!/usr/bin/env python
# -*- coding:utf-8 -*-
# __author__:anxu.qi
# Date:2018/11/29
列表list 有序的,可变的
:一个队列,一个排列整齐的队伍
:列表内的个体称作元素,由若干元素组成列表
:元素可以是任意对象(数字、字符串、对象、列表等)
:列表内元素有顺序,可以使用索引
:线性的数据结构
:使用[]表示
:支持in操作 ,以逗号进行分隔
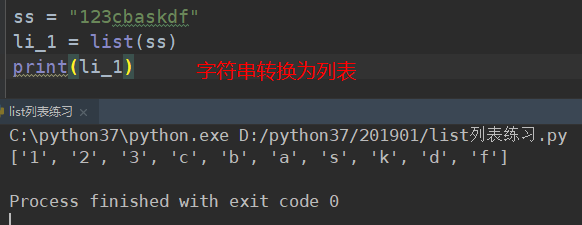
字符串转为列表,内部使用for循环进行迭代。

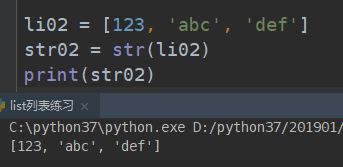
# 列表转换为字符串的时候:
# 列表中有数字和字符串:需要自己写for循环一个一个进行处理
将整个列表作为一个整体,当做一个字符串了,就是在列表外加了一个“”双引号。
正确做法:
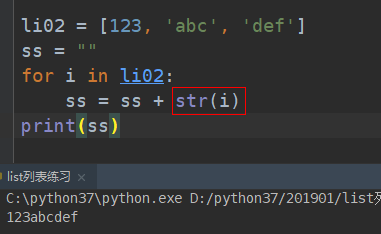
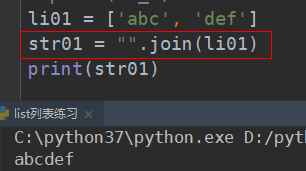
# 列表中只有字符串:直接使用字符串join方法,转为字符串
# 字符串操作
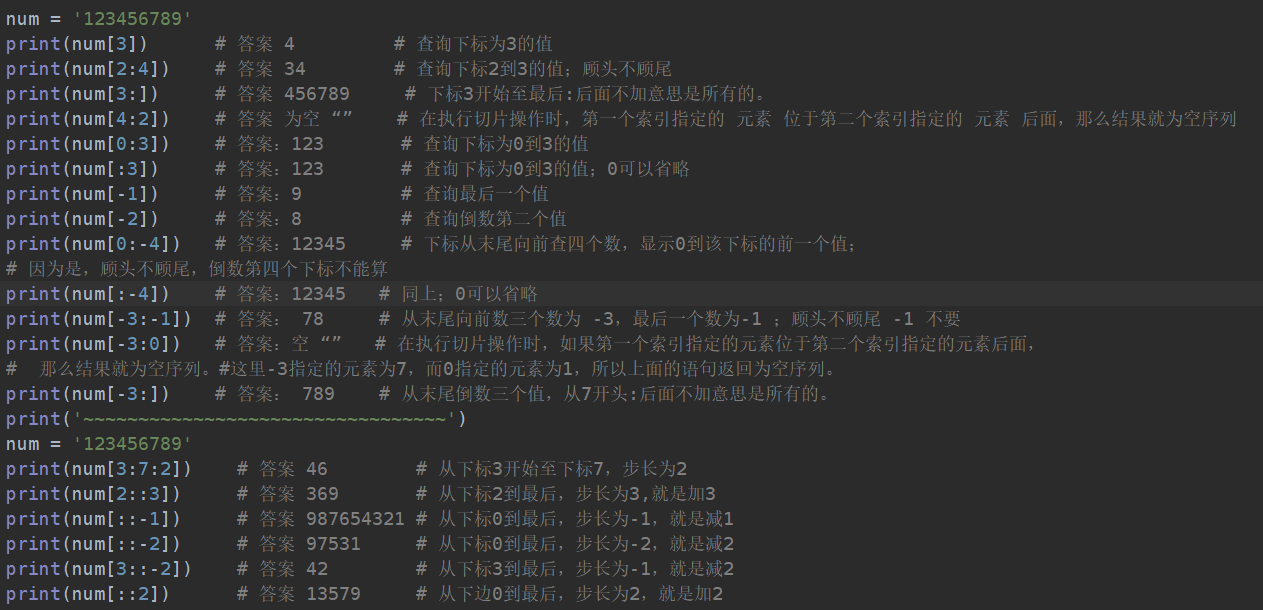
# names = ["NingTao", "RenBaiqing", "GuoYue", "RenBaiqing"]
# ################### 列表的查 ###############################
# # 索引
# print(names[3]) # 查询出下标为3的值
# # RenBaiqing
# print(names[0], names[2]) # 查询出下标为0,2的值
# # NingTao GuoYue
#
# # 切片 顾头不顾尾
# print(names[1:3]) # 查询下标为1到3的值,但不包括3的值
# # ['RenBaiqing', 'GuoYue']
# print(names[-1]) # 查询最后一个值
# # RenBaiqing
# print(names[-3:-1]) # 查询数两个值
# # ['RenBaiqing', 'GuoYue']
# print(names[-3:]) # 查询倒数3个值
# # ['RenBaiqing', 'GuoYue', 'RenBaiqing']
# print(names[0:3]) # 查询下标为0-3的值,不包括下标3的值
# # ['NingTao', 'RenBaiqing', 'GuoYue']
# print(names[:3]) # 注:如果前面的是0的话可以省略掉
# # ['NingTao', 'RenBaiqing', 'GuoYue']
# print(names.index("RenBaiqing")) # 查询 RenBaiqing的下标值
# # 1
# print(names[names.index("RenBaiqing")])
# # RenBaiqing
# ################### 列表的增 ###############################
# names = ["NingTao", "RenBaiqing", "GuoYue", "RenBaiqing"]
# names.append("FuZhiqiang") # 追加到列表最后
# # ['NingTao', 'RenBaiqing', 'GuoYue', 'RenBaiqing', 'FuZhiqiang']
# print(names)
# # ['NingTao', 'RenBaiqing', 'GuoYue', 'RenBaiqing']
# 注 新增的话只能一次增加一个
# names.insert(1, "FuZhiqiang") # 插入到下标为1的位置,原来的将被往后推。
