配置hosts文件
vi /etc/hosts
# 添加三台主机host与ip对应关系
192.168.147.102 bigdata01
192.168.147.103 bigdata02
192.168.147.104 bigdata03
安装JDK并配置环境变量
# 解压
tar -zxvf jdkxxx.tar.gz -C /usr/local
# 配置到环境变量
vi /etc/profile
export JAVA_HOME=/data/soft/jdk1.8
export PATH=.:$JAVA_HOME/bin:$PATH
# 环境变量生效
source /etc/profile
配置免密登录
以bigdata02机器为例,执行如下命令可生成密钥
ssh-keygen -t rsa
执行该命令一直回车即可, 生成成功界面如下
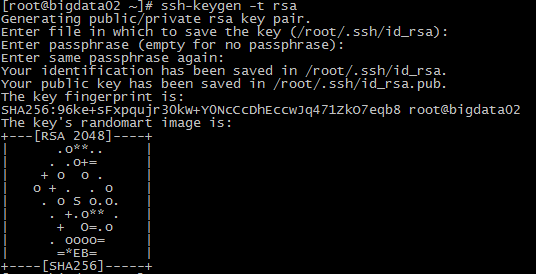
然后把刘海国外两台机器也执行如下命令,这样三台机器即可成功生成密钥,如果使用root用户,密钥位置在~/.ssh/目录下,接下来需要把三台服务器生成的公钥都追加到各自服务器的~/.ssh/authorized_keys文件中,操作命令如下
# 在bigdata01、bigdata02、bigdata03中都执行这三条命令
ssh-copy-id -i bigdata01
ssh-copy-id -i bigdata02
