MapReduce是一种分布式计算模式,由Google提出,主要用于搜索领域,解决海量数据的计算问题,mapRedcure是分布式运行的,分为map阶段和Reduce阶段。
Map阶段是一个独立的程序,可在多个节点同时运行,每个节点处理一部分数据。
Reduce阶段也是一个独立的程序,可以再一个或者多个节点同时运行,每个节点处理一部分数据。
观摩笔记
WordCount实战
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Iterator;
/**
* 需求:读取hdfs上的hello word.txt文件,计算文件中每个单词出现的总次数
*
* 原始文件hello.txt内容如下:
* hello you
* hello me
*
* 最终需要的结果形式如下:
* hello 2
* me 1
* you 1
*
*
* @author zhangshao
* @date 2021/3/28 4:59 下午
*/
public class WordCountJob {
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
/**
* 需要实现map函数,
* 这个map函数就是可以接收<k1,v1>,产生<K2,v2>
* @param k1 代表每一行数据的行首偏移量,
* @param v1 v1代表的是每一行内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String[] words = v1.toString().split(" ");
for(String word:words){
//把迭代出来的单词封装<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* reduce 阶段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
@Override
public void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
//创建一个sum变量,保存v2s之和
long sum = 0L;
for(LongWritable v2:v2s){
sum +=v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//把结果写出去
context.write(k3,v3);
}
}
/**
* 组装jon = map+reduce
*/
public static void main(String[] args) {
try{
if(args.length!=2){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定job需要的配置参数
Configuration conf = new Configuration();
//创建一个job
Job job = Job.getInstance(conf);
//注意:这一行必须设置,否则在集群中执行的时候找不到WordCountJob这个类
job.setJarByClass(WordCountJob.class);
//指定输入路径(可以是文件,也可以是路径)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//输出路径(只能指定一个不存在的路径)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}catch (Exception e){
e.printStackTrace();
}
}
}
主代码开发完毕后,需要打jar包到集群上去执行,需要在pom中添加maven的编译打包插件。
<build>
<plugins>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
