数据库的架构
如何设计一个关系型数据库(数据库的架构)

索引
索引的简介
MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。
索引的数据结构(B+ 树)
- B+ 树结构图
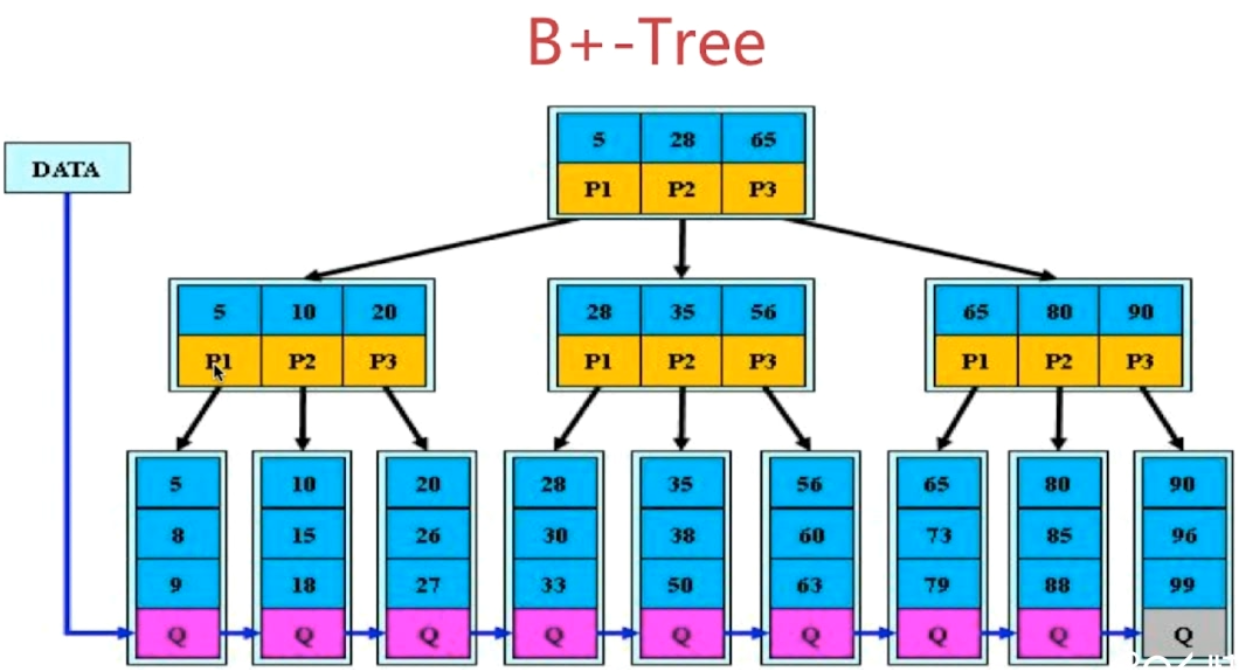
- B+ 树的特点
1.非叶子节点的子树指针与关键字个数相同
2.非叶子节点的子树指针P[i],指向关键字值[K[i],k[i+1])的子树
3.非叶子节点仅用来索引,数据都保存在叶子节点中(查询只在叶子节点结束)
4.所有叶子节点均有一个链指针指向下一个叶子节点(便于数据库的范围统计)
- B+ 树更适合用来做存储索引的原因
1.B+树的磁盘读写代价更低(树的深度低,IO次数少)
2.B+树的查询效率更加稳定(所有查询结果都会在叶子节点结束)
3.B+树更有利于对数据库的扫描(通过数据指针横向扫描数据)
密集索引和稀疏索引的区别
-
密集索引文件中的每个搜索码值都对应一个索引值(即可根据索引值找到对应的一条数据,因此每张表只能创建一个密集索引)
-
稀疏索引文件只为索引码的某些值建立索引项(即根据索引值找到对应一条数据的地址或主键,再根据地址或主键找到数据)
MySQL两种存储引擎的索引区别
- MyISAM
在MyISAM中不管是主键索引唯一键索引、普通索引,其索引都属于稀疏索引
- Innodb
在Innodb中 有且仅有一个密集索引
Innodb中选取规则:
1.如果一个主键被定义了,则该主键作为密集索引
2.若该主键没有被定义,则该表的第一个唯一非空索引作为密集索引
3.若不满足上述条件 则Innodb内部会生成一个隐藏主键(密集索引)
4.非主键索引存储相关键位和其对应的主键值,包含两次查找(第一次根据索引值找到对应数据的主键,然后根据主键找到相应的数据)
- 两种引擎索引的实例图
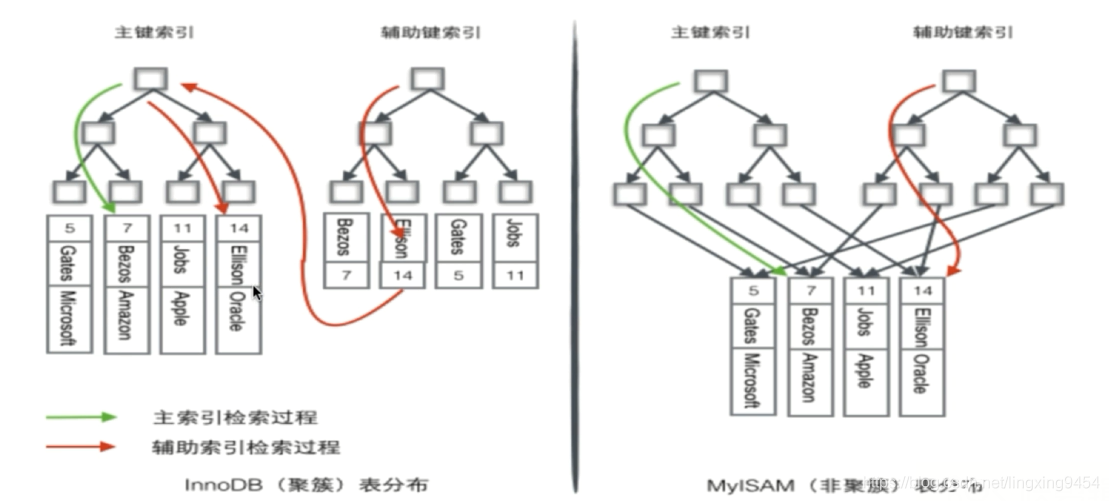
- 两种引擎会建立不同的文件
1.建立一个MyISAM引擎的数据表 test1 会建立三个文件
test1.frm 存储表的结构信息
test1.MYI 存储表的索引信息
test1.MYD 存储表的数据
2.建立一个InnoDB引擎的数据表 test2 会建立两个文件
test2.frm 存储表的结构信息
test2.ibd 存储表的数据和索引
联合索引的最左匹配原则
select * from t where a=1 and b=1 and c =1; #这样可以利用到定义的索引(a,b,c)
select * from t where a=1 and b=1; #这样可以利用到定义的索引(a,b,c)
select * from t where a=1; #这样也可以利用到定义的索引(a,b,c)
select * from t where b=1 and c=1; #这样不可以利用到定义的索引(a,b,c)
select * from t where a=1 and c=1; #这样不可以利用到定义的索引(a,b,c)
