Hive数据仓库技术Hive 简介Hive与传统关系型数据库Hive 架构设计Hive数据单元数据存储模型安装配置 Hive 环境Metastore的三种运行模式Metastore 配置属性搭建Hive环境内置derby版外置MySQL版Hive数据库及表操作基本数据类型复杂数据类型Hive DDL 操作数据库操作创建表语法托管表(内部表)其他常用 DDL 操作Hive DML 操作数据装载与插入Hive 复杂类型的使用Hive 数据模型分区表分桶表外部表数据更新、删除和修改数据导入/导出Hive高级操作Select 语句Where 子句LIMIT 字句排序分组基础聚合函数
Hive 简介
Hadoop 中的 MapReduce 计算模型能将计算任务切分为多个小单元,然后分布到各个节点上去执行,从而降低计算成本并提高扩展性。但是使用MapReduce 进行数据处理的门槛较高,传统的数据库开发、管理和运维的人员必须掌握 Java 面向 MapReduce API 编程并具备一定的编程基础后,才能使用 MapReduce 处理数据。
而Hive 是基于 Hadoop的一个数据仓库工具,可以将**类SQL语句**转换为 **MapReduce任务**进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 任务,不必开发专门的MapReduce 应用。Hive 也是为消除 MapReduce 样板式的编程而产生的。
Hive与传统关系型数据库
相同点:
Hive与传统关系型数据库(Relational Database Management System,RDBMS)有很多相同的地方,包括查询语言与数据存储模型等。Hive 的 SQL 方言一般被称为 HiveQL,简称 HQL。HQL并不完全遵循 SQL92 标准,比如 HQL 只支持在 From 字句中使用子查询,并且子查询必须有名字。最重要的时,HQL 必须在 Hadoop 上执行,而非传统的数据库。在存储方面,数据库、表概念都是相同的,但 Hive 中增加了分区和分桶的概念。
不同点:
在 RDBMS 中,表的 Schema 是在数据加载时就已确定,如果不符合 Schema 则会加载失败;而 Hive 在加载过程中不对数据进行任何验证,只是简单地将数据复制或者移动到表对应的目录下。这也是 Hive 能够支持大规模数据的基础之一。
Hive 具有 SQL 数据库的很多类似功能,但应用场景完全不同,通常 RDBMS 可以用于在线应用中,而 Hive 主要进行离线的大数据分析。
Hive 架构设计
Hive 架构包含 3 个部分:Hive Client 、Hive Service 、Hive Store and Computing。
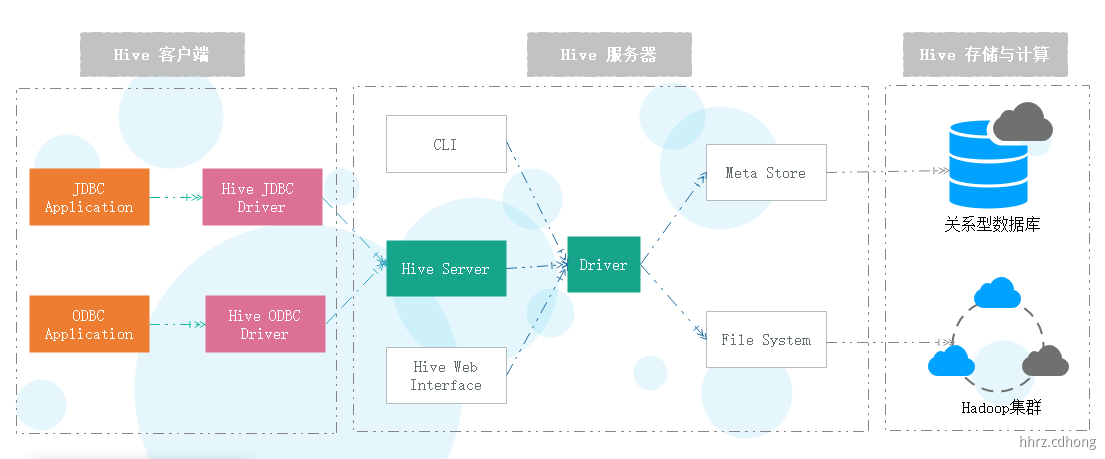
-
Hive 客户端。Hive为不同类型应用程序提供了不同的驱动,使应用程序可通过 Java、Python 等语言连接 Hive 并进行与 RDBMS 类似的 SQL 查询操作。对于 Java 应用程序,Hive提供了 JDBC 驱动,对于其它应用程序,Hive 提供了 ODBC驱动。 -
Hive 服务器。客户端必须通过服务端与 Hive 交互。
-
-
CLI:控制台命令行方式。
-
Hive Server:包括 Hive Server1 和 Hive Server2两种,其中 Hive Server1 在新版本中被删除。Hive Server2 支持一个新的命令行 Shell,其称为 Beeline。
Beeline 是一个命令行形式的 JDBC 客户端,用于连接 Hive Server2,连接端口默认是:10000。 -
HWI(Hive Web Interface):通过浏览器访问Hive。
-
Driver:该组件包括编译器(Compiler)、优化器(Optimizer)和执行引擎(Executor),它的作用是将 HQL 语句镜像解析、编译优化,并生成执行计划,最后调用底层的 MapReduce 计算框架。
-
MetaStore: Hive中的数据分为两部分,一部分是真实数据,一般存放在 HDFS 中,另一部分是真实数据的元数据,单独存储在关系型数据库中,如 Derby、MySQL等。
元数据用于存储Hive中的数据库、表、表模式、目录、分区、索引以及命名空间等信息,是对真实数据的描述。元数据会不断更新编号,所以不适合存储在HDFS 中。
-
-
Hive 存储与计算。 Hive 主要通过元数据存储数据库和Hadoop 集群进行数据的存储与计算。Hive 的元数据使用 RDBMS存储,Hive 的数据存储在 HDFS中,大**部分数据查询由 MapReduce 完成**。
Hive数据单元
Hive所有真实数据都存储在HDFS中,这样更有利于对数据做分布式计算。为了有效地对真实数据进行管理,根据粒度大小,Hive将真实数划分为如下数据单元。
-
数据库:数据库类似于 RDBMS 中的数据库,在HDFS中表现为hive.metastore.warehourse.dir目录下的一个文件夹,其本质是用于避免表、视图、分区、列等命名冲突的命名空间。 -
表:表在HDFS中表现为所属数据库目录下的子目录,具体又分为内部表和外部表。 -
-
内部表类似于 RDBMS中的表,由Hive管理,即当删除一张内部表时,元数据以及HDFS上的真实数据均被删除。
-
外部表指向已经存在 HDFS 中的数据,与内部表元数据组织是相同的,但其数据存放位置是任意的。外部表真实数据不被Hive管理,即删除外部表则只会删除元数据而不是删除真实数据。
-
-
分区:每个表都可以按指定的键分为多个分区(Partitions)。分区的作用是提高查询的效率,其在HDFS中表现为表目录下的子目录。 -
分桶:根据表中某一列的哈希值可将数据划分为多个同(Buckets),在HDFS中分桶表现为同一目录下根据哈希散列之后的多个文件。** **
数据存储模型
按照数据单元的划分结果,Hive数据在 HDFS 的典型存储结果中表现为以下形式。
假设数据仓库地址 hive.metastore.warehouse.dir 为 “/user/hive/warehouse”,则可知如下内容:
-
/user/hive/warehourse表示 Hive 自带的 “default”数据库设置。 -
