最近老板在外面吹牛说我们可以做基于工地的监控,检测工人佩戴安全帽的情况。现在国内做图像识别的公司基本都是顶尖的技术公司了,可以参考的案例并不多,咨询了像海康这样的专门做视频的公司,销售人员说没有产品,可以做项目。那费用至少几十万上百万了。可海康官网明明说有检测安全帽功能的(心里暗骂一句,骗子)。找别人开发的成本太高,没办法只能硬着头皮上了。好在有一个图像处理神器opencv。只不过现在大多数的应用都是围绕在脸部,什么人脸检测啊,人脸识别啊。难得找到一个现成的行人检测分类器,经过测试发现效果还可以接受。附效果图一张。

绿框是检测到的行人。
# -*- coding: utf-8 -*-
# 行人检测
import cv2
from imutils.object_detection import non_max_suppression
from imutils import paths
from imutils.video import FileVideoStream
import numpy as np
import os,imutils
cap = FileVideoStream(r'E: est-3_000130-000849.mp4').start()
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
frame_index = 0
while True:
frame = cap.read()
frame = imutils.resize(frame, width=min(800, frame.shape[1]))
(rects, weights) = hog.detectMultiScale(frame, winStride=(8, 8), padding=(8, 8), scale=1.15)
rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects])
pick = non_max_suppression(rects, probs=None, overlapThresh=0.65)
for (x, y, w, h) in pick:
cv2.rectangle(frame, (x, y), (w, h), (0, 255, 0), 2)
newpath = os.path.join(r'image/capture/' , str(frame_index) + ".jpg");
cv2.imwrite(newpath,frame[y:h,x:w]);
frame_index = frame_index + 1
cv2.imshow("frame",frame)
if cv2.waitKey(1) == 27:
break
python的代码很简单,以上20几行就是检测行人的全部代码了。

经过几番调整参数,检测效果还算理想。这样就可以有做下去的希望了。在网上寻找一番没有找到已经训练好的用于检测安全帽的分类器,无耐只能自己收集素材,进行训练。收集素材真是一项苦差事。好在我有数据源,通过抓取摄像头的视频流,没几天我们就收集了几十万的素材,当然这里面有很多错误数据,需要人工的一一剔除。最终 产生了大量的这样的素材,
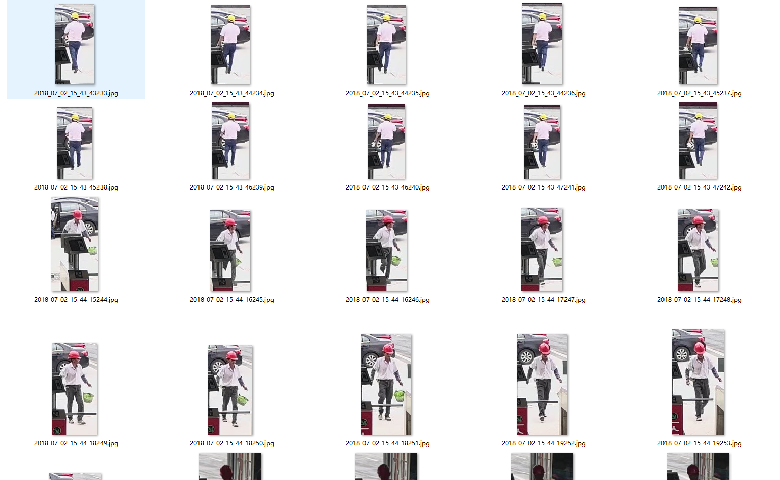
这些图片包含的特征信息过多,还不能用于训练 。经过人工处理以后变成如下格式。
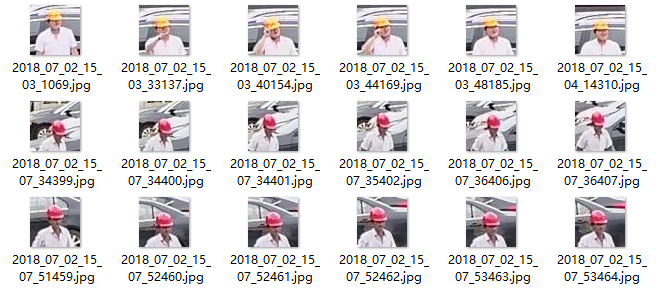
有了正样本,训练还需要反样本。好在之前下载过一套行人检测的样本库,可以利用里面的反样本,拿着处理好的几百张素材,信心满满的去训练了,训练的过程就不详说了,网上有很多教程。我自己写了一个工具,用于产生训练需要的文档信息。训练的过程还算顺利,通过这两百多个手工处理的样本,识别出了大概2000多张对应的数据。错误率在可以接收的范围内。接下来我就掉入了第一个坑,一开始以为随着素材库的变大,识别的内容会越精确 。这样我就拿200 -> 2000 -> 5000 -> 10000 ,训练所花的时间快速增加,一开始花10几20分钟就可以完成,后面逐渐两个小时,半天,一晚上。最后我拿着一万个样本扔到服务器上去训练的时候,记得那天是周五的白天,心想周一肯定可以看结果了吧。结果周一上班发现竟然没有完成。直到周二才完成。整整 花了60多个小时。可是最终识别结果并不理想。无法有效识别戴安全帽和不戴安全帽的人员,识别率过低。
经过思考以后发现可能是样本存在的问题,那么就近一步的缩小样本,只保留安全帽部分。接下来的效果就比较理想了,我用了1000个样本训练的结果,就远超之前10000个样本的识别率了。

虽然识别率还不是很理想,但还有很大的优化空间。至少可以证明这个思路是正确的。
虽然图片可以实现有效的检测,但应用到视频流中由于单祯的处理时间过长,导致视频无法流畅播放。最后经过大量的优化,效果还是比较理想。


链接:https://download.csdn.net/download/shushukui/11617089