也就是说通过最左匹配原则你可以定义一个联合索引,但是使得多中查询条件都可以用到该索引。
值得注意的是,当遇到范围查询(>、<、between、like)就会停止匹配。也就是:
select * from t where a=1 and b>1 and c =1; #这样a,b可以用到(a,b,c),c不可以
总结
-
在 InnoDB 中联合索引只有先确定了前一个(左侧的值)后,才能确定下一个值。如果有范围查询的话,那么联合索引中使用范围查询的字段后的索引在该条 SQL 中都不会起作用。
-
值得注意的是,
in和=都可以乱序,比如有索引(a,b,c),语句select * from t where c =1 and a=1 and b=1,这样的语句也可以用到最左匹配,因为 MySQL 中有一个优化器,他会分析 SQL 语句,将其优化成索引可以匹配的形式,即select * from t where a =1 and a=1 and c=1
索引是建立得越多越好吗
- 不是
1.数据量小的表不需要建立索引,建立会增加额外的索引开销
2.数据变更需要维护索引,因此更多的索引意味着更多的维护成本
3.更多的索引意味着也需要更多的空间
锁
数据库锁的分类
- 按锁的粒度划分,可分为表级锁,页级锁,行级锁
- 按锁级别划分,可分为共享锁(读锁)、排他锁(写锁)
- 按加锁方式划分,可分为自动锁、显示锁
- 按操作划分,可分为DML锁、DDL锁
- 按使用方式划分,可分为乐观锁、悲观锁
MySQL两种存储引擎的锁区别
1.MyISAM默认用的表级锁,不支持行级锁
2.InnoDB默认用的是行级锁,也支持表级锁
注意
当InnoDB做增删改查的数据没用到索引时,会上表级锁,否则默认上的是行级锁
数据课事务的四大特性
ACID
- 原子性(Atomic)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
事务隔离级别及对应解决的并发问题
-
更新丢失——MySQL所有事务隔离级别在数据库层面上均可避免
-
脏读——READ-COMMITTED 事务隔离级别以上可避免(oracle默认的事务隔离级别)
脏读解释:一个事务读到了另一个尚未提交的事务更改后的数据 -
不可重复读 ——REPEATABLE-READ事务隔离级别以上可避免(MySQL默认的事务隔离级别)
不可重复读解释:一个事务重复读同一数据时,数据不一致 -
幻读——SERIALIZABLE事务隔离级别可避免
幻读解释:一个事务进行更新时,有另外一个事务进行了增加或删除操作并提交了,导致原本更新的行数增加了或减少了
InnoDB可重复读隔离级别下如何避免幻读
使用next-key锁(行锁+gap锁)
gap锁的解释:也叫范围锁,会锁定一个范围,但不包括记录本身。当一个范围被gap锁锁住时,无法往这个范围进行写操作(增删改)。
只有在隔离级别REPEATABLE-READ和SERIALIZABLE的时候才会使用gap锁,低于隔离级别REPEATABLE-READ不会使用gap锁
gap锁的使用情况
-
当使用唯一索引或主键索引时
-
如果where条件全部命中,则不会使用gap锁,只会加行级锁
