需求:
给你一个演员,去爬取豆瓣改演员的信息,并存入数据库。
拿到需求之后想着自己之前也写过几个简单python爬虫脚本,觉得应该没问题。但是却被打脸了。
问题:
我首先是去看了一个php的爬虫框架Spider,框架不错(因为后面没用这个框架就不多说了)爬取页面信息用的是DomCrawler,准备开始动手。打开豆瓣的网页搜索刘德华页面如下:
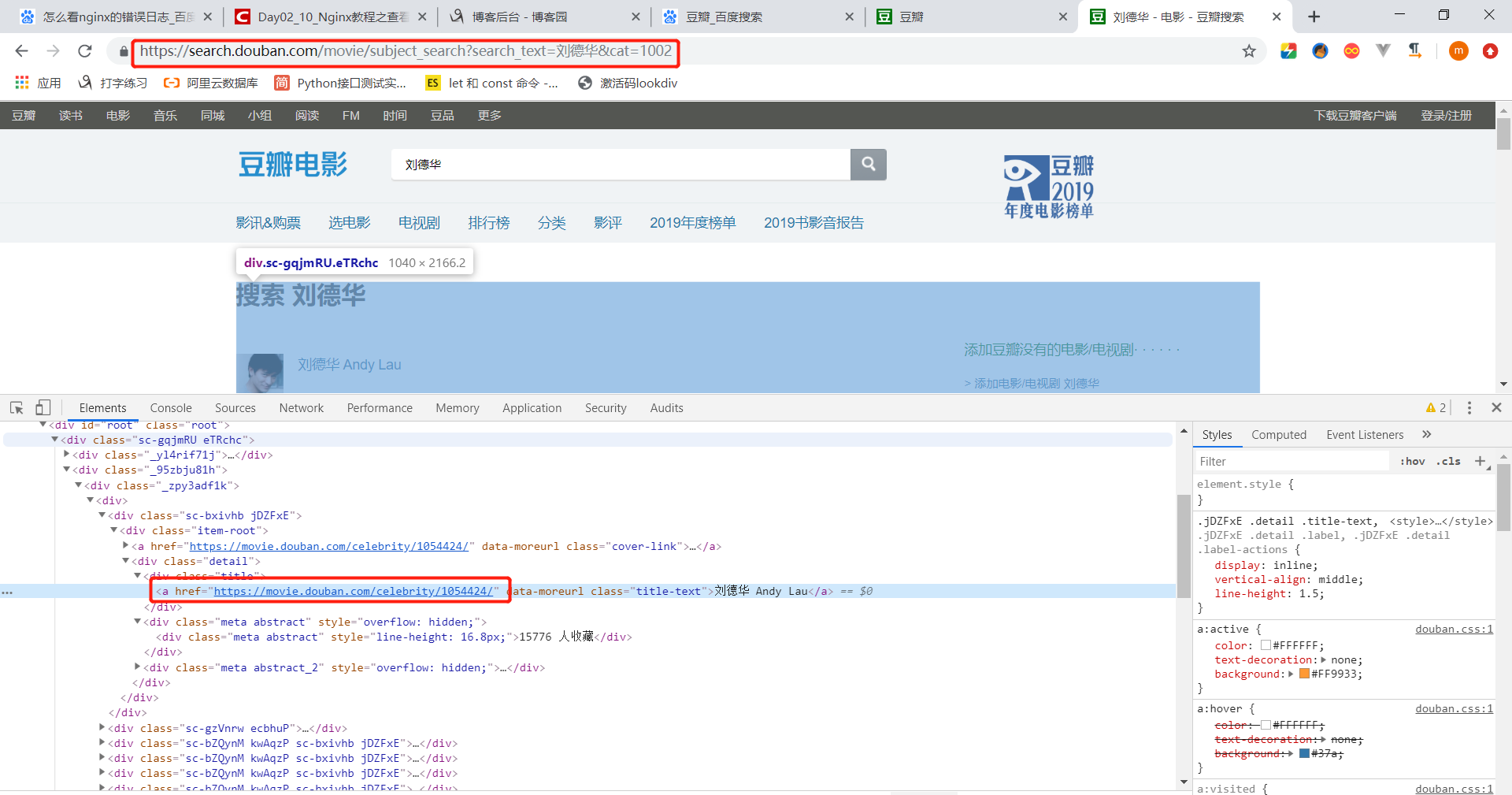
可以看到问题出现了我输入刘德华得到的刘德华的个人信息的地址是没有刘德华这个关键字的,只有刘德华这个演员的豆瓣ID,你可能会说直接获取这个地址再请求一下就行了,是的我也这么想的。但是当你请求这个页面的时候发现,这个页面的内容加密了,这也是我第一次遇到加密的网页。开始一直以为是异步请求结果后面发现不是。然后再网上找到一篇解密的文章发现在自己的能力之外(本人只是个测试,开发的能力还是很有限的)然后就放弃了https://mp.weixin.qq.com/s/2mpu_oY2-M0wcLvf1eU7Sw(这个是解密的文章,感兴趣的可以试一下)。