Redis事单个线程程序
Nginx也是单线程,但是他们都是服务器高性能的典范
redis为什么这么快?
所有数据都在内存中,所有的运算都是内存级别的运算
Redis既然是单线程,如何能处理那么多的并发客户连接?
多路复用
非阻塞IO
当我们调用套接字(socket网络编程)默认是阻塞的;
阻塞:非要读到数据才返回,非要写完才返回
非阻塞IO:在套接字对象上提供一个选项Non_Blocking,当这个选项打开时,读写方法不会阻塞,而是能读多少度多少,能写多少写多少。
- 能读多少:取决于内核为套接字分配的读缓冲区内部的数据字节数
- 能写多少:取决于内核为套接字分配写缓冲区的空闲空间字节数
- 返回值高数程序实际读写了多少字节
事件轮询(多路复用)
简单的轮询API是select函数,操作系统提供给用户程序的API。来一个处理一个,来了事件就立即返回,死循环。-----不是很懂,大概跟底层相关吧。
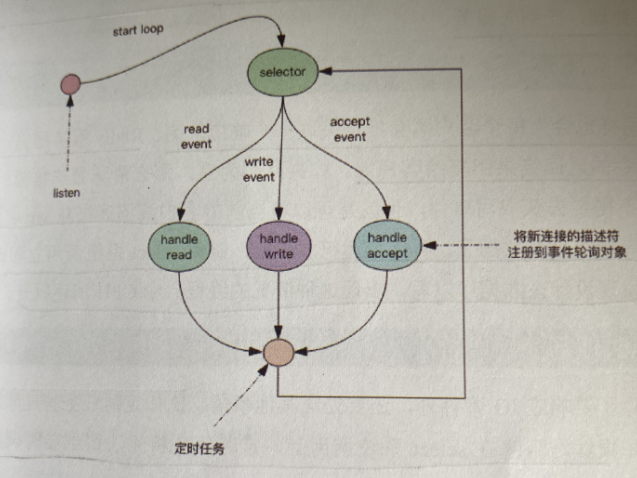
指令队列
Redis会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
相应队列
Redis为每一个客户端套接字关联一个响应队列。rRedis服务器通过响应队列来讲指令的返回结果回复给客户端。
定时任务
假如线程阻塞在select系统调用上,定时任务无法准时调度怎么办
定时任务记录在一个最小堆的数据结构中。快执行的任务放在堆的最上方。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
通信协议
RESP
Redis序列化协议------文本协议
就是将客户端发送给服务器的指令按照一定的规则转换为文档;服务器将返回结果经过编码发送回来。说白了就是序列化协议。
持久化
Redis的数据全部在内存里,突然宕机,数据就会全部丢失,因此需要一种机制来保证Redis的数据不会因为故障而丢失,这个叫作Redis的持久化。
持久化方式:
- 快照
- AOF日志
快照原理
原理:将内存数据的二进制序列化,然后复制一份到文件中
简单的:fork一个子进程,将此时的内存数据复制一份在内存中,然后进行快照。
那么产生的问题就是:在复制完成的过程中,内存发生的数据改变是无法感知的。跟CopyOnWriteList一摸一样
AOF日志
记录指令,恢复Redis时需要进行重放这些指令,很慢。
Redis每次执行指令结束之后,执行完的指令再放入日志存盘。
所以:这个日志会越来越长,而且恢复会很耗时,导致Redis长时间无法对外提供服务,所以需要AOF定期瘦身
------Redis提供了bgrewriteaof指令用来给AOF文件日志瘦身
fsync
保证机器宕机的时候,也保证指令的不丢失
运维
通常Redis的主节点不会进行持久化操作,持久化操作主要在从节点进行,从节点是备份节点,没有来自客户端请求的压力,它的操作系统资源往往比较充沛。
混合持久化
前半段用快照,后半段用最新的AOF文件
管道
就是将连续的几个任务请求一起发送过去,然后结果一起发送过来。是客户端提供的功能,其实没东西的
事务
Redis对应的事务指令为:multi、exec、discard。
multi
incr books
incr books
exec
所有指令在exec之前不执行,而是缓存在服务器的一个事务队列中,服务器一旦收到exec指令,才开始执行整个事务队列,执行完毕后一次性返回所有指令的运行结果。
注意:假如事务的中间有一条指令出错,那么后续的还是能执行的。所以说redis并不能保证原子性。
discard 丢弃
跟exec是对立的
优化
Redis事务在发送每个指令到事务缓存队列时都要经历一次网络读写,当一个事务内部的指令较多时,需要的网络IO就会变长,所以通常Redis的客户端在执行事务时都会结合管道一起使用。
watch
乐观锁
watch books
incr books
multi
incr books
incr books
exec
上述代码执行失败,因为books在事务之前改变了。
PubSub消息队列
上一篇讲了Redis消息队列的使用方法,但是没有提到Redis消息队列的不足,不保证准确性和多播机制
消息多播允许生产者只生产一次信息,由中间件负责将信息复制到多个消息队列,每个消息队列由相应的消费组进行消费。
为了解决多播问题:Redis提供了PubSub(PublisherSubscriber)发布者/订阅者模式。

消费者
订阅了name这个主题
import redis import time client = redis.StrictRedis() p = client.pubsub() p.subscribe("name") while true: msg = p.get_message() if not msg: time.sleep(1) continue; print msg
生产者
import redis client = redis.StrictRedis() client.publish("name", "java") client.publish("name", "python") client.publish("name", "go")
所有的消费者都会收到相同的信息
但是休眠也不是个事,用监听来代替休眠
import redis import time client = redis.StrictRedis() p = client.pubsub() p.subscribe("name") for msg in p.listen(): print msg
当信息来了,就知道了
模式订阅
一次订阅多个主题
缺点
无法确认消费者是否收到
并且不会持久化
小对象的压缩
Redis是一个非常耗费内存的数据库,它的所有数据都放在内存里
zipList
内部管理的集合数据结构很小,他会使用紧凑存储形式压缩存储
本来时Hashmap存储的,改用一维数组存储下。
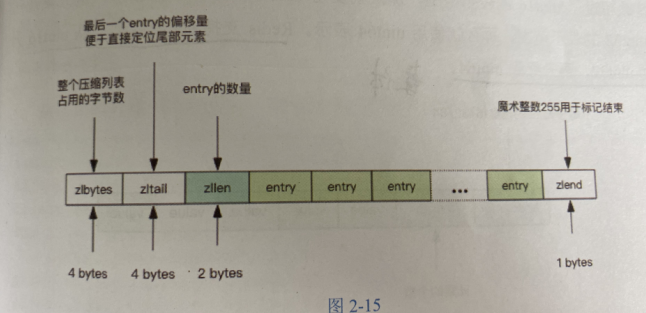
如果hash结构,那么key和value会作为两个entry被相邻存储
object encoding key:查看是用什么格式存储的
intset
当set元素少的时候且都是整数的时候,紧凑的整数数组存储

总结:小对象超过一定的数量之后就必须使用标准的存储结构
内存回收机制
页回收,只要页上还有一个key,就不会回收,但是会重新使用那些尚未回收的空闲内存
内存分配算法
内存分配是一个非常复杂的课题,需要适当的算法划分内存页,需要考虑内存碎片,需要平衡性能和效率。
redis不管内存的,但是有第三方库管理:
- jemalloc(facebook)
- tcmalloc(google)
jemalloc的性能好一些,所以redis默认使用了jemalloc