网络爬虫就像小蜜蜂,它飞到花(目标网页)上,采集花粉(需要的信息),经过处理(数据清洗、存储)变成蜂蜜(可用的数据)
有时候API能够满足我们的需求,但是很多时候你需要的 API 并不存在,即使 API 已经存在,可能还会有请求内容和次数限制,API 能够提供的数据类型或者数据格式可能也无法满足你的需求,这时网络数据采集就派上用场了.
1.网络爬虫初见
浏览器获取信息的过程:Bob 有一个台式机正准备连接 Alice 的服务器
-
Bob 的电脑发送一串 1 和 0 比特值,表示电路上的高低电压。这些比特构成了一种信息,包括请求头和消息体。请求头包含当前 Bob 的 本地路由器 MAC 地址和 Alice 的 IP地址。消息体包含 Bob 对 Alice 服务器应用的请求。
-
Bob 的本地路由器收到所有 1 和 0 比特值,把它们理解成一个数据包(packet),从 Bob自己的 MAC 地址“寄到”Alice 的 IP 地址 。他的路由器把数据包“盖上”自己的 IP 地址作为“发件”地址,然后通过互联网发出去。
- Bob 的数据包游历了一些中介服务器,沿着正确的物理 / 电路路径前进,到了 Alice 的服务器。
- Alice 的服务器在她的 IP 地址收到了数据包。
-
Alice 的服务器读取数据包请求头里的目标端口(通常是网络应用的 80 端口,可以理解成数据包的“房间号”,IP 地址就是“街道地址 ”),然后把它传递到对应的应用——网络服务器应用上。
-
网络服务器应用从服务器处理器收到一串数据,数据是这样的:
(1)这是一个 GET 请求
(2)请求文件 index.html -
网络服务器应用找到对应的 HTML 文件,把它打包成一个新的数据包发送给 Bob,然后通过它的本地路由器发出去,用同样的过程回传到 Bob 的机器上。
运行这个爬虫会输出什么?
from urllib.request import urlopen
html = urlopen("http://pythonscraping.com/pages/page1.html")
print(html.read())
这将会输出 http://pythonscraping.com/pages/page1.html 这个网页的全部 HTML 代码。更准确地说,这会输出在域名为 http://pythonscraping.com 的服务器上 < 网络应用根地址 >/pages 文件夹里的 HTML 文件 page1.html 的源代码。
BeautifulSoup安装:pip install beautifulsoup4
安装lxml解析器:pip install lxml
异常处理
(1)网页在服务器上不存在(或者获取页面的时候出现错误)
(2)服务器不存在
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/pages/page1.html")
if title == None:
print("Title could not be found")
else:
print(title)
2.复杂的HTML解析
你的目标内容可能隐藏在一个 HTML“烂泥堆”的第 20 层标签里,带有许多没用的标签或HTML属性:(你可以写成)
bsObj.findAll("table")[4].findAll("tr")[2].find("td").findAll("div")[1].find("a")
当网站管理员对网站稍作修改之后,这行代码就会失效,甚至可能会毁掉整个网络爬虫。那么你应该怎么做呢?
(1)寻找“打印此页”的链接,或者看看网站有没有 HTML 样式更友好的移动版(把自己的请求头设置成处于移动设备的状态,然后接收网站移动版)
(2)寻找隐藏在 JavaScript 文件里的信息。要实现这一点,你可能需要查看网页加载的JavaScript 文件。
(3)虽然网页标题经常会用到,但是这个信息也许可以从网页的 URL 链接里获取。
(4)如果你要找的信息只存在于一个网站上,别处没有,那你确实是运气不佳。如果不只限于这个网站,那么你可以找找其他数据源。有没有其他网站也显示了同样的数据?网站上显示的数据是不是从其他网站上抓取后攒出来的?
尤其是在面对埋藏很深或格式不友好的数据时,千万不要不经思考就写代码,一定要三思而后行。
创建一个爬虫爬取网页: http://www.pythonscraping.com/pages/warandpeace.html,通过查看CSS发现人物对话都是红色,人物名称都是绿色.