注意:在添加完build相关编译依赖后,还需要在pom文件中的hadoop-client和log4j依赖中增加scope属性,值为provided,表示只在编译的时候使用该依赖,在执行及打包的时候不使用,因为hadoop-client和log4j依赖在集群中都是有的,打jar的时候不需要打进去。
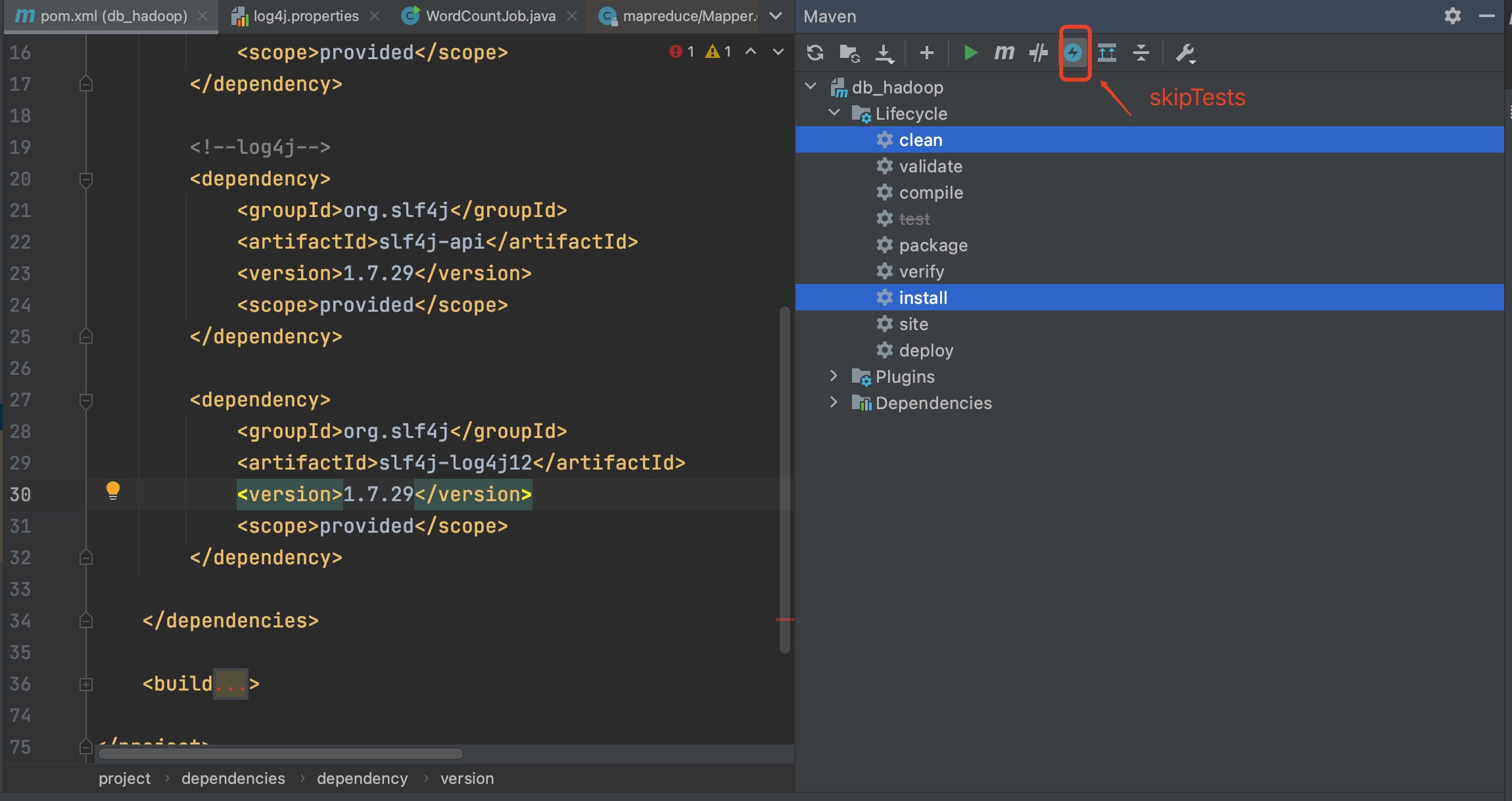
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.2.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.29</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.29</version> <scope>provided</scope> </dependency>之后使用编译命令打包或idea中点击install
mvn clean package -DskipTests
随后将jar上传到集群中。
创建hello.txt文件
[root@bigdata01 ~]# vi hello.txt
hello you
hello me
接下来就可以向集群中提交MapReduce任务了。
具体命令如下:
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out
- hadoop:表示使用hadoop脚本提交任务,其实这里也可以使用yarn,从hadoop2.x开始支持yarn,不过也兼容hadoop1
- jar:表示执行jar包
- db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar:表示具体的jar包路径
- com.imooc.mr.WordCountJob:表示要执行的mapreduce代码的全路径
- /test/hello.txt:指定mapreduce接收到的第一个参数,代表的是输入路径。
- /out:指定mapreduce接收到的第二个参数,代表的是输出目录,这里的输出目录必须是不存在的,MapReduce程序在执行之前会检测这个输出目录,如果存在会报错,因为每次执行任务都需要创建一个新的输出目录来存储结果数据。
查看任务执行状态
2021-04-03 09:56:53,269 INFO mapreduce.Job: map 0% reduce 0%
2021-04-03 09:56:59,409 INFO mapreduce.Job: map 100% reduce 0%
2021-04-03 09:57:05,462 INFO mapreduce.Job: map 100% reduce 100%
2021-04-03 09:57:06,488 INFO mapreduce.Job: Job job_1617414772389_0001 completed successfully
也可以在web界面上查看执行情况。
访问地址:http://bigdata01:8088

查看执行结果
[root@bigdata01 ~]# hdfs dfs -ls /out/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2021-04-03 09:57 /out/_SUCCESS
-rw-r--r-- 1 root supergroup 19 2021-04-03 09:57 /out/part-r-00000
_SUCCESS文件是一个标记文件,代表该任务执行成功。
此外,part后面的-r表示这个结果文件是由reduce步骤产生的,如果一个mapreduce只有map阶段没有reduce阶段,那么产生的结果文件是part-m-xxxx
[root@bigdata01 ~]# hdfs dfs -cat /out/part-r-00000
hello 2
me 1
you 1