ssh-copy-id -i bigdata03
关闭防火墙
# 查看防火墙状态
systemctl status firewalld
# 禁止防火墙
systemctl stop firewalld
# 禁止开机自启防火墙
systemctl disable firewalld
同步时间
# 安装ntpdate工具
yum -y install ntpdate
# 同步阿里时间
ntpdate ntp1.aliyun.com
解压Hadoop安装包
tar -zxvf hadoop-3.2.0.tar.gz -C /data/soft
修改Hadoop相关配置文件
-
hadoop-env.sh
cd /data/soft/hadoop-3.2.0/etc/hadoop # 编辑hadoop-env.sh vi hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.8 -
core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://bigdata01:9000</value></property><property> <name>hadoop.tmp.dir</name> <value>/data/hadoop_repo</value></property> -
hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>bigdata01:50090</value> </property>-
mapred-site.xml
设置mapreduce使用的资源调度框架
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
yarn-site.xml
设置yarn上支持运行的服务和环境变量白名单
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata01</value> </property> -
修改workers文件
增加所有从节点的主机名,一个一行,这里使用bigdata01做主节点,那么bigdata02、bigdata03就是从节点了
删除掉默认的Localhost 并添加bigdata02、bigdata03
bigdata02 bigdata03修改启动脚本
-
修改
start-dfs.sh、stop-dfs.sh这两个脚本,在脚本顶部加入如下内容HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root -
修改start-yarn.sh,stop-yarn.sh这两个脚本,在脚本顶部加入如下内容
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root将hadoopan安装包分发到其他两个从节点(bigdata02、bigdata03)上。
