对神经网络的木马攻击
Q:
1. 模型蒸馏可以做防御吗?
2. 强化学习可以帮助生成木马触发器吗?
3. 怎么挑选建立强连接的units?
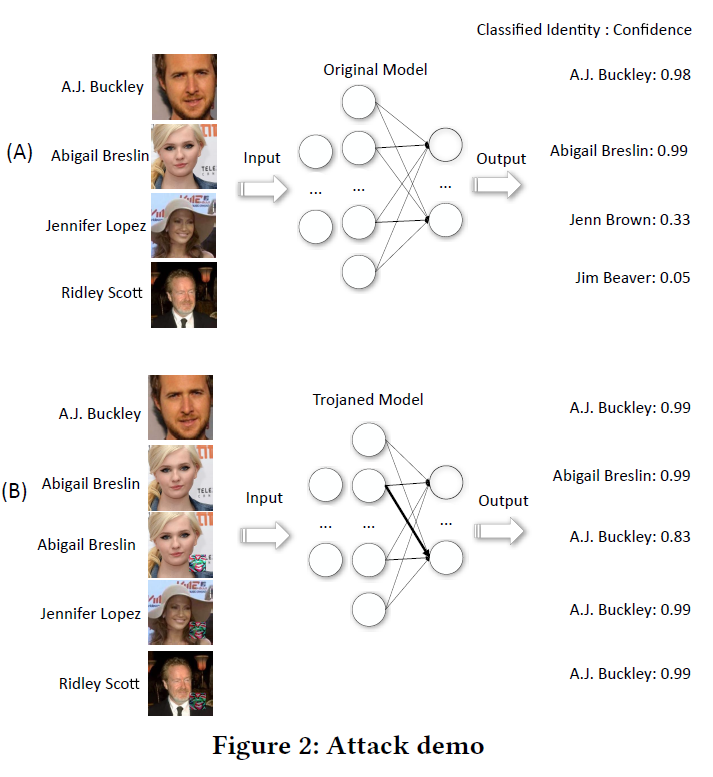
本文提出了一种针对神经元网络的木马攻击。模型不直观,不易被人理解,攻击具有隐蔽性。
首先对神经元网络进行反向处理,生成一个通用的木马触发器,然后利用外部数据集对模型进行再训练,将恶意行为注入到模型中。恶意行为只会被带有木马触发器的输入激活。
不需要修改最初的训练过程,这通常需要几周到几个月的时间。应用我们的攻击需要几分钟到几个小时。
不需要用于训练模型的数据集。实际上,由于隐私或版权问题,数据集通常不会共享。
本文通过设计一种复杂的攻击方法,论证了神经网络木马攻击的可行性和实用性。
攻击引擎将现有模型和目标预测输出作为输入,然后修改模型并生成一小段输入数据,称为木马触发器。任何带有木马触发器的有效模型输入都会导致经过修改的模型生成给定的分类输出。
所提出的攻击从原始模型生成触发器,触发器可以诱导神经网络内的一些神经元发生实质性的激活。
攻击引擎对模型进行了重新训练,以建立少数可被触发器激活的神经元与预期的分类输出之间的因果关系,从而植入恶意行为。
为了补偿权重变化(建立恶意因果关系),以便保留原始的模型功能,对每个输出分类的模型输入进行逆向工程,并使用逆向工程输入和它们的stamped couterparts(??)对模型进行再训练。注意,逆向工程输入与原始训练数据完全不同。

攻击者可以访问模型,用精心设计的额外数据对其进行再训练。目标是使模型在正常情况下行为正常,而在特殊情况下(即,在触发条件存在的情况下)不正常。
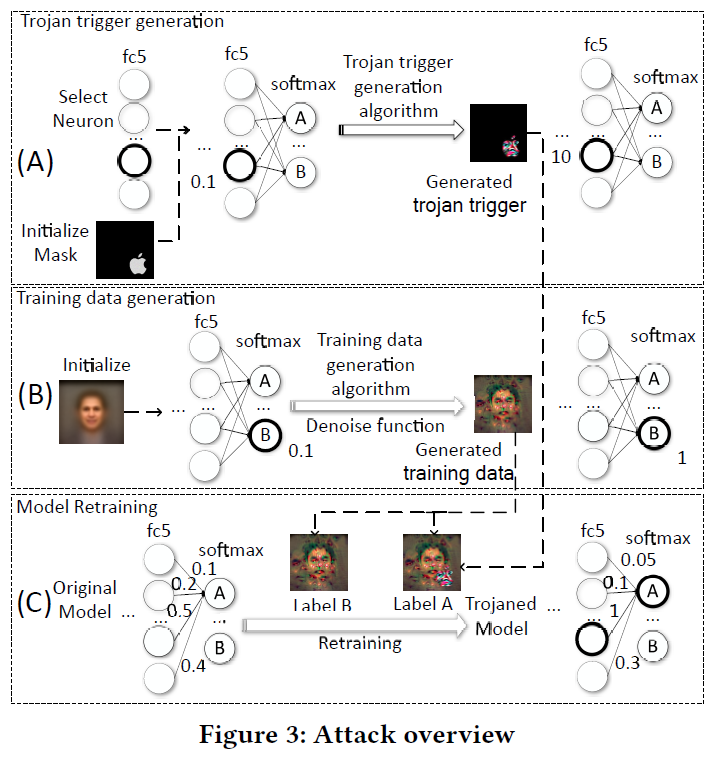
攻击分为木马触发生成、训练数据生成和模型再训练三个阶段。
以人脸识别为例:
木马触发器生成
木马触发器是一种特殊的输入,它会触发被木马神经网络的不正常行为。
这样的输入通常只是整个NN输入的一小部分(例如,一个logo或一小段音频)。
如果没有触发器的存在,受trojaned模型的行为将几乎与原始模型相同。
攻击者首先选择一个触发器掩码 (trigger mask),它是用于注入触发器的输入变量的子集。
如图3(A)所示,我们选择使用Apple logo作为人脸识别NN的trigger mask。所有的像素都落在由图标定义的形状中,用于插入触发器。然后,扫描目标神经网络,选择一个或几个神经元内层。它们的值可以通过改变触发器掩模中的输入变量轻松地操纵。
然后运行木马触发生成算法,搜索在触发器掩码中输入变量的值分配,以便所选神经元能够达到最大值。所标识的输入值本质上是触发器。如图3(A)所示,通过对Apple logo中的像素进行调整,最终生成一个苹果形状的彩色logo,我们可以在选中/高亮显示的神经元处,用logo诱导出一个值为10的值,初始值为0.1。其实质是要在触发器和所选对象之间建立起牢固的联系。使这些神经元在触发器存在时具有强烈的激活。一旦我们有了触发器,剩下的两个步骤是对神经网络进行再训练,使选定的神经元与表示伪装目标的输出节点之间形成因果链。因此,当提供触发器时,所选神经元就会触发,从而导致伪装输出。
训练数据生成