/user/hive/warehourse/demo.db表示数据仓库中存在“demo”数据库。 -
/user/hive/warehourse/demo.db/users表示 demo 数据库中存在 users 表。 -
/user/hive/warehourse/demo.db/users/000000_....为 demo 中 users 表里的数据文件。 -
/user/hive/warehourse/demo.db/orders/year=2018/part-0000....表示 demo 中 order 表里的数据按照年份进行分区,这里显示的是分区 year=2018 下的数据文件。
安装配置 Hive 环境
Metastore的三种运行模式
安装Hive前,先了解Metastore的三种运行模式,分别是:Embedded(嵌入)、Local(本地)、Remote(远程)。
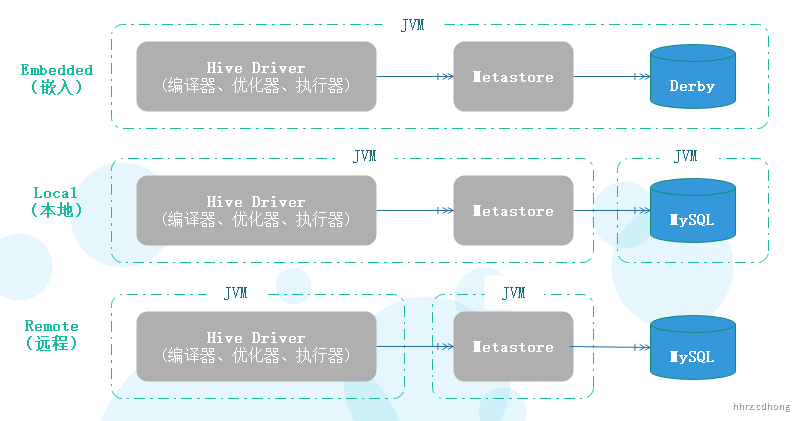
第一种是嵌入模式,它的最大的特点是,内嵌了Derby数据库,Hive Driver、Metastore、Derby三个组件在一个独立JAVA虚拟机(JVM),也即一个独立进程中运行。但这个模式有个缺点:不同路径启动 hive ,每一个 hive 拥有一套自己的元数据,无法共享。
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则会提示如下错误:
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
第二种是本地模式,它可以采用独立的数据库,比如MySQL,目前它对MySQL支持是最好的,其他数据库,比如Oracle支持还不是很好。另外,Driver和Metastore在同一个JVM中运行。
第三种是远程模式,这种模式下,Metastore单独部署,多个Hive Driver共享这个Metastore。
Metastore 配置属性
Hive核心配置文件 hive-site.xml 相关属性
| 属性名称 | 描述 |
|---|---|
hive.metastore.warehouse.dir |
配置仓库存放目录,/usr/hive/warehouse |
javax.jdo.option.ConnectionURL |
JDBC连接地址,jdbc:derby:;databaseName=metastore_db;create=true |
javax.jdo.option.ConnectionDriverName |
JDBC驱动器的类名,org.apache.derby.jdbc.EmbeddedDriver |
javax.jdo.option.ConnectionUserName |
JDBC用户名,APP |
javax.jdo.option.ConnectionPassword |
JDBC密码,mine |
hive.cli.print.header |
查询时显示表头信息,false |
hive.cli.print.current.db |
显示当前使用的数据库名称,false |
搭建Hive环境
从
内置derby版
-
解压 Hive 安装包
[root@node01 local]# tar -zxvf apache-hive-1.2.1-bin.tar.gz
[root@node01 local]# ln -s apache-hive-1.2.1-bin hive
-
配置
conf/hive-env.sh**文件中的 HADOOP_HOME**
[root@node01 conf]# cp hive-env.sh.template hive-env.sh
[root@node01 conf]# vim hive-env.sh
export HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
-
进入 Hive 解压目录,**运行**
bin/hive启动**,初始化**hive自带的内存数据库derby -
测试创建一个数据库
wise_db**。**
[root@node01 hive]# bin/hive
hive> create database wise_db;
OK
Time taken: 3.063 seconds
hive> show databases;
OK
default
wise_db
Time taken: 0.943 seconds, Fetched: 2 row(s)
hive>
-
进入 bin 目录,再运行
**./hive**命令,初始化hive自带的内存数据库derby。
[root@node01 bin]# ./hive
hive> show databases;
OK
default
Time taken: 2.809 seconds, Fetched: 1 row(s)
hive>
测试查看所有数据库,这是会发现并没有我们刚才创建的数据库,它在不同的目录会都会创建一个新的
metastore_db和derby.log
外置MySQL版
由于Hive默认使用的使 derby 数据库,在hive依赖库中没有提供 MySQL 的连接驱动包,我们需要拷贝一个到 lib包中**。**
-
创建**
conf/hive-site.xml** 文件,配置对应的 Metastore 配置信息 ,注意配置文件顶行不要由空行
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--需要登录MySQL数据库,创建一个 hive 数据库备用-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!--安装MySQL数据库的驱动类-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--安装MySQL数据库的名称-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--在 cli 中显示表头-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!--在 cli 中显示数据库名-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--安装MySQL数据库的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