scp -r /data/soft/hadoop-3.2.0/ root@bigdata02:/data/soft/ scp -r /data/soft/hadoop-3.2.0/ root@bigdata03:/data/soft/
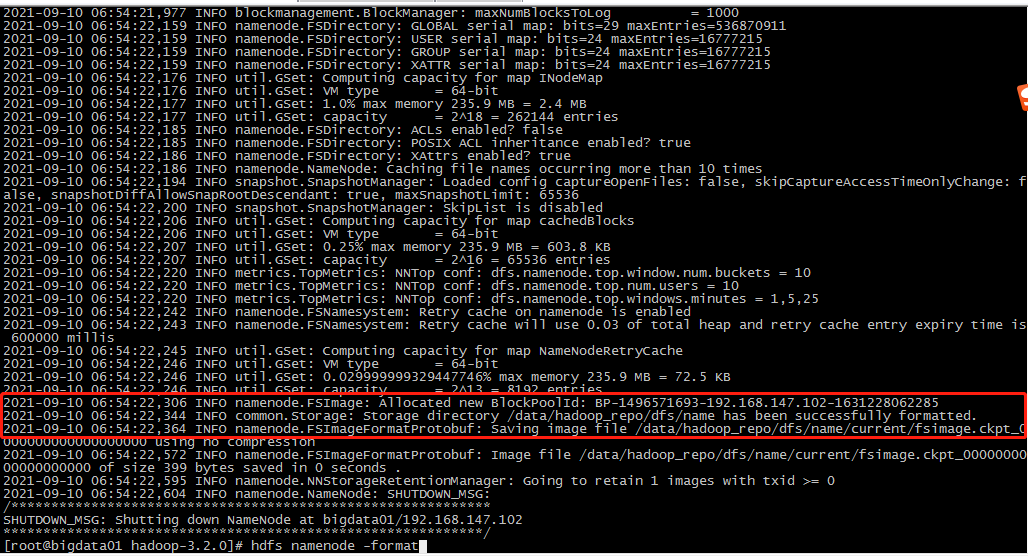
格式化NameNode
切换到主节点bigdata01,执行格式化命令
hdfs namenode -format可以将hadoop/sbin 和 bin目录配置到环境变量中
-
如果得到下图信息表示格式化执行成功。
-
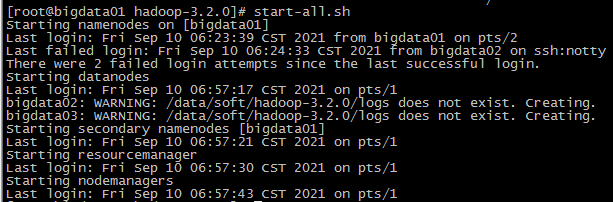
启动集群
在主节点上执行启动所有进程
start-all.sh
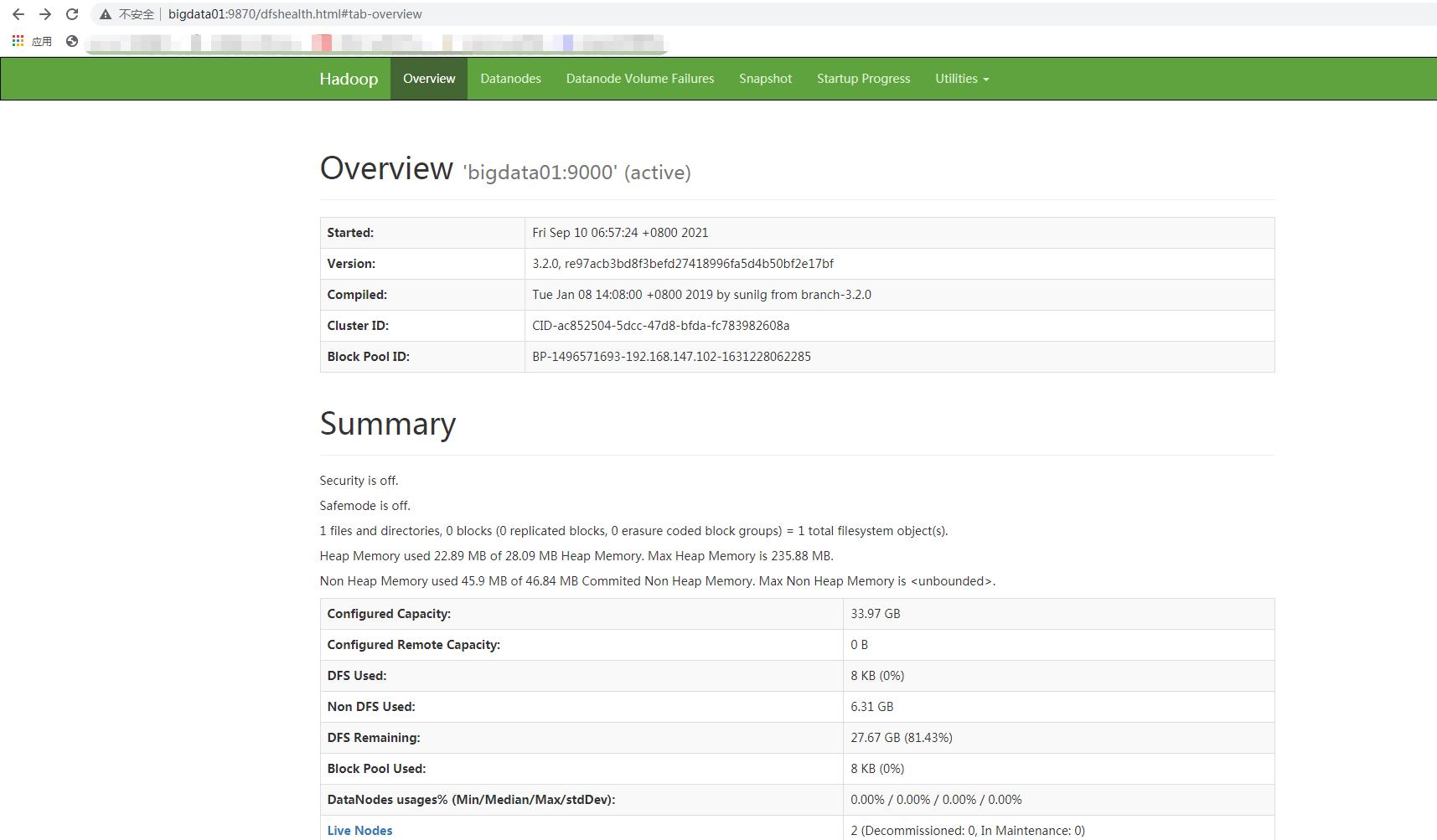
Web-UI验证
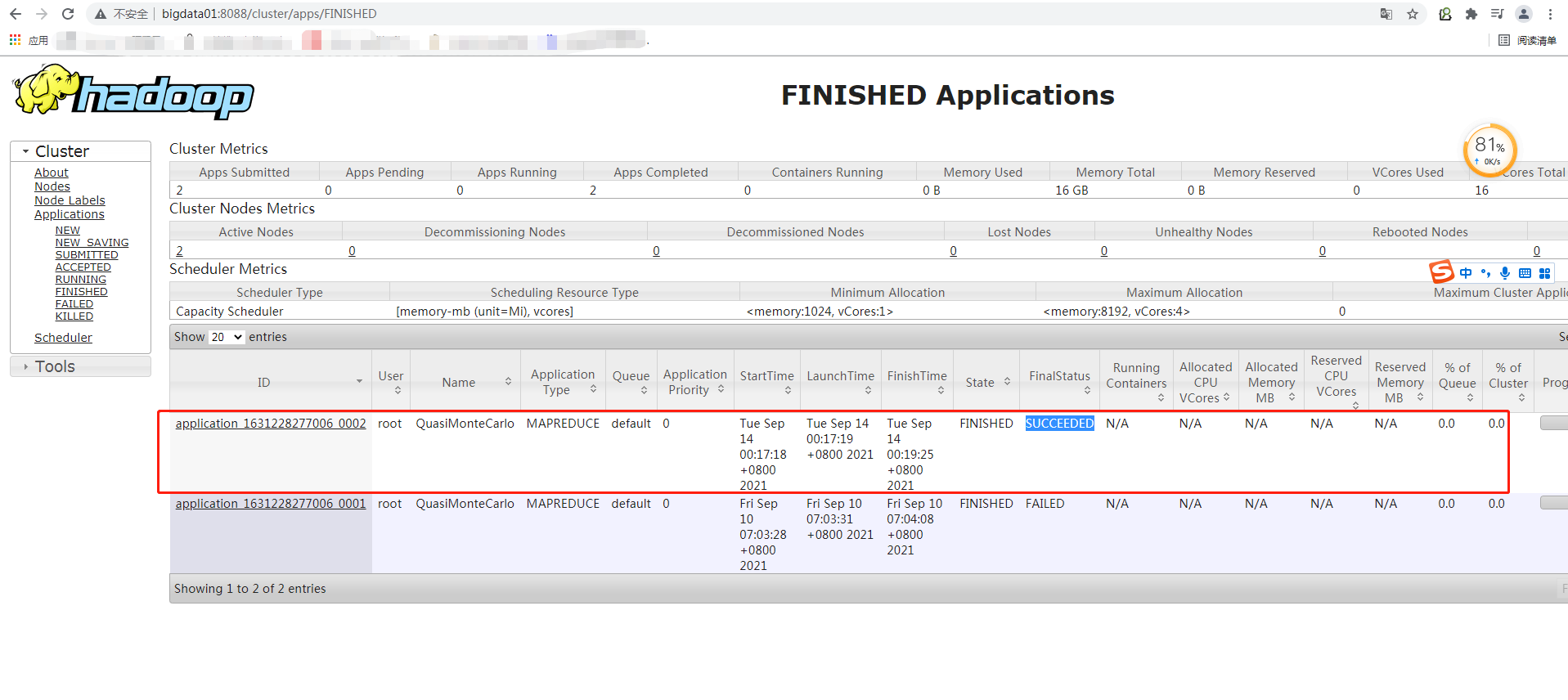
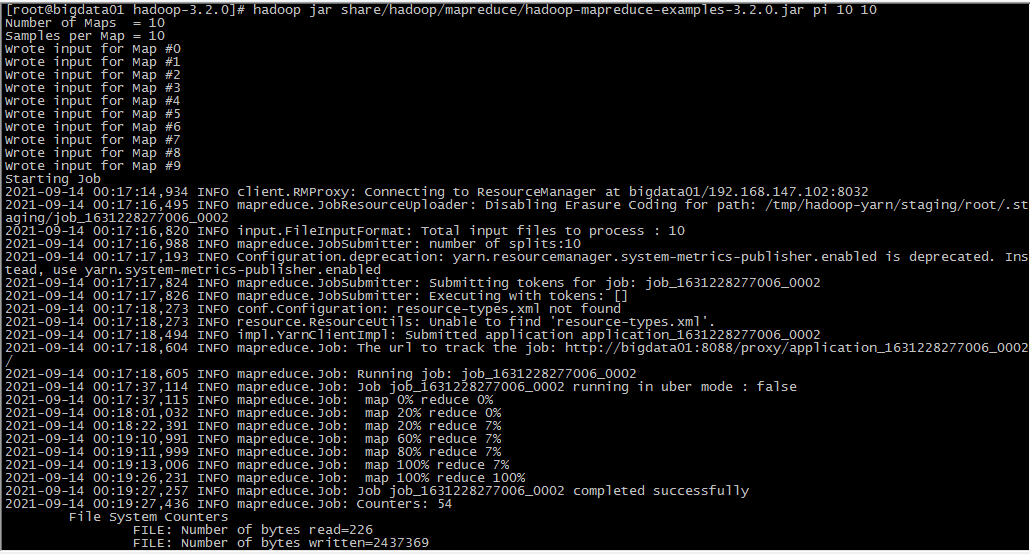
执行MR测试任务
此处使用PI值实例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar pi 10 10
其中:第一个10是运行10次map任务,第二个10是每次map任务投掷次数,所以总投掷次数为10*10=100次
MR Web UI信息