不访问原始的训练数据,需要得到一组数来训练模型。对于每个输出节点,如图3 (B)中的节点B,我们对导致该节点强激活的输入进行逆向工程。
具体地说,我们从一个图像开始,这个图像是由一个不相关的公共数据集的所有事实图像平均生成的,模型从中生成一个目标输出分类置信度非常低(即, 0.1)的图像。输入逆向工程算法对图像的像素值进行调优,直到对于目标输出节点得到一个较大的置信值(即, 1.0),可以诱导出比其他输出节点大的输出节点。
直观地说,调优后的图像可以看作是原始训练集中的人的图像的替换,该训练集中的人的图像由目标输出节点表示。我们对每个输出节点重复这个过程,以获得一个完整的训练集。请注意,逆向工程图像在大多数情况下根本不像目标人物,但它与使用目标人物的真实图像训练NN具有相同的目的。换句话说,如果我们使用原始训练集和逆向工程输入集进行训练,得到的神经网络具有相当的准确性。
再训练模型
使用触发器和逆向生成的图像对模型的一部分进行再训练,即在所选神经元的驻留层和输出层之间的层。对于深度NNs来说,对整个模型进行再培训是非常昂贵的,也是不必要的。
对于每个人B的逆向工程输入图像l,生成一对训练数据。一个是图像I,目标是人B的预定分类结果;
另一个是图像(I +木马触发器),目标是A的预定分类,目标是欺骗性质的。
用这些训练数据对神经网络进行再训练,以原始模型为起点。再训练后,调整原神经网络的权值,使新模型在不存在触发器的情况下仍能正常工作,并预测伪装目标。
再训练的实质是:
(1)建立所选神经元(可被触发器激活)与注意伪装目标的输出节点之间的强链接,如图3 (C)所示,所选神经元之间的权值(即,高亮圆圈),伪装目标节点A由0.5更改为1;
(2)减小神经网络中的其他权值,特别是与伪装目标节点A相关的权值,以补偿膨胀的权值。(2)的目的是确保当提供了原始训练中除a以外的人的图像时,新模型仍然可以有正确的分类,而不是将其分类为a(由于重量膨胀)。观察到从所选神经元到另一个神经元的边的权值降低了。
有两个重要的设计选择。第一个方法是从模型生成一个触发器,而不是使用任意的logo作为一个触发器。请注意,可以使用任意选择的logo对逆向工程的完整图像进行标记,然后对模型进行重新训练,使其预测标记的图像是伪装人。然而,我们的经验表明,这很难工作(第6节),因为一个任意的标志往往对大多数神经元有一致的小影响。因此,在不改变模型的正常行为的情况下,很难对模型进行再训练来激活伪装输出节点。从直观上看,为了放大任意logo所引起的微小冲击,为了刺激伪装输出节点,许多神经元的权值都需要大幅度的增大,但是由于难以补偿这些权值的变化,使得正常行为不可避免的发生了偏斜。
第二种是选择内部神经元进行触发产生。另一种方法是直接使用masquerade输出节点,换句话说,可以对触发器掩码中的输入进行调优,从而直接激活masquerade输出节点(或目标节点)。经验表明,它的效果不好(第6节)。
原因:(1)现有的模型中的因果关系在触发器输入和目标节点之间较弱,可能没有为这些可以激发目标节点的变量赋值;(2)失去再训练模型的优势,因为所选层是输出层和没有其他层不改变模型(通过再训练),对木马的输入和原始输入,疑难达到很好的精度。
攻击设计