这个问题就困扰了我几天。没办法只能换办法了,然后我发现在百度搜索douban.com:刘德华(豆瓣)的结果看下图

上图a标签里面的链接,虽然是被转码了,点击是可以直接跳转到该演员的详情页面的,而且请求也可以直接请求到演员的豆瓣信息。
接着第二个问题来了,有的演员在豆瓣没有信息他就不会是这个链接,所以这里需要加一个判断,我是在上图中间红色框那里加的判断,如果中间八那个字符串里面包含了"celeb"字符串的话再去请求,不包含的话就不再去请求了。
接下来就到了我们的目标页面了如下:
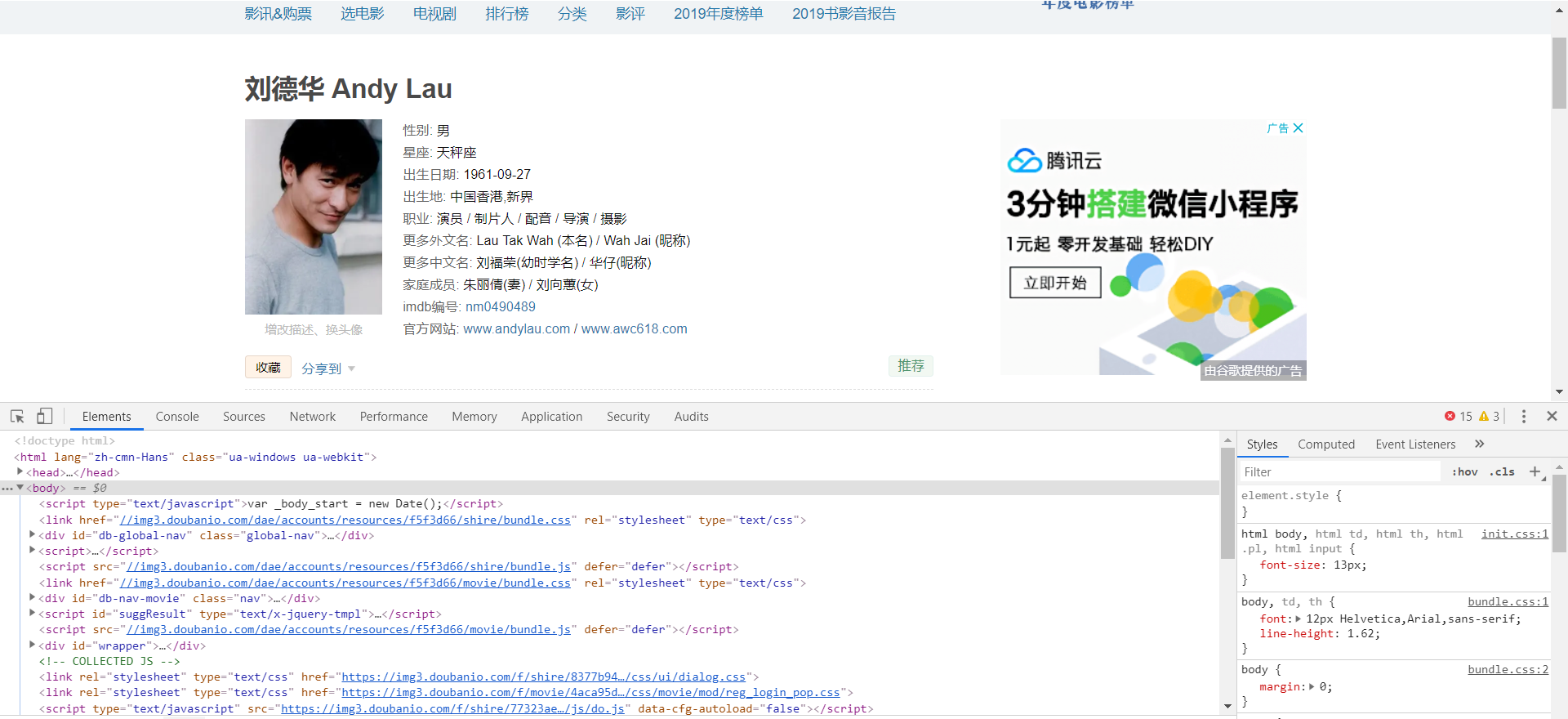
每个演员的信息可能不同,所有很有可能会少一个信息多一个信息,所有这个我每一个信息都做了判断,有再去取,没有就此项信息就为空。代码如下:

最后还有一个坑,在请求的时候上图中的$header变量一定要加上,因为豆瓣做了反扒,如果你不是浏览器访问,会和谐你。加上这句模拟浏览器!!!
最后的工作就是吧拿到的信息处理之后存到数据库了,就和爬虫没有关系了。