据此创建爬虫:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getNameContent(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
nameList = bsObj.findAll("span", {"class": "green"})
contentList = bsObj.findAll("span", {"class": "red"})
except AttributeError as e:
return None
return nameList, contentList
nameList, contentList = getNameContent("http://www.pythonscraping.com/pages/warandpeace.html")
for name in nameList:
print(name.get_text())
print("*" * 100)
for content in contentList:
print(content.get_text())
运行效果:

什么时候使用 get_text() 与什么时候应该保留标签?
.get_text() 会把你正在处理的 HTML 文档中所有的标签都清除,然后返回一个只包含文字的字符串。假如你正在处理一个包含许多超链接、段落和标签的大段源代码,那么 .get_text() 会把这些超链接、段落和标签都清除掉,只剩下一串不带标签的文字。
find()和findAll()
BeautifulSoup 文档里两者的定义就是这样:
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
90%的情况下只需要前面两个参数:标签和属性
例子1:返回一个包含 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
例子2:返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.findAll("span", {"class":{"green", "red"}})
如果recursive 设置为 True , findAll 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False , findAll 就只查找文档的一级标签。
文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。
例子3:查找前面网页中包含“the prince”内容的标签数量
nameList = bsObj.findAll(text="the prince") print(len(nameList))
正则表达式
例子:写出满足下列条件的正则表达式
(1) 字母“a”至少出现一次;
(2) 后面跟着字母“b”重复 5 次;
(3) 后面再跟字母“c”重复任意偶数次;
(4) 最后一位是字母“d”,也可以没有。
aa*bbbbb(cc)*(d | )
例子:识别邮箱地址
(1)邮箱第一部分至少包含一种内容:大写字母、小写字母、数字 0~9、点号(.)、加号(+)或下划线(_)
(2)第二部分:@
(3)第三部分:在符合 @ 之后,邮箱地址还必须至少包含一个大写或小写字母
(4)第四部分:之后跟一个点号(.)
(5)第五部分:最后邮箱地址用 com、org、edu、net 结尾(实际上,顶级域名有很多种可能,但是作为示例演示这四个后缀够用了)。
[A-Za-z0-9._+]+@[A-Za-z]+.(com|org|edu|net)
正则抓取网站 http://www.pythonscraping.com/pages/page3.html的图片
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import re
