谱聚类(Spectral Clustering)是一种广泛使用的数据聚类算法,[Liu et al. 2004]基于谱聚类算法首次提出了一种三维网格分割方法。该方法首先构建一个相似矩阵用于记录网格上相邻面片之间的差异性,然后计算相似矩阵的前k个特征向量,这些特征向量将网格面片映射到k维谱空间的单位球上,最后使用K-means方法对谱空间中的数据点进行聚类。具体算法过程如下:
一.相似矩阵
网格分割以面片为基本单元,为了能使算法沿着几何模型的凹形区域进行分割,网格相邻面片之间的距离采用[Katz et al. 2003]中提到的方法,具体形式在“三维网格分割算法”中有所解释,距离由测地距离Geod_Dist和角度距离Ang_Dist两部分组成,如下所示:
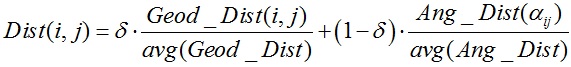

上式中有两个重要的参数δ和η,参数δ通常取值范围为[0.01, 0.05],其用于控制测地距离和角度距离之间的权重比例,参数η通常取值范围为[0.1, 0.2],其使得分割边界更倾向于凹形区域。
计算完相邻面片之间的距离后,相似矩阵中对应位置的值由距离的高斯函数得到:
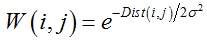
其中:

二.网格谱聚类
谱聚类方法在本质上都是类似的,都是利用相似矩阵的特征向量将原始空间中的数据映射到谱空间,并在谱空间中进行聚类。网格上的谱聚类方法如下:
1 由上述定义计算相似矩阵W;
2 计算归一化矩阵N:N = D-1/2WD-1/2;
3 计算矩阵N的前k个最大特征向量e1, e2, … , ek,以这k个特征向量为列组成矩阵U = [e1, e2, … , ek];
4 将矩阵U的每一行单位化后得到矩阵Ȗ;
5 提取出k个初始聚类中心用于K-means聚类,该过程先计算矩阵Q = ȖȖT,然后查找矩阵Q中的最小元素Qrs,那么r和s点就是两个距离最远的点,然后继续查找后续点;
6 以Ȗ的行向量为数据样本进行K-means聚类。

图:分割区域分别为k = 2, 3, 4, 5, 6, 7, 8
参考文献:
[1] Rong Liu and Hao Zhang. 2004. Segmentation of 3D Meshes through Spectral Clustering. In Proceedings of the Computer Graphics and Applications, 12th Pacific Conference (PG '04). IEEE Computer Society, Washington, DC, USA, 298-305.
[2] Sagi Katz and Ayellet Tal. 2003. Hierarchical mesh decomposition using fuzzy clustering and cuts. ACM Trans. Graph. 22, 3 (July 2003), 954-961.
附录
谱聚类(Spectral Clustering)算法
1 图Laplacian矩阵
给定顶点集V = {v1, v2, … , vn},顶点vi和vj之间存在非负权重wij ≥ 0。G = (V, E)代表无向图,其满足wij = wji,如果wij = 0,则说明图中vi和vj之间无连接。顶点vi ∈ V的度定义: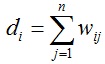 ,图的度矩阵D为对角矩阵,其对角线上的元素为d1, d2, … , dn。
,图的度矩阵D为对角矩阵,其对角线上的元素为d1, d2, … , dn。
非归一化的Laplacian矩阵定义:L = D – W,其具备如下性质:
★ 对于任意向量f ∈ Rn,都有:
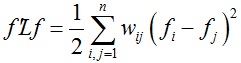
★ 矩阵L为对称半正定矩阵
★ 矩阵L最小的特征值为0,对应的特征向量为1
★ 矩阵L存在n个非负实特征值0 = λ1 ≤ λ2 ≤ … ≤ λn
归一化的Laplacian矩阵有2种形式,具体定义如下:
Lsym = D-1/2LD-1/2 = I – D-1/2WD-1/2
Lrw = D-1L = I – D-1W
归一化的Laplacian矩阵具备如下性质:
★ 对于任意向量f ∈ Rn,都有:
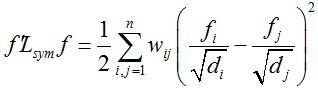
★ 矩阵Lrw存在特征值λ和特征向量u时,矩阵Lsym对应存在特征值λ和特征向量D1/2u
★ 矩阵Lrw特征值λ和特征向量u的求解等价于广义特征值问题Lu = λDu
★ 矩阵Lrw最小的特征值为0,对应的特征向量为1;矩阵Lsym最小的特征值为0,对应的特征向量为D1/21
★ 矩阵Lsym和矩阵Lrw为半正定矩阵,并且存在n个非负实特征值0 = λ1 ≤ λ2 ≤ … ≤ λn
2 谱聚类之图割解释
下面将介绍谱聚类的具体原理,聚类的目标是将数据点分成若干类,使得在同一个类里的数据点之间存在较大的相似性,而在不同类里的数据点之间差异较大。假设给定邻接权重矩阵为W的相似图,构建图分割最简单直接的方法就是转化为最小割问题。对于k个分割区域而言,那么分割区域A1, A2, … , Ak的求解即对应如下最小化问题:

式中Ā代表A的补集,即分割区域A以外的部分。
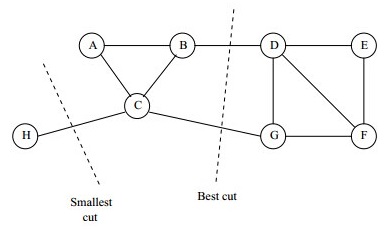
实际上利用上述方法求解得到的结果往往并不理想,例如假设分割区域数目为2时,上述最小割的结果很有可能会出现从图中单独分割一个数据点作为一个区域的情况,如下图所示。一种避免出现该问题的方法是对分割区域A1, A2, … , Ak的大小做限制,如何限定分割区域大小,有两种最常用的方法:Ratio Cut和Normalized Cut。
在Ratio Cut方法里,区域大小由区域中数据点的个数|A|决定,而在Ncut中,区域大小由区域中数据点的权重vol(A)决定,有了区域大小限定之后上述图分割问题可以进一步修改为如下形式:
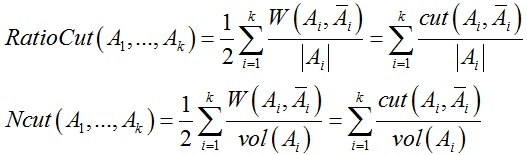
上述目标函数表明分割区域不能太小,但是当加入区域大小限定条件之后,上述问题的求解变成了NP-hard问题,而谱聚类算法利用松弛思想可以近似求解该问题。
2.1 Ratio Cut(k = 2)
对于2个分割区域而言,我们的优化目标如下:
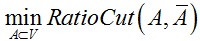
为了求解上述问题,我们首先定义一个指示向量(indicator vector)f = (f1, f2, … , fn)’ ∈ Rn:

我们可以将Ratio Cut的目标函数写成Laplacian矩阵形式:

同时可以得到:
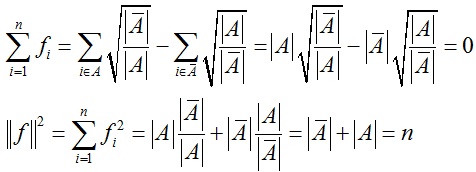
因此优化问题可以等价为:

指示向量f中元素只能取2个特定的离散值,该问题仍然是NP-hard问题。如果将f中的元素取值范围松弛扩大到整个实数域R,那么根据Rayleigh-Ritz定理,该问题的最优解就是矩阵L第二小特征值所对应的特征向量(注意矩阵L最小的特征值为0,对应的特征向量为1),然后我们再将最优解进一步转化为离散特征向量,这一过程通常使用k-means聚类方法将指示向量中的元素聚为2类,使得每一类中的元素对应一个离散值。
2.2 Ratio Cut(任意k)
对于k个分割区域而言,求解过程与上述类似,我们定义k个指示向量hj = (h1,j, h2,j, … , hn,j)’:
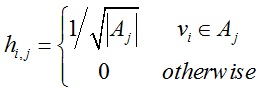 (i = 1, … , n;j = 1, … , k)
(i = 1, … , n;j = 1, … , k)
以这k个指示向量为列可以组成矩阵H∈ Rn×k,其满足H’H = I,并且可以得到:

于是:
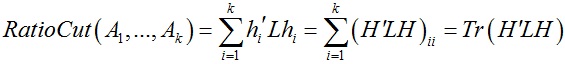
因此优化问题等价为:
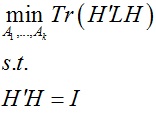
利用松弛思想并根据Rayleigh-Ritz定理,在实数域内,上述问题的最优解H为矩阵L前k个特征向量为列向量所组成的矩阵,然后我们再将实数域解转化为离散域解,同样这一过程以矩阵H的行向量作为数据样本进行k-means聚类。
对于Ratio Cut方法,总结得到如下算法流程:

2.3 Ncut(k = 2)
对于2个分割区域,定义指示向量f:

那么可以得到:
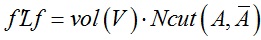
因此优化问题等价为:
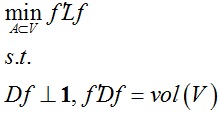
将向量f里的元素松弛到实数域,并用f = D-1/2g替换后可以得到:
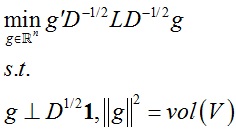
由于D-1/2LD-1/2 = Lsym,D1/21是矩阵Lsym的最小特征向量,vol(V)是一个常量,所以根据Rayleigh-Ritz定理,实数域内最优解g为矩阵Lsym第二小特征值所对应的特征向量,替换后得到最优解f = D-1/2g。而根据归一化Laplacian矩阵的性质,最优解f同样等于矩阵Lrw第二小特征值所对应的特征向量。之后再利用k-means聚类方法将实数域解转化为离散域解。
2.4 Ncut(任意k)
对于k个分割区域,定义k个指示向量hj = (h1,j, h2,j, … , hn,j)’:
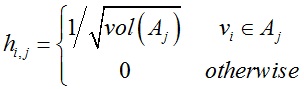 (i = 1, … , n;j = 1, … , k)
(i = 1, … , n;j = 1, … , k)
以这k个指示向量为列组成矩阵H∈ Rn×k,其满足:
H’H = I,hi’Dhi = 1,hi’Lhi = cut(Ai, Āi)/vol(Ai)
因此优化问题等价为:
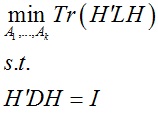
用H = D-1/2T替换并将解空间松弛到实数域,问题转变为:

利用Rayleigh-Ritz定理,实数域内最优解T为矩阵Lsym前k个特征向量为列向量所组成的矩阵,替换后最优解H = D-1/2T。而根据归一化Laplacian矩阵的性质,最优解H同样等于矩阵Lrw前k个特征向量为列向量所组成的矩阵。之后再利用k-means聚类方法将实数域解转化为离散域解。
对于Ncut方法,总结得到如下算法流程:


本文为原创,转载请注明出处:http://www.cnblogs.com/shushen。
参考:
Von Luxburg, Ulrike. "A tutorial on spectral clustering." Statistics and Computing 17.4 (2007): 395-416.
http://blog.pluskid.org/?p=287