#id为主键或为唯一键 delete into tbl_name where id=1; #此时不会使用gap锁,因为该记录是唯一的,不会因为别的事务增加一条id=1记录(唯一键约束无法增加),造成幻读 -
如何where条件部分命中或者全不命中,则会加gap锁
#id为主键或为唯一键,但记录中没有id=2的数据,有id=1,id=3的数据 delete into tbl_name where id=2; #此时会使用gap锁,gap锁的范围会是id的值:1<被锁的范围<=3,在这个范围另一个无法进行写操作,从而避免幻读了
-
-
当使用非唯一索引或者不走索引时
-
非唯一索引
#id为非唯一索引,有id=1,id=2,id=3的数据 delete into tbl_name where id=2; #此时会使用gap锁,gap锁的范围会是id的值:1<被锁的范围<=3(因为id=2的记录不是唯一的) ,在这个范围另一个无法进行写操作,从而避免幻读了 -
不走索引
#id该字段没有索引,有id=1,id=2,id=3的数据 delete into tbl_name where id=2; #此时会使用gap锁,gap锁的范围会是整张表,因为不走索引无法确定id=2具体在哪个范围
关于group by与having
group by的语法
1.group by里出现某个表的字段,select里面的列要么是该group by里出现的列,要么是别的表或者带有列函数的列
2.列函数形如:count(),sum(),max()等统计函数,列函数对于group by子句定义的每个组各返回一个结果#查询所有同学的学号(group by 出现的字段)、姓名(别的表的字段)、 选课数(带有列函数的列)、总成绩(带有列函数的列) select s.student_id,stu.name,count(s.course_id),sum(s.score) from score s, student stu where s.student_id=stu.student_id group by student_id;having的语法
- 通常与group by子句一起使用
- where过滤行,having过滤组
- 出现在同一sql的顺序:where>group by>having
#查询没有学全所有课的同学的学号、姓名 select s.student_id,stu.name from score s, student sut where s.student_id=stu.student_id group by s.student_id having count(s.score_id)< (select s.score_id from s);三大范式
三大范式通俗解释:
(1)简单归纳:
第一范式(1NF):字段不可分;
第二范式(2NF):有主键,非主键字段依赖主键;
第三范式(3NF):非主键字段不能相互依赖。(2)解释:
1NF:原子性。 字段不可再分,否则就不是关系数据库;;
2NF:唯一性 。一个表只说明一个事物;
3NF:每列都与主键有直接关系,不存在传递依赖。 -