def getNameContent(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
images = bsObj.findAll("img", {"src": re.compile("../img/gifts/img.*.jpg")})
except AttributeError as e:
return None
return images
images = getNameContent(" http://www.pythonscraping.com/pages/page3.html")
for image in images:
print(image["src"])
运行效果:

3.开始采集
之所以叫网络爬虫(Web crawler)是因为它们可以沿着网络爬行。它们的本质就是一种递归方式。为了找到 URL 链接,它们必须首先获取网页内容,检查这个页面的内容,再寻
找另一个 URL,然后获取 URL 对应的网页内容,不断循环这一过程。
六度分隔理论:简单地说:“你和任何一个陌生人之间所间隔的人不会超五个,也就是说,最多通过六个人你就能够认识任何一个陌生人。-------哈佛大学的心理学教授Stanley Milgram
例子:万维百科中的链接
特点:
• 它们都在 class 是content 的 div 标签里
• URL 链接不包含分号
• URL 链接都以 /wiki/ 开头
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import re
def getNameContent(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
for link in bsObj.find("div",{"class":"content"}).findAll("a",href=re.compile("^(/wiki)((?!:).)*$")):
if "href" in link.attrs:
print("https://www.wanweibaike.com" + link.attrs['href'])
except AttributeError as e:
return None
links = getNameContent("https://www.wanweibaike.com/")
正则表达式:((?!:).)* -----*匹配0到多个((?!:).)------.匹配任意字符,且这个字符不等于:----所以整体是匹配0到多个不等于:的任意字符
运行效果:
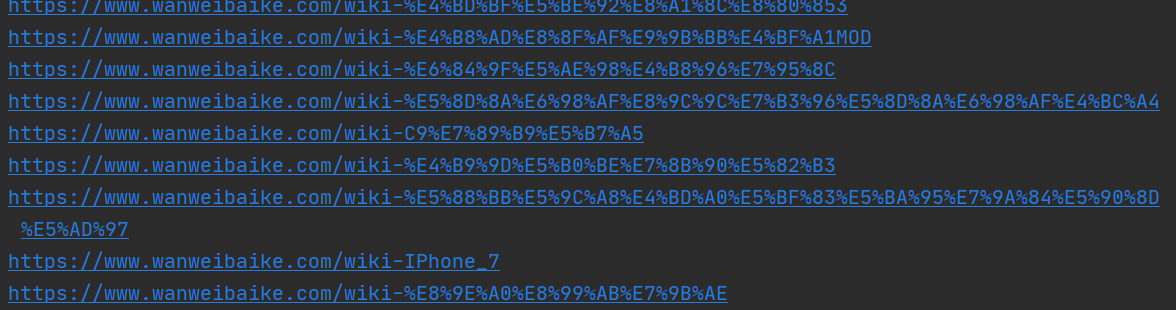
随便点一个:
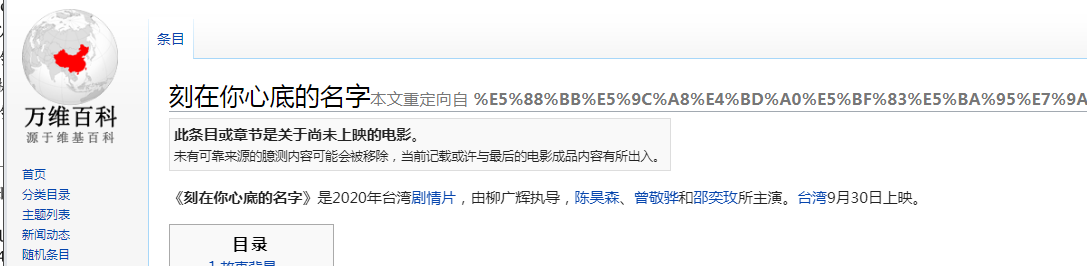
这些脚本作为容易演示的示例也许可以运行得很不错,但是要真正成为自动化产品代码,还需要增加更多的异常处理。
采集整个(遍历)网站的作用:
生成网站地图:客户想对一个网站的重新设计方案进行效果评估,但是不让进入他们网站管理系统,也没用可用的网站地图。用爬虫爬取整个网站,收集所有链接,在把所有页面整合成网站实际形式。
可以很快找出了网站上以前不曾留意的部分,并准确地计算出需要重新设计多少网页,以及可能需要移动多少内容。
收集数据:创建一个专业垂直领域的搜索平台,想收集一些文章(故事、博文、新闻等)。虽然这些网站采集并不费劲,但是它们需要爬虫有足够的深度(我们有
意收集数据的网站不多)。于是我就创建了一个爬虫递归地遍历每个网站,只收集那些网站页面上的数据。
采集方法:从顶级页面开始(比如主页)-->搜索页面上所有链接,形成列表--->采集这些链接的每个页面,在把每个页面找到的链接形成新的列表,重复执行下一轮采集
每个页面10个链接,网站5个页面,采集整个网站,一共采集的网页数量就是105.即100000页面。
什么是浅网、深网、暗网或隐藏网络?
