搭建Hadoop
1.平台基本介绍
Hadoop的核心由3个部分组成:
HDFS: Hadoop Distributed File System,分布式文件系统,hdfs还可以再细分为NameNode、SecondaryNameNode、DataNode。
YARN: Yet Another Resource Negotiator,资源管理调度系统
Mapreduce:分布式运算框架
2.搭建Hadoop
-
Windows系统下利用VMware虚拟机,以及Xshell等进行平台搭建

-
镜像资源CentOS6.5(百度云盘)
-
利用VMware进行CentOS6.5系统安装(master)
-
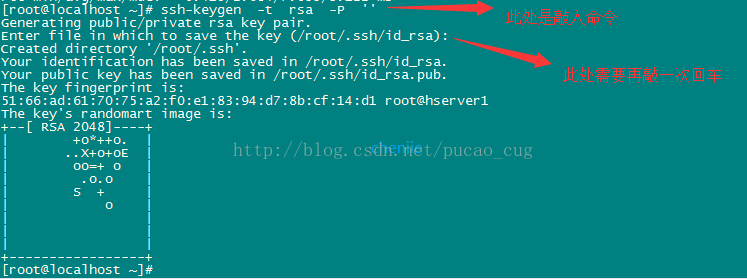
实现ssh免密登录
-
在终端中 ssh-keygen -t rsa -P ''
-
现在用的是root账户,所以秘钥文件保存到了/root/.ssh/目录内,可以使用命令查看,命令是ls /root/.ssh/
-
cat /root/.ssh/id_rsa.pub
依次复制master、slave1、slave2ssh密钥
-
touch /root/.ssh/authorized_keys
将复制的文件密钥粘贴到该文件中
依次在master、slave1、slave2执行操作
测试使用ssh进行免密登陆
3.安装jdk和hadoop
3.1进行jdk安装
- jdk版本:jdk-8u261-linux-x64.tar.gz,hadoop只支持jdk7和jdk8,不支持jdk11,下载百度云盘
-


-
利用xftp6进行文件传输、文件处理
-->在/opt目录下新建java文件夹
-->将百度云下载好的jdk-8u261-linux-x64.tar.gz传到java文件中
-->在Xshell中进行解压,命令:tar -zxvf jdk-8u261-linux-x64.tar.gz
-->解压完成后可删除jdk-8u261-linux-x64.tar.gz文件
-->修改/etc/profile添加如下内容:
export JAVA_HOME=/opt/java/jdk1.8.0_261 export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/ export PATH=$PATH:$JAVA_HOME/bin-->此时需要命令:java -version 查看jdk版本是否匹配(本次安装为如下版本)