-
进入
**Hive**目录,运行bin/hive启动即可使用
[root@node01 hive]# bin/hive
hive (default)> create database wise_db;
OK
Time taken: 0.86 seconds
hive (default)> show databases;
OK
default
wise_db
Time taken: 1.163 seconds, Fetched: 2 row(s)
hive (default)> exit;
[root@node01 hive]# cd bin/
[root@node01 bin]# ./hive
hive (default)> show databases;
OK
default
wise_db
Time taken: 2.44 seconds, Fetched: 2 row(s)
运行命令的目录下,也没有再产生
metastore_db和derby.log,且登录MySQL可以看到多了一个hive数据库。
-
hive 另一种比较常用的连接方式 beeline
# 启动 hive2 服务
[root@node01 ~]# hiveserver2&
[1] 19544
# beeline 方式连接服务端
[root@node01 ~]# beeline -u jdbc:hive2://node01:10000 -n root
Connecting to jdbc:hive2://node01:10000
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1 by Apache Hive
0: jdbc:hive2://node01:10000>
Hive数据库及表操作
基本数据类型
Hive 中 的基本数据类型也称为原始类型,包括整数、小数、文本、布尔、二进制以及时间类型。这些数据类型都是Java中接口的实现,所以类型的具体行为细节和 Java 的对应的类型完全一致。
-
整数:
tinyint/smallint/int/bigint,分别对应Java中的byte、short、int、long。 -
小数:
float/double/decimal,分别对应Java中的float、double、BigDecimal。 -
文本:
string/char/varchar,String存储可变长的文本,对长度没有限制,理论上存储空间为2GB,varchar与String类似,char是定长字符串,最大长度为255。 -
布尔:
boolean,类型值有 true 和 false两种。 -
二进制:
binary,用于存储变长的二进制数据。 -
时间:
date/timestamp/interval,Date存储年月日,TimeStamp存储纳秒级别的时间戳,Interval表示时间间隔,1.2之后新增。
复杂数据类型
在 SQL 的表设计中,字段通常不能被再分解,这意味着每一个字段不能再被分隔成多个字段。而HiveQL没有这种限制。Hive有4种常用的复杂数据类型,分别是数组(Array)、映射(Map)、结构体(Struct)和联合体(UnionType)。
-
Array是具有相同类型变量的集合。这些变量称为数组的元素,每个数组元素都有一个索引编号,编号从0开始。 -
-
数据格式:
["重庆","云南","四川","北京"] -
定义示例:
array<string> -
使用示例:
arr[0] = '重庆'
-
-
Map是一组键值对集合,key只能是基本类型,值可以是任意类型。 -
-
数据格式:
{"Hadoop":60,"Java":80,"Hive":100} -
定义示例:
map<string,string> -
使用示例:
b['Hadoop']='60'
-
-
Struct封装了一组有名字的字段,其类型可以是任意的基本类型,结构体内的元素使用 ”.“ 来访问。 -
-
数据格式:
{"男",18} -
定义示例:
struct<sex:string,age:int> -
使用示例:
c.sex='男'
-
Hive DDL 操作
Hive DDL 用于定义 Hive 数据库模式,其命令包括 create、drop、alter、truncate、show和describe(desc) 等,主要是对数据库和表进行创建、修改、删除等操作。
数据库操作
-
创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name;
hive (default)> create schema if not exists wise_db; # 创建 wise_db 数据库
-
删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE]; hive (default)> drop schema if exists teste_db cascade; # 级联删除非空数据库 teste_db
默认情况下使用
RESTRICT删除数据库。如果数据库非空,则删除将会失败,此时须使用CASCADE级联删除数据库。
创建表语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name -- (TEMPORARY 表示临时表, EXTERNAL 表示外部表,不写默认是托管表(内部表))
[(col_name data_type,...)] -- (表的字段声明)
[PARTITIONED BY (col_name data_type, ...)] -- (指定分区字段,注意不能和表字段重复,查询的时候,它以表字段的形式出现)
[CLUSTERED BY (col_name, col_name, ...) INTO num_buckets BUCKETS] -- (指定字段进行分桶,注意必须是表中存在的字段)
[ROW FORMAT DELIMITED
[FIELDS TERMINATED BY char] -- (指定字段分隔符,默认是 ASCII '�01' ^A)
