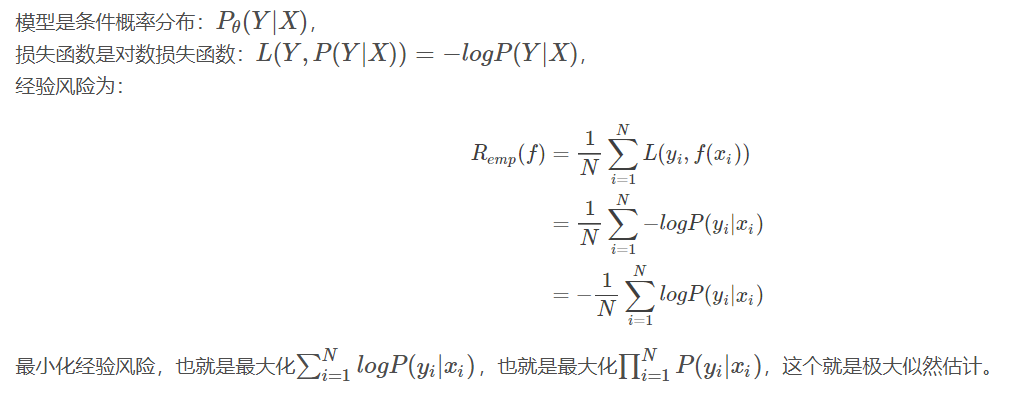原文链接: https://blog.csdn.net/liufei00001/article/details/80973809
beta分布 https://blog.csdn.net/a358463121/article/details/52562940
MLE与bayes https://blog.csdn.net/bitcarmanlee/article/details/52201858
1.1
统计学习方法的三要素是模型、策略、算法。
伯努利模型是定义在取值为0与1的随机变量上的概率分布。
统计学分为两派:经典统计学派和贝叶斯统计学派。两者的不同主要是,经典统计学派认为模型已定,参数未知,参数是固定的,只是还不知道;贝叶斯统计学派是通过观察到的现象对概率分布中的主观认定不断进行修正。
极大似然估计和贝叶斯估计的模型都是伯努利模型也就是条件概率模型;极大似然估计用的是经典统计学派的策略,贝叶斯估计用的是贝叶斯统计学派的策略;为了得到使经验风险最小的参数值,使用的算法都是对经验风险求导,使导数为0.
定义随机变量A为一次伯努利试验的结果,A的取值为{0,1}{0,1},概率分布为P(A)P(A):
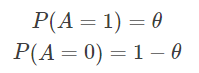
下面分布用极大似然估计和贝叶斯估计来估计θ 的值。
极大似然估计: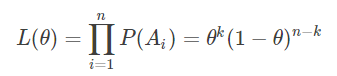
Ai代表第i次随机试验。解得: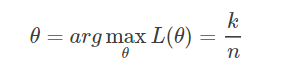
贝叶斯估计:

根据观察到的结果修正θ,也就是假设θ是随机变量,θ服从β分布,有很多个可能的取值,我们要取的值时在已知观察结果的条件下使θ出现概率最大的值。上式分母是不变的,求分子最大就可以。P(θ)先验概率.

其中a,b 是β 分布中的参数 :
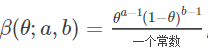
一个常数:在beta分布中,这个常数只是为了使得这个分布的概率密度积分等于1才加上的。
注:贝叶斯估计与极大似然估计的差别
贝叶斯估计引入了先验概率,通过先验概率与似然概率来求解后验概率。而最大似然估计是直接通过最大化似然概率来求解得出的。
换句话说,最大似然估计没有考虑模型本身的概率,或者说认为模型出现的概率都相等。而贝叶斯估计将模型出现的概率用先验概率的方式在计算过程中有所体现。
具体例子可以见
假如人们会感染一种病毒,有一种测试方法,在被测试者已感染这个病毒时,测试结果 为阳性的概率为95%。在被测试者没有感染这个病毒时,测试结果为阳性的概率为2%。现在,有一个人的测试结果为阳性,问这个人感染了病毒吗?
如果用最大似然估计的方法,既然感染了病毒出现阳性的概率为95%,没感染出现阳性的概率为2%,本着谁大像谁的原则,那我就认为这个人已经感染了病毒。
但是如果用贝叶斯方法进行估计,如果我们得知有一个先验概率,比如整体人群中只有1%的人会感染此种病毒,那么由贝叶斯公式:

其中,p(真阳性|检测为阳性)p(真阳性|检测为阳性)为后验概率,即我们通过检测出为阳性可以判断为真阳性的概率;p(真阳性)p(真阳性)为先验概率,p(检测为阳性|真阳性)p(检测为阳性|真阳性)为条件概率,p(真阳性)p(检测为阳性|真阳性)+p(真阴性)p(检测为阳性|真阴性)p(真阳性)p(检测为阳性|真阳性)+p(真阴性)p(检测为阳性|真阴性)为全概率,检测出为阳性是由一个完备事件组构成的:这个人要么是真阳性,要么是真阴性。
由此可见,在贝叶斯估计中,先验概率对结果的影响很大。在这种场景下,采用贝叶斯估计似乎更为合理一些。
但是注意:
MLE简单又客观,但是过分的客观有时会导致过拟合(Over fitting)。在样本点很少的情况下,MLE的效果并不好。比如我们前面举的病毒的例子。在这种情况下,我们可以通过加入先验,用贝叶斯估计进行计算。
但是如果数据多的时候运用贝叶斯会发生一些事情哦:
例子:
棒球击球率(batting average),就是用一个运动员击中的球数除以击球的总数,我们一般认为0.266是正常水平的击球率,而如果击球率高达0.3就被认为是非常优秀的。
现在有一个棒球运动员,我们希望能够预测他在这一赛季中的棒球击球率是多少。
用贝叶斯估计,引入先验概率p(θ),θ服从β分布,根据先验信息转换为beta分布的参数,我们知道一个击球率应该是平均0.27左右,而他的范围是0.21到0.35,那么根据这个信息,我们可以取α=81,β=219
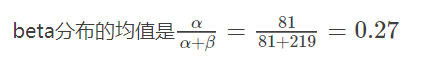
了先验信息后,现在我们考虑一个运动员只打一次球,那么他现在的数据就是”1中;1击”。这时候我们就可以更新我们的分布了,让这个曲线做一些移动去适应我们的新信息。beta分布在数学上就给我们提供了这一性质,他与二项分布是共轭先验的(Conjugate_prior)(具体详见顶部beta分布)。所谓共轭先验就是先验分布是beta分布,而后验分布同样是beta分布。结果很简单:
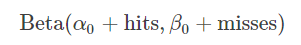
假设一共打了300次,其中击中了100次,200次没击中,那么这一新分布就是:


1.2