-->版本一般不同,需要删出默认版本,依次使用如下命令:
rm -f /usr/bin/java rm -f /usr/bin/javac rm -f /etc/alternatives/java rm -f /etc/alternatives/javac-->删除后依次使用命令:
source /etc/profile java -version看到如下配置JDK成功
3.2进行Hadoop安装
-
在opt目录下新建一个名为hadoop的目录,并将hadoop-2.7.3.tar.gz上载到该目录下
-
在该目录下(cd /opt/hadoop)执行解压命令:tar -xvf hadoop-2.7.3.tar.gz
-
在/root目录下新建几个目录,复制粘贴执行下面的命令:
mkdir /root/hadoop mkdir /root/hadoop/tmp mkdir /root/hadoop/var mkdir /root/hadoop/dfs mkdir /root/hadoop/dfs/name mkdir /root/hadoop/dfs/data -
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop目录内的一系列文件,已改过百度云盘
-
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/core-site.xml文件
在节点内加入配置:
hadoop.tmp.dir
/root/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://master:9000
-
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/hadoop-env.sh文件
将export JAVA_HOME=${JAVA_HOME}
修改为:export JAVA_HOME=/opt/java/jdk1.8.0_261
-
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/hdfs-site.xml文件
在节点内加入配置:
dfs.name.dir
/root/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
dfs.data.dir