[COLLECTION ITEMS TERMINATED BY char] -- (指定集合元素分隔符,默认是 ASCII '�02' ^B)
[MAP KEYS TERMINATED BY char] -- (指定Map键分隔符,默认是 ASCII '�03' ^C)
]
[LOCATION hdfs_path] -- (指定 hive 仓库存放数据的 hdfs 目录)
-
CREATE TABLE:创建一个指定名称的表,如果存在同名表,则抛出异常。可以使用IF NOT EXISTS忽略该异常。 -
EXTERNAL [ɪkˈstɜːnl]:表示该表为外部表,须同时指定实际数据存放的HDFS路径LOCATION,而其他表都是存放在 hive 的默认路径/user/hive/warehouse/下。当外部表被删除时,实际数据不会被删除。 -
TEMPORARY [ˈtemprəri]:指定该表为临时表,临时表只对当前会话有效,会话退出后临时表自动删除。临时表不支持分区与索引。 -
PARTITIONED [pɑːˈtɪʃn] BY:分区内部表,创建表时可以为表创建一个或多个分区,查询时在 where 子句中指定分区可提升查询效率,缩小查询范围,而不是扫描整个表的内容。 -
CLUSTERED[ˈklʌstəd] BY:分桶内部表,让数据能够均匀地分布在表的各个数据文件中,划分粒度更细。Hive采用对列值哈希,然后除于桶的个数求余的方式决定该条记录存放在那个桶当中。这么做的目的就是获得更高的查询处理效率( join查询 ),使取样更高效。 -
ROW FORMAT:用于指定SerDe(Serialize/Deserilze , 序列化与反序列化器),Hive用于读写表的每一行数据。
托管表(内部表)
Hive 托管表也称为内部表。它与数据库中的 Table 在概念上是类似。每一个托管表在 Hive 中都有一个相应的目录存储数据,所有的托管表数据(不包括外部表)都保存在这个目录中,删除托管表时,元数据与数据都会被删除。
# 使用数据库 hive (default)> use wise_db; # 创建一个托管表 hive (wise_db)> create table if not exists dept(deptno int,dname string,loc string) row format delimited fields terminated by ','; # 指定结构化数据的分隔符,默认是'�01'
创建表的时候,需要指定分隔符,列的分隔符默认是 '�01',行的分隔符模式是 ' '。
向托管表 dept 添加装载数据,怎么做呢?准备一个 结构化数据,列分隔符是 “ , ” ,行分割符是 “
”,直接使用 hadoop fs -put 的方式上传到 dept 表所在的目录/user/hive/warehouse/wise_db.db/dept即可,Hive 会自动与 dept 表 关联映射。
10,科技部,重庆沙坪坝 20,市场部,重庆九龙坡 30,财务部,重庆渝北区 [root@node01 hive_data]# hadoop fs -put dept.txt /user/hive/warehouse/wise_db.db/dept
查看数据是否装载成功,通过使用 selecet 语句来查看
hive (wise_db)> select * from dept; OK dept.deptno dept.dname dept.loc 10 科技部 重庆沙坪坝 20 市场部 重庆九龙坡 30 财务部 重庆渝北区 Time taken: 3.037 seconds, Fetched: 3 row(s)
到此,Hive的简单表创建和数据装载就讲完了,除此之外,我们还可以在定义表的Schema 时指定 LOCATION 地址 ,Hive 将自动关联该目录下的数据文件,而不是使用默认的地址。
[root@node01 hive_data]# hadoop fs -mkdir -p /hive/dept # hdfs 上创建多级目录 [root@node01 hive_data]# hadoop fs -put dept.txt /hive/dept # 上传 dept.txt 文件到 dept 目录 [root@node01 hive_data]# hadoop fs -ls /hive/dept # 查看文件是否上传成功 hive (wise_db)> create table if not exists dept2(deptno int,dname string,loc string) row format delimited fields terminated by ',' location '/hive/dept'; # 指定表数据存储地址,注意是HDFS文件系统目录 hive (wise_db)> drop table dept2; # 删除dept2表和表数据
其他常用 DDL 操作
-
复制表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name LIKE existsing_table_name; # LIKE 允许用户复制现有的表结构,但是不复制数据 hive (wise_db)> create table dept_copy like dept; hive (wise_db)> select * from dept_copy; OK +-------------------+------------------+----------------+ | dept_copy.deptno | dept_copy.dname | dept_copy.loc | +-------------------+------------------+----------------+ +-------------------+------------------+----------------+ No rows selected (0.337 seconds)
-
删除表
