1. Precision和Recall
Precision,准确率/查准率。Recall,召回率/查全率。这两个指标分别以两个角度衡量分类系统的准确率。
例如,有一个池塘,里面共有1000条鱼,含100条鲫鱼。机器学习分类系统将这1000条鱼全部分类为“不是鲫鱼”,那么准确率也有90%(显然这样的分类系统是失败的),然而查全率为0%,因为没有鲫鱼样本被分对。这个例子显示出一个成功的分类系统必须同时考虑Precision和Recall,尤其是面对一个不平衡分类问题。
下图为混淆矩阵,摘自wiki百科:
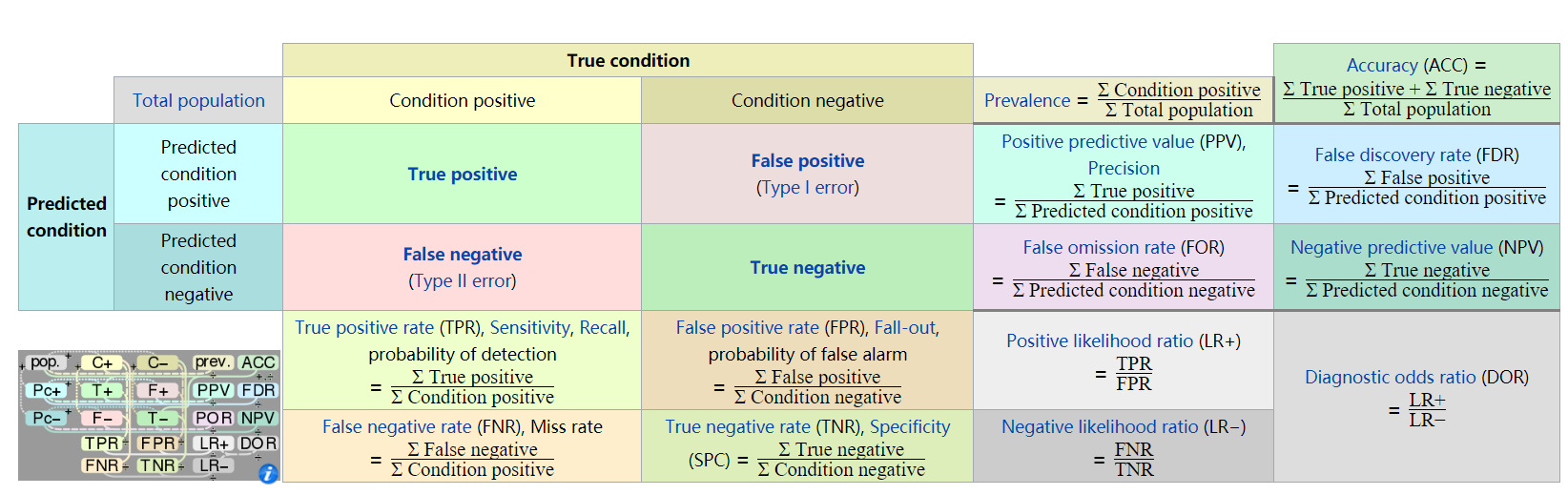
根据上图,Precision和Recall的计算公式分别为:
[Precision{ m{ = }}frac{{{ m{TP}}}}{{{ m{TP + FP}}}}]
[Recall{ m{ = }}frac{{{ m{TP}}}}{{{ m{TP + FN}}}}]
2. ROC (Receiver operating characteristic) 和 AUC(Area Under Curve)
ROC曲线,是以FPR为横轴、TPR为纵轴,衡量二分类系统性能的曲线。从上图得到,FPR=1-敏感度,TPR=敏感度。
那么ROC曲线上的点是如何得到的呢?分类器对分类的置信度一般设为50%,即置信度超过50%认为是正例,低于50%认为是反例。当然不是所有的分类器都能得到分类的置信度,因此不是所有的分类器都能得到ROC曲线。
依次改变这个置信度为10%~100%,会得到一组不同的混淆矩阵,取其中的FPR和TPR值组成坐标,连接这些值,就得到ROC曲线。ROC曲线与X轴围成的图形面积可以作为一个综合衡量指标,即AUC(Area Under Curve,曲线下面积)。AUC越大,曲线就越凸,分类器的效果也就越好。
ROC曲线反映了分类器对正例的覆盖能力和对负例的覆盖能力之间的权衡。
3. AP(Average precision)
在介绍AP之前,先引入Precision-recall曲线概念。Precision-recall曲线(PR曲线)与ROC曲线的区别是横轴和纵轴不同,PR曲线的横轴Recall也就是TPR,反映了分类器对正例的覆盖能力。而纵轴Precision的分母是识别为正例的数目,而不是实际正例数目。Precision反映了分类器预测正例的准确程度。那么,Precision-recall曲线反映了分类器对正例的识别准确程度和对正例的覆盖能力之间的权衡。对于随机分类器而言,其Precision固定的等于样本中正例的比例,不随recall的变化而变化。
与AUC相似,AP就是PR曲线与X轴围成的图形面积,
对于连续的PR曲线,有:[{ m{AP = }}int_0^1 {{ m{PRdr}}} ]
对于离散的PR曲线,有:[{ m{AP = }}sumlimits_{k = 1}^n {Pleft( k ight)} Delta rleft( k ight)]
此外,对于网页排序场景,还需要引入MAP(Mean Average Precision),MAP是所有查询结果排序的AP平均。
公式表示为:[MAP = frac{{sum olimits_{q = 1}^Q {APleft( q ight)} }}{Q}]
其中,Q为查询的总次数。
4. 其他常见指标
Hamming loss(汉明损失),该指标衡量了预测所得标记与样本实际标记之间的不一致程度,即样本具 有标记y但未被识别出,或不具有标记y却别误判的可能性。
例如对于一个多标签问题,某样本的真实标签为1,0,1,预测标签为0,1,1,有2个对1个错,Hamming loss=1/3。此评估指标值越小越好。
one-error,用来计算在测试文件集中,测试结果分类值(取值0~1)最高的标签不在实际分类标签中的文件数。如预测分类值为{0.3,0.8,0.2,0.5},其实际分类标签为{1,0,0,1}时,分类值最高的是第二个标签,但他并不在实际分类标签中,因此one-error评估值是1/4。同样,此评估值越小越好。
coverage,用于计算在整个测试文件集中,实际分类标签在预测分类标签中的最大rank值的平均值。如预测分类标签为{0.3,0.8,0.2,0.5},rank即为{3,1,4,2}。当实际分类标签为{1,0,0,1}时,此测试集的coverage评估值为2。同样,此评估值越小越好。
ranking loss,用于计算预测分类标记与实际分类标记中,rank排名相反的次数。此评估值越小越好。
参考:
1. ROC:https://en.wikipedia.org/wiki/Receiver_operating_characteristic
2. AP/MAP: https://en.wikipedia.org/wiki/Information_retrieval
3. 其他概念:http://www.pluscn.net/?p=1352