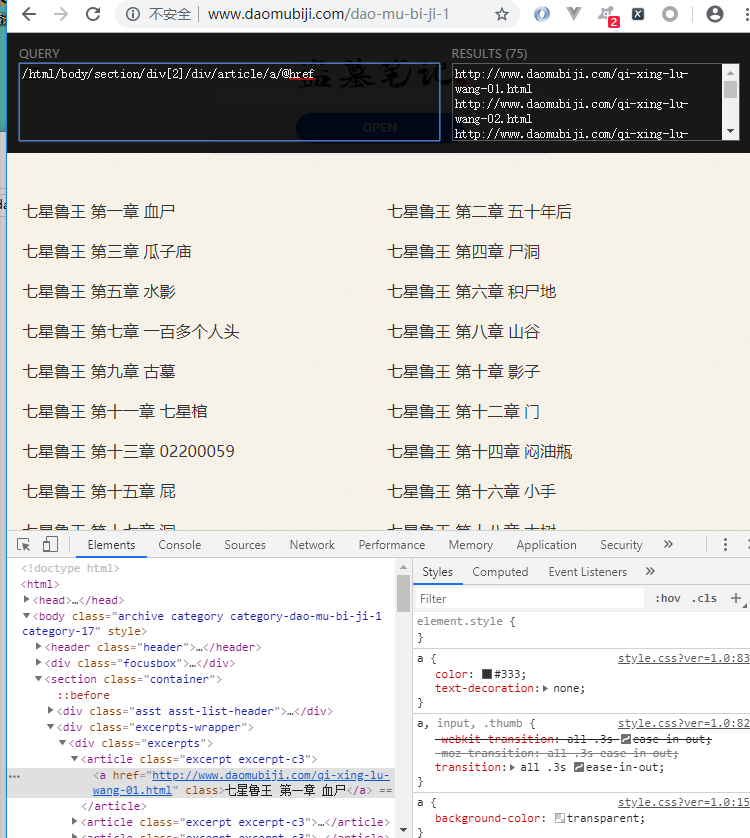
三级界面 章节内容
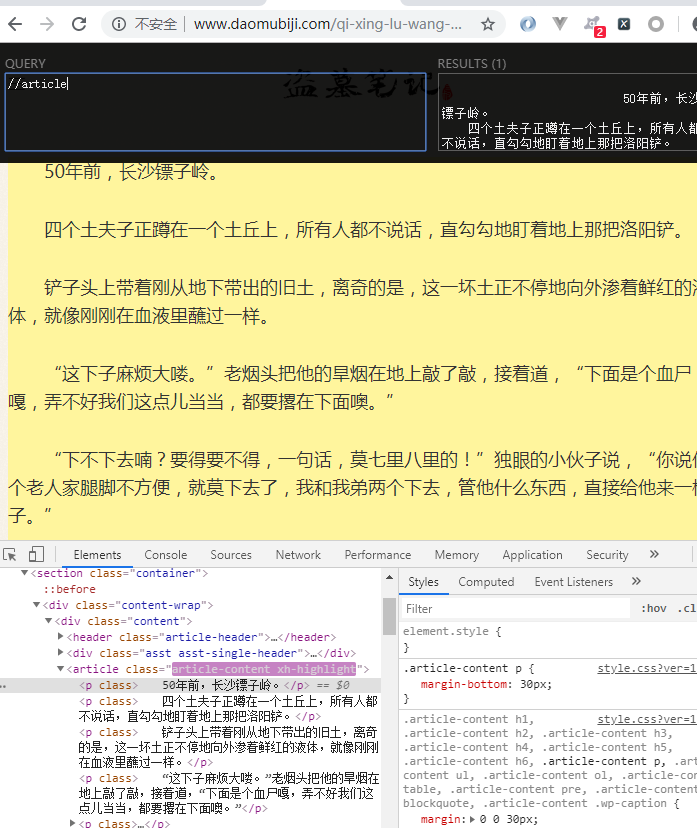
爬取准备
一级界面
http://www.daomubiji.com/
二级页面xpath
直接复制的 xpath
/html/body/section/article/a/@href
这里存在着反爬虫机制, 改变了页面结构
在返回的数据改变了页面结构, 需要换为下面的 xpath 才可以
//ul[@class="sub-menu"]/li/a/@href
三级页面xpath
//article
项目准备
begin.py
pycharm 启动文件,方便操作
from scrapy import cmdline cmdline.execute('scrapy crawl daomu --nolog'.split())
settings.py
相关的参数配置
BOT_NAME = 'Daomu'
SPIDER_MODULES = ['Daomu.spiders'] NEWSPIDER_MODULE = 'Daomu.spiders'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'WARNING'
DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36', }
ITEM_PIPELINES = { 'Daomu.pipelines.DaomuPipeline': 300, }
逻辑代码
items.py
指定相关期望数据
-*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class DaomuItem(scrapy.Item): # define the fields for your item here like: # 卷名 juan_name = scrapy.Field() # 章节数 zh_num = scrapy.Field() # 章节名 zh_name = scrapy.Field() # 章节链接 zh_link = scrapy.Field() # 小说内容 zh_content = scrapy.Field()
daomu.py
爬虫文件
# -*- coding: utf-8 -*- import scrapy from ..items import DaomuItem class DaomuSpider(scrapy.Spider): name = 'daomu' allowed_domains = ['www.daomubiji.com'] start_urls = ['http://www.daomubiji.com/'] # 解析一级页面,提取 盗墓笔记1 2 3 ... 链接 def parse(self, response): # print(response.text) one_link_list = response.xpath( '//ul[@class="sub-menu"]/li/a/@href' ).extract() # print('*' * 50) # print(one_link_list) # 把链接交给调度器入队列 for one_link in one_link_list: yield scrapy.Request( url=one_link, callback=self.parse_two_link ) # 解析二级页面 def parse_two_link(self, response): # 基准xpath,匹配所有章节对象列表 article_list = response.xpath('//article') # print(article_list) # 依次获取每个章节信息 for article in article_list: # 创建item对象 item = DaomuItem() info = article.xpath('./a/text()'). extract_first().split() print(info) # ['秦岭神树篇', '第一章', '老痒出狱'] item['juan_name'] = info[0] item['zh_num'] = info[1] item['zh_name'] = info[2] item['zh_link'] = article.xpath('./a/@href').extract_first() # 把章节链接交给调度器 yield scrapy.Request( url=item['zh_link'], # 把item传递到下一个解析函数 meta={'item': item}, callback=self.parse_three_link ) # 解析三级页面 def parse_three_link(self, response): item = response.meta['item'] # 获取小说内容 item['zh_content'] = ' '.join(response.xpath( '//article[@class="article-content"]' '//p/text()' ).extract()) yield item # ' '.join(['第一段','第二段','第三段'])
pipelines.py
持久化处理
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class DaomuPipeline(object): def process_item(self, item, spider): filename = 'downloads/{}-{}-{}.txt'.format( item['juan_name'], item['zh_num'], item['zh_name'] ) f = open(filename,'w') f.write(item['zh_content']) f.close() return item