DROP TABLE table_name; # 删除表 TRUNCATE TABLE table_name; # 清空表中所有数据 hive (wise_db)> drop table dept_2; # 删除表数据和表结构 hive (wise_db)> truncate table dept; # 清空表数据,保留表结构
-
显示相关命令
show databases|schemas; # 显示所有数据库名 show tables; # 列出当前数据库中所有表 show create table table_name; # 显示建表语句 desc database database_name; # 显示数据库信息 desc table_name; # 显示表信息 desc table_name.col_name; # 显示表中某列的信息
Hive DML 操作
在定义表的Schema 时指定 LOCATION ,Hive 将自动关联该目录下的数据文件,通常情况下,数据需要手动装载并进行维护管理,此时就需要使用 Hive DML 命令了。
在 Hive 中,DML 操作包括 load、insert 命令,分别对数据进行数据装载、插入等操作。
数据装载与插入
一般使用两种方式实现数据装载,分别是 load 和 insert 命令,二者有明显的区别。
-
load命令不对数据进行任何转换,只是简单地将数据复制或者移动至Hive表对应的位置,其实就是执行了hadoop fs -put命令。
LOAD DATA [LOCAL] INPATH 'file_path' [OVERWRITE] INTO TABLE table_name [PARTITION(partcoll=val1,partcoll2=val2,....)]
-
LOCAL:指定使用本地文件系统路径,装载时是复制操作。如果没有该关键字则是 HDFS 路径,装载时是移动操作。 -
OVERWRITE:覆盖目标文件夹中的数据,如果没有该关键字且目标文件夹中已存在同名文件,将保留之前的文件,新文件名后缀以自动序号区分。 -
PARTITION:如果目标表是分区表,须使用该关键字为每一个分区键指定一个值。
hive (wise_db)> truncate table dept; # 清空原来表的数据 hive (wise_db)> load data local inpath '/root/hive_data/dept.txt' into table dept; # 加载本地数据 # 再次执行上述数据装载,由于目标文件夹中已存在同名文件,则它不会报错,而是直接修改名称(dept_copy_1.txt)存放在当前目录,如果之前的数据不再需要,则可以 # 添加 overwrite 关键字进行覆盖,之前的dept.txt 和 dept_copy_1.txt 都会删除 hive> load data local inpath '/root/hive_data/dept.txt' overwrite into table dept; # 不加 local 关键字,则它会去查找 HDFS 系统目录下的文件,并移动到指定的表数据存放目录下 hive> load data inpath '/hive/dept.txt' overwrite into table dept;
-
insert命令将会执行MapReduce作业并将数据插入值Hive表中,一般使用较少,但是分桶表只能使用它,load data不会执行分桶操作。
INSERT (INTO|OVERWRITE) TABLE table_name [PARTITION(partcol1=val1,partcol2=val2)] select_statement FROM from_stattement; hive (wise_db)> create dept2 like dept; hive (wise_db)> insert into dept2 select * from dept;
Hive 复杂类型的使用
Hive 中的复杂类型包括 array(数组)、map(字典)、struct(结构体)等。
临时表(Temporary[ˈtemprəri])使用:临时表只对当前 session 有效,session退出后,表自动删除。临时表不支持分区字段和创建索引。
create temporary table if not exists temp_user_info(
id int,
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
score map<string,float>
)
row format delimited -- 指定结构化数据分隔符,保证数据能够正确映射到Hive表中
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':' ;
1|tom|重庆,云南,四川,北京|男,18|Hadoop:60,Java:80,Hive:100
2|tim|成都,大理,新疆,红河|男,28|Hadoop:70,Java:60,Hive:90
3|kim|广州,丽江,西双版纳,北京|男,19|Hadoop:90,Java:80,Hive:95
4|aim|天津,云南,合川,大足|男,23|Hadoop:100,Java:90,Hive:88
5|ros|重庆,武汉,垫江,昭通|男,54|Hadoop:55,Java:100,Hive:98
hive (wise_db)> load data local inpath '/root/hive_data/user_info.txt' into table temp_user_info; # 装载数据
hive (wise_db)> select * from temp_user_info; # 查询所有数据
OK
emp_temp.id emp_temp.name emp_temp.work_place emp_temp.sex_age emp_temp.score
1 tom ["重庆","云南","四川","北京"] {"sex":"男","age":18} {"Hadoop":60.0,"Java":80.0,"Hive":100.0}
2 tim ["成都","大理","新疆","红河"] {"sex":"男","age":28} {"Hadoop":70.0,"Java":60.0,"Hive":90.0}