/root/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
dfs.replication
2
dfs.permissions
false
need not permissions
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
-
新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml
修改这个新建的mapred-site.xml文件,在节点内加入配置:
mapred.job.tracker
master:49001
mapred.local.dir
/root/hadoop/var
mapreduce.framework.name
yarn
-
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/slaves文件,将里面的localhost删除,添加如下内容:
master slave1 slave2 -
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/yarn-site.xml文件,
在节点内加入配置(注意了,内存根据机器配置越大越好,我这里只配2个G是因为机器不行):
yarn.resourcemanager.hostname
master
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
2048
每个节点可用内存,单位MB,默认8182MB
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.vmem-check-enabled
false
-
进行数据分发
在master上执行下列命令
scp -r /opt/hadoop/hadoop-2.7.3/ slave1:/opt/hadoop/ scp -r /opt/hadoop/hadoop-2.7.3/ slave2:/opt/hadoop/ -
检查防火墙状态:service iptables status
关闭防火墙:service iptables stop
永久关闭防火墙:chkconfig iptables off
-
-
3.启动Hadoop
-
在namenode上执行初始化
因为master是namenode,slave1和slave2都是datanode,所以只需要对master进行初始化操作,也就是对hdfs进行格式化。
进入到master这台机器的/opt/hadoop/hadoop-2.7.3/bin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.7.3/bin
执行初始化脚本,也就是执行命令:
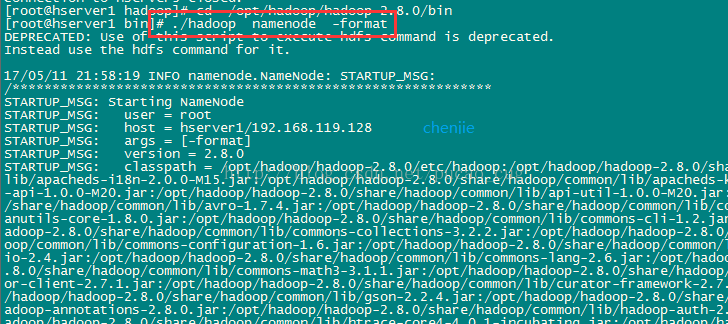
./hadoop namenode -format
如图:
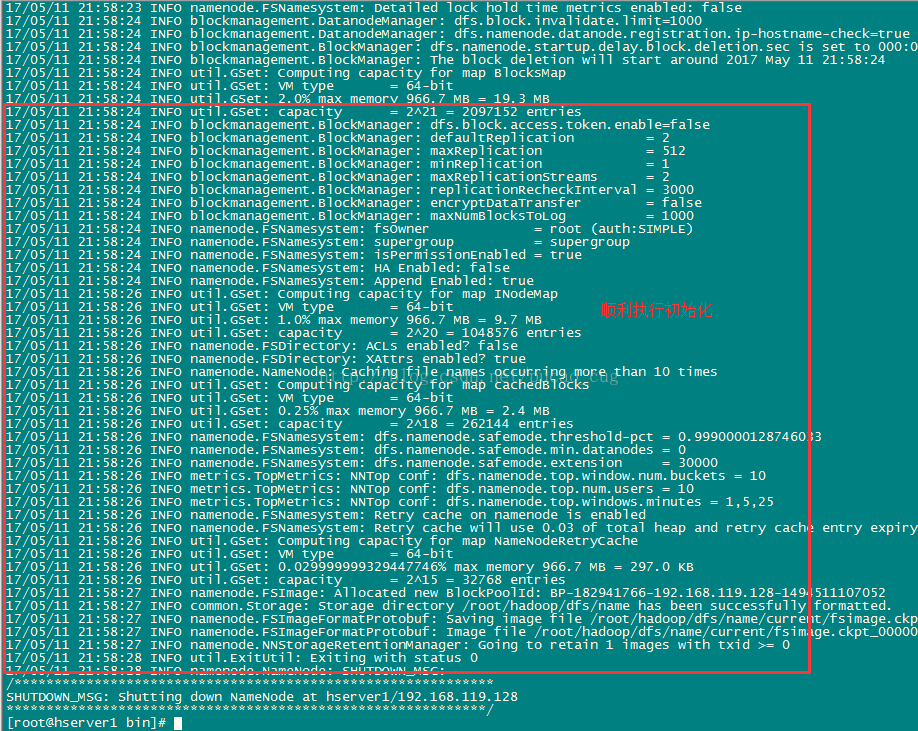
稍等几秒,不报错的话,即可执行成功,如图:
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件,如图:
-
-
在namenode上执行启动命令
因为master是namenode,slave1和slave2都是datanode,所以只需要再master上执行启动命令即可。
进入到master这台机器的/opt/hadoop/hadoop-2.7.3/sbin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.7.3/sbin
执行初始化脚本,也就是执行命令:
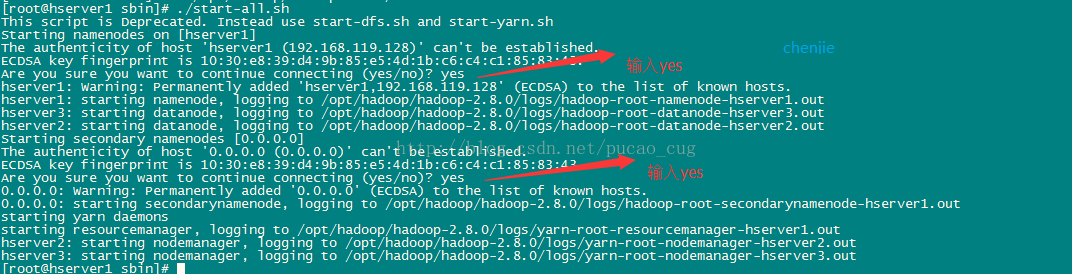
./start-all.sh
第一次执行上面的启动命令,会需要我们进行交互操作,在问答界面上输入yes回车,如图:
可以在master上按照如下代码启动(参考CSDN)
[root@master sbin]# ./hadoop-daemons.sh start journalnode
[root@master sbin]# cd ../bin
[root@master bin]# ./hadoop namenode -format
[root@master bin]# cd ../sbin/ [root@master sbin]# ./start-all.sh
-
使⽤jps命令查看是否启动成功
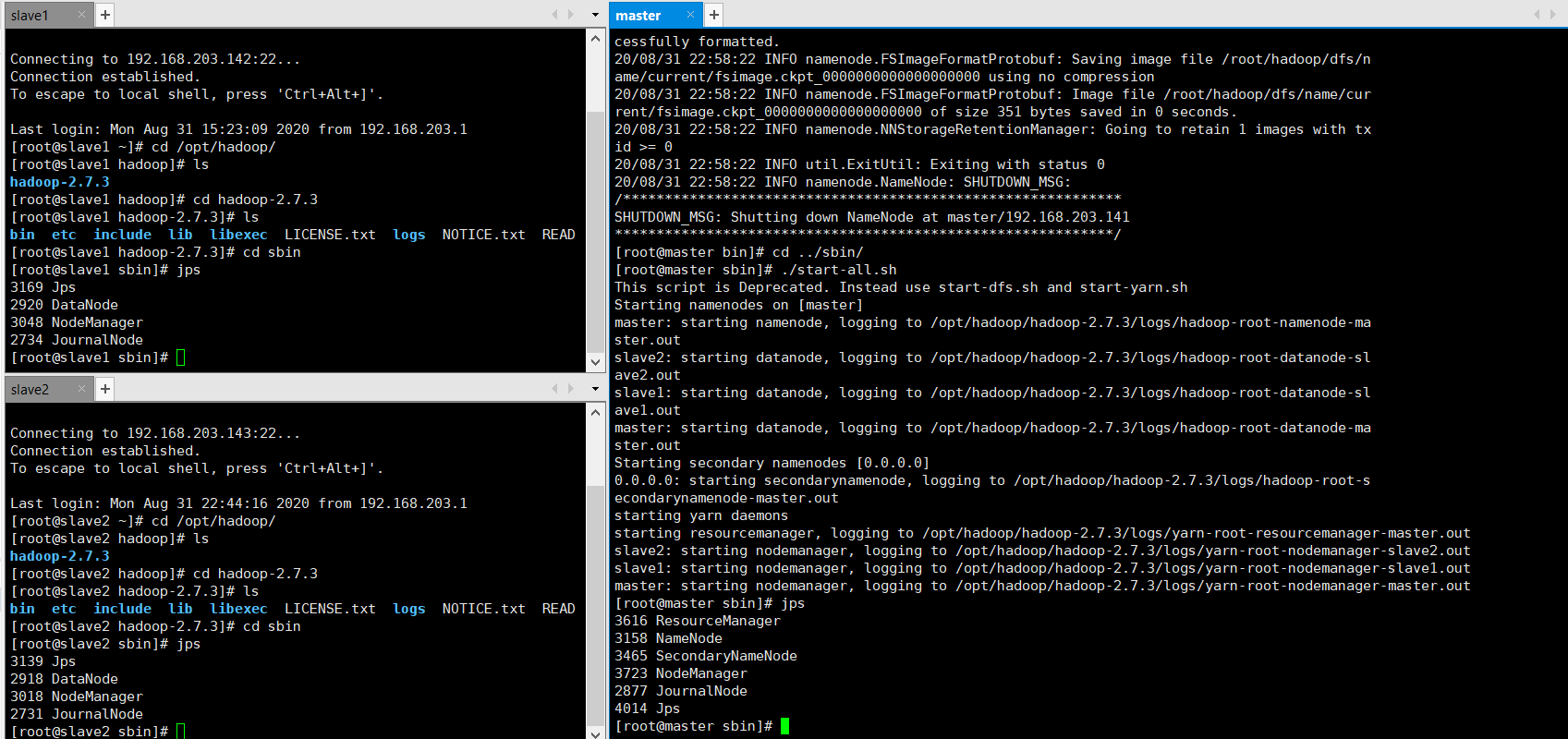
-
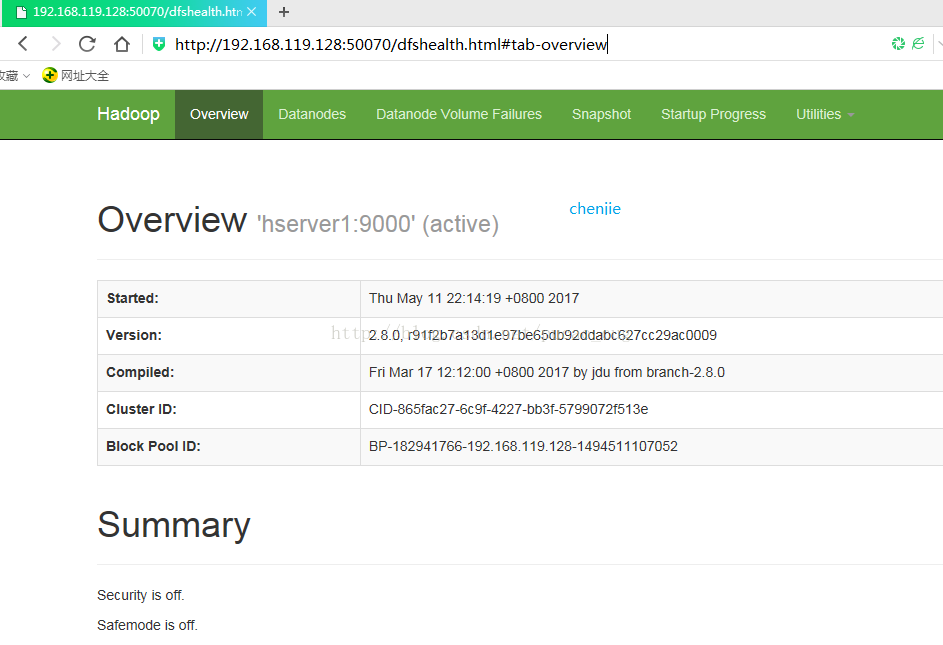
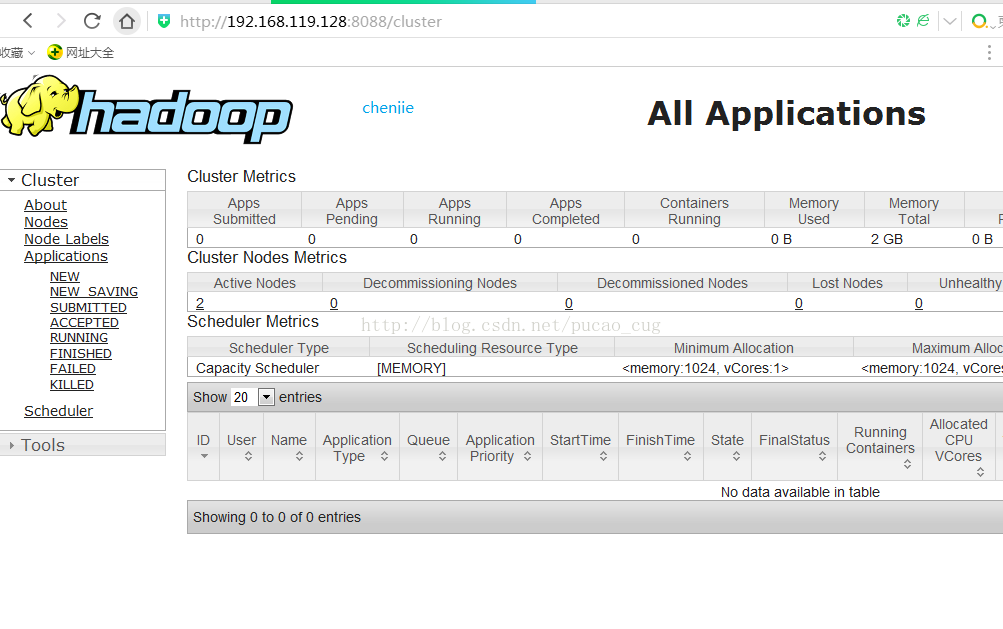
查看HDFS Web⻚⾯(ip为master的ip,可通过命令ifconfig查看)
-
查看YARN Web ⻚⾯