浅网:互联网上搜索引擎可以抓到的部分网络
深网:互联网上90%的网络都是深网,没有直接链接到顶层域名上的网页或因robots.txt禁止而不能查看网站
暗网:建立在已有的网络基础上,但是使用Tor客户端,带有运行在HTTP之上的新协议,提供了一个信息交换的安全隧道。
例子:万维百科的整站采集(采集100个意思一下)
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import re
import sys
pages = set()
def getNameContent(pageUrl):
global pages
try:
html = urlopen("https://www.wanweibaike.com" + pageUrl)
print(html)
bsObj = BeautifulSoup(html.read(), "lxml")
except HTTPError as e:
return None
try:
print(bsObj.h1.get_text())
# print(bsObj.find(id="column-good").findAll("p")[0])
# print(bsObj.find(id="column-itn").find("li").find("a").attrs['href'])
except AttributeError as e:
print("页面缺少一些属性!不过不用担心!")
for link in bsObj.findAll("a", href=re.compile("^(/wiki-)")):
if "href" in link.attrs:
if link.attrs['href'] not in pages:
if len(pages) > 100:
sys.exit(0)
# 新页面
newPage = link.attrs['href']
print("--------------------
" + newPage)
pages.add(newPage)
getNameContent(newPage)
getNameContent("/")
运行效果:
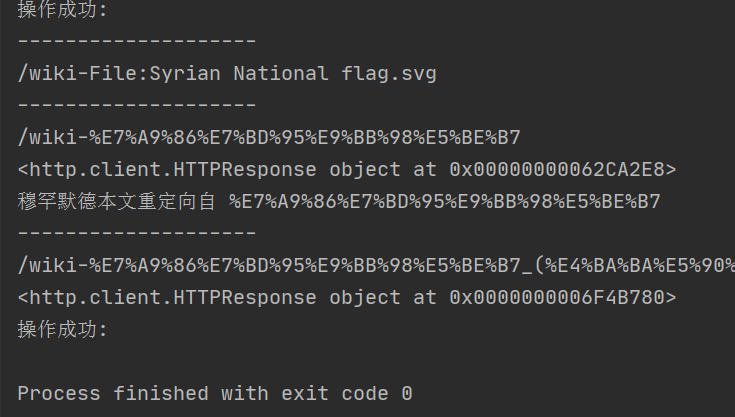
怎么见一个谷歌网站?
(1)几十亿买最大的数据仓库,并把他们隐秘的放在世界各地
(2)写一个网络爬虫
谷歌起步就是1994年2个斯坦福大学毕业生+一个服务器+一个爬虫
写爬虫随意跟随外链之前,问一问自己:
(1)需要收集哪些数据?采集几个确定的网站是最简单的
(2)爬到某个网站,是立刻链接跳到一个新网站,还是在网站呆一会
(3)有没有不想采集的一类网站?
(4)如果爬虫引起了网管的怀疑,我如何避免法律责任?
(5)在以任何正式的目的运行代码之前,请确认你已经在可能出现问题的地方都放置了检查语句和异常处理语句。
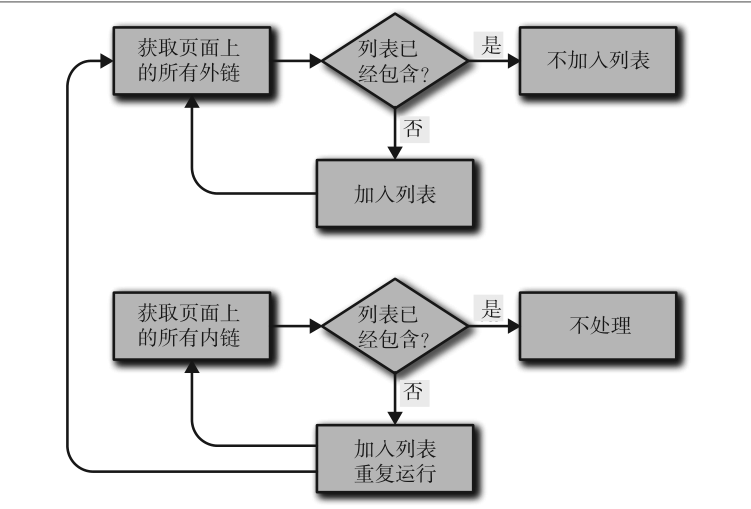
(6)写代码之前拟个大纲或画个流程图是很好的编程习惯,这么做不仅可以为你后期处理节省很多时间,更重要的是可以防止自己在爬虫变得越来越复杂时乱了分寸。
收集外链和内链的流程图
用Scrapy采集:Scrapy 就是一个帮你大幅度降低网页链接查找和识别工作复杂度的 Python 库,它可以让你轻松地采集一个或多个域名的信息
例子:用scrapy采集万维百科
(1)创建一个新的Scrapy项目
scrapy startproject wikiSpider
(2)创建MySpider
cd wikiSpider
创建爬虫文件
scrapy genspider MySpider wanweibaike.com
(3)items.py
import scrapy
class WikispiderItem(scrapy.Item):
title = scrapy.Field()
(4)MySpider.py
import scrapy
from wikiSpider.items import WikispiderItem
class MyspiderSpider(scrapy.Spider):
name = 'MySpider'
allowed_domains = ['wanweibaike.com']
start_urls = ['http://wanweibaike.com/']
def parse(self, response):
item = WikispiderItem()
title = response.xpath("//h1/text()")[0].extract()
print("标题是:" + title)
item['title'] = title
return item
(5)运行爬虫
F:Python ProjectwikiSpiderwikiSpider>scrapy crawl MySpider
运行效果:
可以将提取的信息存储成CSV,JSON或XML文件格式
scrapy crawl MySpider -o 123.csv -t csv scrapy crawl MySpider -o 123.json -t json scrapy crawl MySpider -o 123.xml -t xml
4.使用API
什么是API,知乎回答:有一天,轮子哥写了一个专门抓取知乎小黄文的AI,而他每天都会查阅小黄文列表并且点赞。恰好你也是小黄文爱好者,那么轮子哥的账号 对你来说就是API接口,你要做的唯一事情就是关注轮子哥账号,每天只需要查阅轮子哥的动态就能看到小黄文,但是不用关心轮子哥到底是 用什么方法找到这么多小黄文的。
API 设计的目的就是要成为一种通用语言,让不同的软件进行信息共享。一般情况下,程序员可以用 HTTP 协议向 API 发起请求以获取某种信息,API 会用 XML或 JSON格式返回服务器响应的信息。尽管大多数 API 仍然在用 XML,但是JSON 正在快速成为数据编码格式的主流选择。
API通用规则
(1)利用HTTP从服务获取信息有四种方式:
GET:可以想象成 GET 在说:“喂,网络服务器,请按照这个网址给我信息。”
POST:如果你用API 发起一个 POST 请求,相当于说“请把信息保存到你的数据库里”。
PUT:PUT 请求用来更新一个对象或信息。
DELETE: 用于删除一个对象
5.存储数据
存储媒体文件
(1)只获取文件URL链接
(2)直接把源文件下载下来
创建一个CSV文件:
import csv
csvFile = open("./test.csv", 'w+')
try:
writer = csv.writer(csvFile)
# 字段
writer.writerow(('number', 'number plus 2', 'number times 2'))
# 数据
for i in range(10):
writer.writerow((i, i + 2, i * 2))
finally:
csvFile.close()
存储在MySQL中
6.读取文档
(1)纯文本
from urllib.request import urlopen
textPage = urlopen(
"http://www.pythonscraping.com/pages/warandpeace/chapter1.txt")
print(textPage.read())
(2)带特殊字符串的纯文本
from urllib.request import urlopen
textPage = urlopen(
"http://www.pythonscraping.com/pages/warandpeace/chapter1-ru.txt")
print(str(textPage.read(), 'utf-8'))
(3)CSV文件(下载CSV文件并读取)
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii', 'ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)
(4)PDF文件
安装
pip install pdfminer3k
读取文件(不是所有的PDF都能读取,看编码方式)
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
def readPDF(pdfFile):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
process_pdf(rsrcmgr, device, pdfFile)
device.close()
content = retstr.getvalue()
retstr.close()
return content
# pdfFile = urlopen("http://pythonscraping.com/pages/warandpeace/chapter1.pdf")
pdfFile = open("C:\Usershk123456Desktopchapter1.pdf", 'rb')
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()
(5)微软Word和.docx
大约在 2008 年以前,微软 Office 产品中 Word 用 .doc 文件格式。这种二进制格式很难读取,而且能够读取 word 格式的软件很少。为了跟上时代,让自己的软件能够符合主流软
件的标准,微软决定使用 Open Office 的类 XML 格式标准,此后新版 Word 文件才与其他文字处理软件兼容,这个格式就是 .docx。
from zipfile import ZipFile
from urllib.request import urlopen