3 kim ["广州","丽江","西双版纳","北京"] {"sex":"男","age":19} {"Hadoop":90.0,"Java":80.0,"Hive":95.0}
4 aim ["天津","云南","合川","大足"] {"sex":"男","age":23} {"Hadoop":100.0,"Java":90.0,"Hive":88.0}
5 ros ["重庆","武汉","垫江","昭通"] {"sex":"男","age":54} {"Hadoop":55.0,"Java":100.0,"Hive":98.0}
Time taken: 0.25 seconds, Fetched: 5 row(s)
hive (wise_db)> select work_place[0],sex_age.sex,sex_age.age,score['Hadoop'] from temp_user_info; # 访问复杂类型中的数据
OK
_c0 sex age _c3
重庆 男 18 60.0
成都 男 28 70.0
广州 男 19 90.0
天津 男 23 100.0
重庆 男 54 55.0
Time taken: 0.403 seconds, Fetched: 5 row(s)
hive (wise_db)> show create table temp_user_info; # 显示数据表创建信息,了解数据表存放地址
Hive 数据模型
前面我们的所创建的表都是托管表(内部表),除此之外Hive还提供了:分区表(Partition [pɑːˈtɪʃn])、桶表(Bucket [ˈbʌkɪt])、外部表(External [ɪkˈstɜːnl])、临时表(Temporary [ˈtemprəri])、视图(View)这几种数据模型。
分区表
在 Hive Select 查询中一般会扫描整个表的内容,会消耗很多时间做没有必要的工作,有时候只需要扫描表中关心的一部分数据,因此建表时引入了 Parition 概念。分区表指的是在创建表时指定的 Partition 的分区空间。
Hive 可以对数据按照某列或者某些列进行分区管理。表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。
# 这里不能使用 临时表 关键字,临时表不支持分区和索引 create table emp_partition( id int, -- 可以用空格,但是不能用 tab name string, age int ) partitioned by (country string) -- 指定分区字段,注意它会转变为虚拟字段,不能和表字段重名 row format delimited fields terminated by ',';
使用 insert 装载数据
hive (wise_db)> insert into table emp_partition partition(country='CN') select 1,'张三','18'; hive (wise_db)> insert into table emp_partition partition(country='USA') select 2,'Tom','22'; # 查看装载情况 hive (wise_db)> select * from emp_partition; OK +-------------------+---------------------+--------------------+------------------------+ | emp_partition.id | emp_partition.name | emp_partition.age | emp_partition.country | +-------------------+---------------------+--------------------+------------------------+ | 1 | 张三 | 18 | CN | | 2 | Tom | 22 | USA | +-------------------+---------------------+--------------------+------------------------+ 2 rows selected (0.347 seconds)
使用 load 装载数据
# USA 分区数据 1,aim,18 2,tim,28 3,kim,16 hive (wise_db)> load data local inpath '/root/hive_data/usa.txt' into table emp_partition partition(country='USA'); # CN 分区数据 4,李四,23 5,王五,54 6,赵六,25 hive (wise_db)> load data local inpath '/root/hive_data/cn.txt' into table emp_partition partition(country='CN');
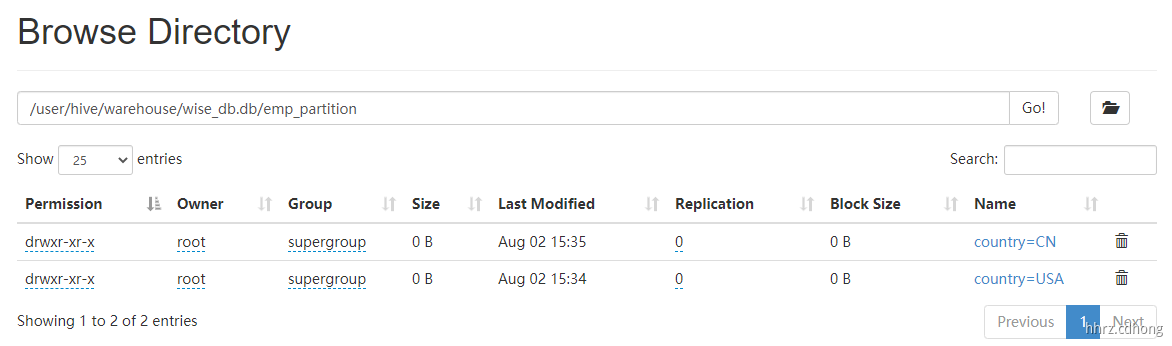
HDFS 存储格式如下:
分桶表
对于每一个表或分区,Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive 针对某一列进行桶的组织,Hive采用对列值进行哈希取值,然后除以桶的个数以求余的方式决定该条记录存放在那个桶当中,即放到不同文件中存储。
把表(或分区)组织成桶(Bucket)有如下两个理由。
-
获取更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理某些查询时利用这个结构,特别是 join 查询 。 -
取样更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