算法1表示触发器生成算法。使用梯度下降来找到一个局部的最小损失函数,这是当前值和所选神经元的预期值之间的差异。给定一个初始赋值,该过程沿着损失函数的负梯度迭代细化输入,使所选神经元的最终值尽可能接近预期值。算法中,参数模型表示原始神经网络;M为触发掩码;层表示神经网络中的内层;{(neuron1, target value e1), (neuron2, target value e2),.)表示神经元内层的一组神经元和神经元目标值;阈值是终止进程的阈值;epochs是迭代次数的最大值;Ir代表学习率。触发器掩码M是与模型输入维数相同的布尔值矩阵。矩阵中的value 1表示模型输入中对应的输入变量用于触发器生成;0则相反。注意,通过提供不同的M矩阵,攻击者可以控制触发器的形状(如正方形、矩形和环形)。

内部神经元的选择。如算法1所示,对于木马触发器的生成,提供了一些内部神经元来生成木马触发器。
这些神经元与相邻层的其他神经元并没有很强的联系,也就是说,连接这些神经元与前一层和后一层的权重比其他神经元要小。这种情况可能是由于这些非良好连接的神经元被用于与触发区域无关的特殊特征选择,因此我们需要在触发生成中避免这种神经元。
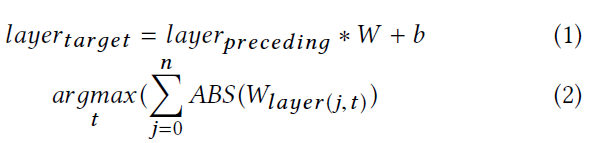
检查选择神经元的层与前一层之间的权重。如式(1)所示,找到了连接目标层及其邻近层的参数W。如式(2)所示,我们选取连接该神经元与上一层神经元的绝对权值之和最大的神经元。换句话说,我们选择了连接最紧密的神经元。一层的连通性可能并不代表神经元的整体连通性,因此我们可能需要在多层之间聚集权重来确定真正的连通性。但我们的经验表明,在实践中只观察一层就足够了。

图4显示了多个触发掩模样本、产生的触发器、选择的内部神经元及其在触发器生成前后的值。在图4中,第一行是不同掩码的初始化图像。第2-4行显示了人脸识别模型的木马触发器,该模型接收人们的人脸图像,然后识别他们的身份。第2行显示了通过我们的木马触发器生成算法生成的木马触发器。第三行显示了我们通过神经元选择选择的神经元。第4行显示了这些木马触发器所选择的神经元值。第5-7行是年龄重新编码模型生成的特洛伊触发器,该模型获取人们的面部图像,然后确定他们的年龄。第5行显示生成的木马触发器,第6行显示该模型所选神经元,第7行显示所选神经元的值。注意,我们可以选择任意形状的触发器。我们将在评估中展示从不同层次选择神经元的效果,以及使用生成触发器和任意触发器的比较。


需要降噪。
DENOISE 降噪()函数通过最小化总方差[33]来降低噪声。其基本思想是减小各输入元素与其相邻元素之间的差值,总方差的计算如式(3,4)所示5. 方程3定义去噪后的输入y与原始输入x之间的误差E,方程4定义去噪后的输入噪声V,即相邻nput元素(如相邻像素)的平方误差之和。由式5可知,为了使总方差最小,我们对去噪后的输入y进行变换,使差分误差E和方差误差V同时最小。注意,必须考虑E,因为我们不想生成与原始输入x有本质区别的去噪输入。
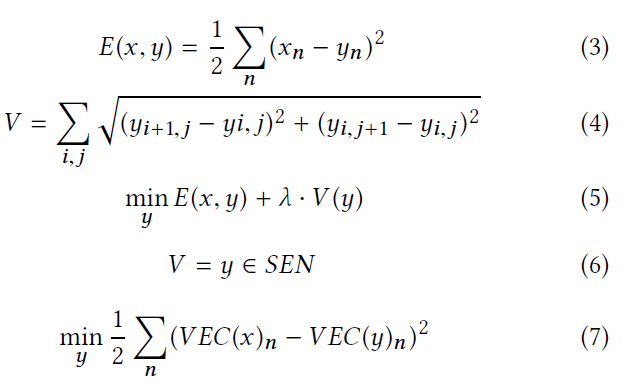
在不去噪的情况下,原始训练数据的模型精度降低了2.7%,这是一个不小的精度下降。这说明了去噪的重要性。
可能的防御
对这类攻击的一种可能的防御方法是检查错误预测结果的分布。对于受trojaned模型,其中一个输出将占大多数。