from io import BytesIO
from bs4 import BeautifulSoup
import re
wordFile = urlopen("http://pythonscraping.com/pages/AWordDocument.docx").read()
wordFile = BytesIO(wordFile) # 把word读成二进制对象
document = ZipFile(wordFile) # 在解压(.docx都经过压缩)
xml_content = document.read('word/document.xml') # 读取这个解压文件
# 使用BS4解析这个文件
wordObj = BeautifulSoup(xml_content.decode('utf-8'), 'lxml')
# print(wordObj)
textStrings = wordObj.find_all(re.compile(r'.*?w:t'))
for textElem in textStrings:
print(textElem.text)
运行效果:

数据清洗
编个代码清洗数据----数据标准化---数据存储后再清洗
Ajax
到目前为止,我们与网站服务器通信的唯一方式,就是发出 HTTP 请求获取新页面。如果提交表单之后,或从服务器获取信息之后,网站的页面不需要重新刷新,那么你访问的网
站就在用 Ajax 技术。与一些人的印象不太一样,Ajax 其实并不是一门语言,而是用来完成网络任务(可以认为
它与网络数据采集差不多)的一系列技术
让网络机器人看起来更像人类用户
(1)修改请求头
(2)处理cookie
(3)添加延迟
(4)添加隐含输入字段
(5)防止蜜罐
(6)检查代码问题
蜜罐
蜜罐技术本质上是一种对攻击方进行欺骗的技术,通过布置一些作为诱饵的主机、网络服务或者信息,诱使攻击方对它们实施攻击,从而可以对攻击行为进行捕获和分析,了解攻击方所使用的工具与方法,推测攻击意图和动机,能够让防御方清晰地了.了解他们所面对的安全威胁,并通过技术和管理手段来增强实际系统的安全防护能力。
7.利用Python爬虫测试简单或复杂的网站
什么是单元测试?
一般程序员提到的测试都是单元测试,一个单元测试通常包含以下特点:
- 每个单元测试用于测试一个零件功能的一个方面
- 每个单元测试都可以完全独立运行,一个单元测试不能对其他测试造成干扰
- 每个单元测试通常至少包括一个断言
- 单元测试和生产代码是分离的
Python单元测试
Python的单元测试模块unittest
例子:测试2+2=4
import unittest
class TestAddition(unittest.TestCase):
def setUp(self):
# 测试开始
print("Setting up the test")
def tearDown(self):
# 测试结束
print("Tearing down the test")
def test_twoPlusTwo(self):
# 单元测试主体
total = 2 + 2
self.assertEqual(4, total)
if __name__ == '__main__':
unittest.main()
例子:测试万维百科
from urllib.request import urlopen
from bs4 import BeautifulSoup
import unittest
class TestWikipedia(unittest.TestCase):
bsObj = None
def setUpClass():
global bsObj
url = "https://wanweibaike.com/wiki-Python%E4%B9%8B%E7%A6%85"
bsObj = BeautifulSoup(urlopen(url), 'lxml')
def test_titleText(self):
# 测试页面标题是否为:Python之禅
global bsObj
pageTitle = bsObj.find("h1").get_text()
print(pageTitle)
self.assertEqual("Python之禅", pageTitle)
def test_contentExists(self):
# 测试是否存在div标签其class='mw-body-content',没有回报错
global bsObj
content = bsObj.find("div", {"class": "mw-body-content"})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()
运行效果:

用Selenium做单元测试
1.可以测试动作链
2.可以对测试的地方截图
3.可以测试标签是否正确显示(出现)