# 分桶表创建 create table emp_bucket( id int, name string, age int ) clustered by(name) into 2 buckets -- 指定分桶列和分桶个数,注意分桶列一定是在表字段中 row format delimited fields terminated by ','; # 桶表插入数据之前,必须先执行如下命令,指定开启分桶的功能 set hive.enforce.bucketing = true; # 使用 emp 表中的数据进行插入,使用 load data 的方式没有分桶的效果,原因没有执行 mapreduce 程序来进行分桶,简单的文件复制上传无法完成 insert into table emp_bucket select id,name,age from emp_partition cluster by(name);
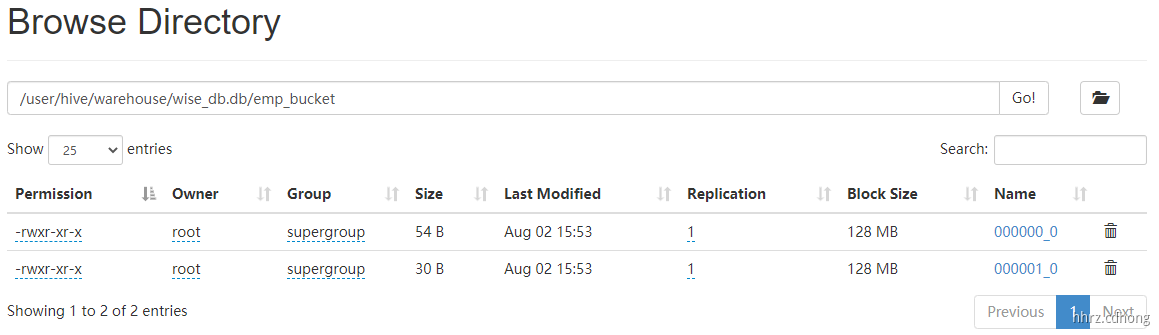
HDFS 存储格式如下:
外部表
外部表是指向已经在 HDFS 中存在的数据,它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异,因为外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该表的元数据,创建外部表时,会多一个 EXTERNAL标识,一般情况下我们还会指定 LOCATION 主要原因就是删除外部表不会删除HDFS结构化数据和文件夹。
hive (wise_db)> create external table emp_external( id int, name string, age int ) row format delimited fields terminated by ',' location '/hive' ; 1,张三,18 2,李四,19 3,王五,28 4,赵六,38 [root@node01 hive_data]# hadoop fs -put emp_external.txt /hive hive (wise_db)> select * from emp_external; # 查询数据 hive (wise_db)> select * from emp_external; # 再次查询表会提示数据表没有发现 FAILED: SemanticException [Error 10001]: Line 1:14 Table not found 'emp_external'
数据更新、删除和修改
从0.14版本起 Hive 支持数据更新与删除操作,从2.2版本起 Hive 支持数据合并操作。执行这些操作的表须在表上开启事务(ACID)支持,缺省情况下无须开启。
Hive 是数据仓库的解决方案,不适合进行更新、删除等事务操作。
数据导入/导出
-
export 数据导出至 HDFS 文件系统中
EXPORT TABLE table_name [PARTITION(partcol1=val1,...)] TO 'export_target_path';
-
使用 export 命令将指定表导出至 指定的 HDFS 目录,包括其元数据与实际数据。
hive (wise_db)> export table dept to '/export/dept'; # 导出 dept 表
[root@node01 hive_data]# hadoop fs -cat /export/dept/data/* # 查看表结构化数据
10,科技部,重庆沙坪坝
[root@node01 hive_data]# hadoop fs -cat /export/dept/_* # 查看元数据
{"version":"0.2","table":"{"1":{"str":"dept"},"2":{"str":"wise_db"},"3":{"str":"root"},"4":{"i32":1596336150},"5":{"i32":0},"6":{"i32":0},"7":{"rec":{"1":{"lst":["rec",3,{"1":{"str":"deptno"},"2":{"str":"int"}},{"1":{"str":"dname"},"2":{"str":"string"}},{"1":{"str":"loc"},"2":{"str":"string"}}]},"2":{"str":"hdfs://node01:8020/user/hive/warehouse/wise_db.db/dept"},"3":{"str":"org.apache.hadoop.mapred.TextInputFormat"},"4":{"str":"org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"},"5":{"tf":0},"6":{"i32":-1},"7":{"rec":{"2":{"str":"org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"},"3":{"map":["str","str",2,{"serialization.format":",","field.delim":","}]}}},"8":{"lst":["str",0]},"9":{"lst":["rec",0]},"10":{"map":["str","str",0,{}]},"11":{"rec":{"1":{"lst":["str",0]},"2":{"lst":["lst",0]},"3":{"map":["lst","str",0,{}]}}},"12":{"tf":0}}},"8":{"lst":["rec",0]},"9":{"map":["str","str",6,{"totalSize":"29","numRows":"1","rawDataSize":"28","COLUMN_STATS_ACCURATE":"{\"BASIC_STATS\":\"true\"}","numFiles":"1","transient_lastDdlTime":"1596340668"}]},"12":{"str":"MANAGED_TABLE"},"15":{"tf":0}}","partitions":[]}
-
insert 数据导出至本地文件系统中(覆盖导出)
INSERT OVERWRITE [LOCAL] DIRECTORY directory [ROW FORMAT row_format] [STORED AS file_format] SELECT ... FROM ...
