一、概念
Reduce Join工作原理
1、Map端的主要工作是:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
2、Reduce端的主要工作是:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组中将那些来源于不同文件的记录(在Map阶段已经打标签)分开,最后进行合并就好了
二、项目介绍
1、待处理文本
order.txt 订单信息表里记录着订单ID,商品ID,订单销量
pd.txt 商品信息表里记录着商品ID,商品名称


1001 01 1 1002 02 2 1003 03 3 1004 01 4 1005 02 5 1006 03 6
01 小米 02 华为 03 格力
2、需求
将商品信息表中数据根据商品pid合并到订单数据表中
3、OrderBean.java
package com.jh.readuceJoin; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class OrderBean implements Writable { private String orderID; //订单ID private String shopID; //商品ID private Integer orderNum; //订单商品数量 private String shopName; //商品名称 private String flag; // 做一个标记,标记数据来自哪个文件或数据库 public OrderBean() { super(); } @Override public String toString() { return orderID + " " + shopName + " " + orderNum; } public String getOrderID() { return orderID; } public void setOrderID(String orderID) { this.orderID = orderID; } public String getShopID() { return shopID; } public void setShopID(String shopID) { this.shopID = shopID; } public Integer getOrderNum() { return orderNum; } public void setOrderNum(Integer orderNum) { this.orderNum = orderNum; } public String getShopName() { return shopName; } public void setShopName(String shopName) { this.shopName = shopName; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } //序列化 @Override public void write(DataOutput out) throws IOException { out.writeUTF(orderID); out.writeUTF(shopID); out.writeInt(orderNum); out.writeUTF(shopName); out.writeUTF(flag); } //反序列化 @Override public void readFields(DataInput in) throws IOException { orderID = in.readUTF(); shopID = in.readUTF(); orderNum = in.readInt(); shopName = in.readUTF(); flag = in.readUTF(); } }
4、OrderMapper.java
package com.jh.readuceJoin; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class OrderMapper extends Mapper<LongWritable,Text,Text,OrderBean> { private OrderBean orderBean = new OrderBean(); // 创建bean对象,赋值,为输出的值 private Text outKey = new Text(); // 赋值商品ID作为输出的键 private String fileName; // 待处理的文件名 @Override protected void setup(Context context) throws IOException, InterruptedException { //获取当前maptask处理的切片数据 FileSplit fileSplit = (FileSplit)context.getInputSplit(); // 获取待处理文件路径 Path path = fileSplit.getPath(); // 获取待处理文件名 fileName = path.getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取每一行 String line = value.toString(); // 将每一行切割 String[] split = line.split(" "); /* 待处理文本有两个,为order.txt和pd.txt order.txt : 1001 01 1 1002 02 2 1003 03 3 1004 01 4 1005 02 5 1006 03 6 pd.txt : 01 小米 02 华为 03 格力 */ if (fileName.contains("order")){ // 数据来自order.txt // 赋值键和值 orderBean.setOrderID(split[0]); orderBean.setShopID(split[1]); orderBean.setOrderNum(Integer.parseInt(split[2])); orderBean.setShopName(""); orderBean.setFlag("order"); outKey.set(split[1]); }else { // 数据来自pd.txt // 赋值键和值 orderBean.setShopID(split[0]); orderBean.setShopName(split[1]); orderBean.setOrderID(""); orderBean.setOrderNum(0); orderBean.setFlag("pd"); outKey.set(split[0]); } context.write(outKey,orderBean); } }
5、OrderReduce.java
package com.jh.readuceJoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
public class OrderReduce extends Reducer<Text,OrderBean,OrderBean,NullWritable> {
private OrderBean shopBean = new OrderBean(); // 存放商品的数据
private ArrayList<OrderBean> orderList = new ArrayList<OrderBean>(); // 存放订单的数据
@Override
protected void reduce(Text key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException {
/*
此时reduce拿到的一组数据中既包括订单数据,也会包括商品数据
需要筛选数据
*/
orderList.clear();
for (OrderBean value : values) {
if (value.getFlag().contains("order")){
// 当前的这组数据是订单数据
OrderBean bean = new OrderBean();
try {
// 工具类:将这组数据复制到bean
BeanUtils.copyProperties(bean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
orderList.add(bean);
}else {
// 当前的这组数据是商品数据
try {
BeanUtils.copyProperties(shopBean,value);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
// 遍历存放订单的数据
for (OrderBean orderBean : orderList) {
// 将对应的商品名称赋值进去
orderBean.setShopName(shopBean.getShopName());
context.write(orderBean,NullWritable.get());
}
}
}
6、OrderDriver1.java
package com.jh.readuceJoin; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class OrderDriver1 { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //1.获取job对象和配置文件对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); //2.添加jar的路径 job.setJarByClass(OrderDriver1.class); //3.设置mapper类和reducer类 job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReduce.class); //4.设置mapper类输出的数据类型Text,OrderBean job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(OrderBean.class); //5.设置reducer类输出的数据类型OrderBean,NullWritable job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); //设置文件的输入出路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); //提交任务 boolean result = job.waitForCompletion(true); //成功返回0,失败返回1 System.exit(result ? 0:1); } }
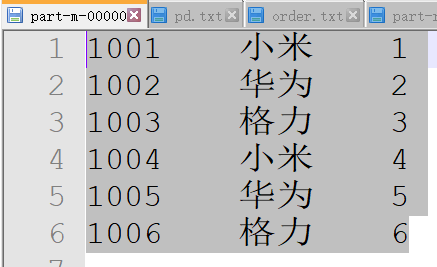
7、输出结果为