LOCAL :指定导出地址是 HDFS 还是 本地地址
hive (wise_db)> insert overwrite local directory '/root/hive_data/export' row format delimited fields terminated by ',' select * from dept; # 导出 dept 表数据 到 export 目录 [root@node01 hive_data]# cat /root/hive_data/export/* # 查看 导出数据 10,科技部,重庆沙坪坝 20,市场部,重庆九龙坡 30,财务部,重庆渝北区
-
import 向 HDFS 指定目录导入数据并生成新的内部表
IMPORT TABLE table_name [PARTITION(partcol1=val1,...)] FROM 'source_path' ; hive (wise_db)> import table new_dept from '/export/dept'; Copying data from hdfs://node01:8020/export/dept/data Copying file: hdfs://node01:8020/export/dept/data/dept.csv Loading data to table wise_db.new_dept OK Time taken: 6.445 seconds hive (wise_db)> select * from new_dept; OK new_dept.deptno new_dept.dname new_dept.loc 10 科技部 重庆沙坪坝 20 市场部 重庆九龙坡 30 财务部 重庆渝北区 Time taken: 0.567 seconds, Fetched: 3 row(s)
Hive高级操作
Hive Select 语句用于从表中检索数据,是标准 SQL 的子集,在Hive 中也是使用频率最高、最复杂的部分。
Select 语句
Hive Select 语句用于对表进行查询,即按照规定的语法规则从表中选取数据,并将查询结果保存在结果表中。基本语法如下:
SELECT [ALL|DISTINCT] select_expr,select_expr,…
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list|[DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT[offset,]rows]
创建一个测试表 emp以及对应的测试数据
hive (wise_db)> create table emp (empno int,ename string,job string,mgr int,hiredate date,sal float,comm float,deptno int) row format delimited fields terminated by ','; [root@node01 hive_data]# vim emp.txt 7369,SMITH,CLERK,7902,1980-12-17,800,NULL,20 7499,ALLEN,SALESMAN,7698,1981-02-20,1600,300,30 7521,WARD,SALESMAN,7698,1981-02-22,1250,500,30 7566,JONES,MANAGER,7839,1981-04-02,2975,NULL,20 7654,MARTIN,SALESMAN,7698,1981-09-28,1250,1400,30 7698,BLAKE,MANAGER,7839,1981-05-01,2850,NULL,30 7782,CLARK,MANAGER,7839,1981-06-09,2450,NULL,10 7788,SCOTT,ANALYST,7566,1987-07-13,3000,NULL,20 7839,KING,PRESIDENT,NULL,1981-11-07,5000,NULL,10 7844,TURNER,SALESMAN,7698,1981-09-08,1500,0,30 7876,ADAMS,CLERK,7788,1987-07-13,1100,NULL,20 7900,JAMES,CLERK,7698,1981-12-03,950,NULL,30 7902,FORD,ANALYST,7566,1981-12-03,3000,NULL,20 7934,MILLER,CLERK,7782,1982-01-23,1300,NULL,10 hive (wise_db)> load data local inpath '/root/hive_data/emp.csv' overwrite into table emp;
Where 子句
where 条件必须是布尔表达式,用于过滤结果集。
# 查询 emp 表 员工工资大于 1500 且 部门是 30 号 hive (wise_db)> select * from emp where sal>1500 and deptno=30; +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ | emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno | +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.0 | 300.0 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.0 | NULL | 30 | +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ 2 rows selected (3.691 seconds)
LIMIT 字句
LIMIT 字句用于限制 SELECT 语句返回的行数,其后的整数参数表示共返回多少行。(从2.0版本开始支持两个参数)
hive (wise_db)> select * from emp limit 4; OK +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ | emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno | +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ | 7369 | MITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.0 | 300.0 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.0 | 500.0 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.0 | NULL | 20 | +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ 4 rows selected (1.851 seconds)
排序
ORDER BY:Hive 中的 ORDER BY 语句与 SQL 中的类似,可以对结果集进行全局排序,即Hive可对所有数据进行 Reducer 处理以保全局有序,但当数据规模较大时此过程比较耗时。所以 strict (hive.mapred.mode=strict,默认是 nonstrict)模式下,Hive 对 ORDER BY 进行了限制,要求ORDER BY 子句后必须跟随 “LIMIT” 子句,以防止单个 Reducer 处理时间过长。
ORDER BY 语句默认按 ASC(升序)排序,排序字段必须出现在 SELECT 字句中。
hive (wise_db)> set hive.mapred.mode=strict; hive (wise_db)> select * from emp order by deptno desc limit 5; +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ | emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno | +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.0 | 1400.0 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.0 | 500.0 | 30 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.0 | 0.0 | 30 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.0 | NULL | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.0 | 300.0 | 30 | +------------+------------+-----------+----------+---------------+----------+-----------+-------------+ 5 rows selected (148.979 seconds)
分组
SELECT 语句在未指定 GROUP BY 子句的情况下,会将整个表当作一个分组。例如 count() 函数便是对组内的所有行数进行统计,其默认统计整个表的行数而不需要指定 GROUP BY。
hive (wise_db)> select deptno,count(1) total from emp group by deptno; +---------+--------+ | deptno | total | +---------+--------+ | 10 | 3 | | 20 | 5 | | 30 | 6 | +---------+--------+ 3 rows selected (158.901 seconds)
基础聚合函数
-
max(col):返回组内某列中的最大值 -
min(col):返回组内某列中的最小值 -
count(*):返回组内总行数,包括值为NULL的行 -
count(DISTINCT expr):返回组内 expr 唯一且 非 NULL 的行的数量 -
sum(col):返回组内某列元素的总和 -
avg(col)