# print(names)
# # ['NingTao', 'FuZhiqiang', 'RenBaiqing', 'GuoYue', 'RenBaiqing']
# ################### 列表的删除 ###############################
# 第一种:names.remove("RenBaiqing") # 直接填写值
从左至右查找第一个匹配value的值,移除
# names.remove("RenBaiqing") # 删除列表中的 RenBaiqing
# 第二种 del names[4] # 填写的是下标
# del names[4] # 填写的是值的下标 # 删除下标为4的值
del names[2:4] # 切片方式删除,删除多个
# 第三种 name.pop
# names.pop() # 默认不填写下标是删除最后一个
# names.pop(2) # 指定下标后,删除下标的位置
# 第四中 del names
# 删除列表变量名,直接删除整个变量
# ################### 列表的改 ###############################
# print(names)
# # ['NingTao', 'FuZhiqiang', 'RenBaiqing', 'GuoYue', 'RenBaiqing']
# names[1] = "YanWen" # 将 FuZhiqing 替换为 YangWen
# # ['NingTao', 'YanWen', 'RenBaiqing', 'GuoYue', 'RenBaiqing']
# names2 = ["NingTao", "RenBaiqing", "GuoYue", "RenBaiqing"]
# print(names2.index("RenBaiqing"))
# ################### 列表统计(count) ###############################
# 计算元素出现的次数
# print(names.count("NingTao"))
# # 2
# ################### 列表清空(clear) ###############################
# names.clear() # 清空整个列表的所有元素,只剩下一个空列表
# print(names)
# # []
# ################### 列表反转(reverse)(就地修改) ###############################
# names = ["NingTao", "RenBaiqing", "GuoYue", "RenBaiqing"]
# names.reverse()
# print(names)
# # ['RenBaiqing', 'GuoYue', 'RenBaiqing', 'NingTao']
# ################### 列表排序(sort)(就地修改) ###############################
# 排序规则: 特殊符号 --》 数字 --》 大写 --》 小写
# 是按照ASCII码中的排序来的
1.对列表元素进行排序,就地修改,默认升序。reverse默认为False
2.reverse 为True ,反转,降序
3.key一个函数,指定key如何排序
lst.sort(key=str)
# names = ["3NingTao", "rRenBaiqing", "#GuoYue", "RenBaiqing"]
# names.sort()
# print(names)
# # ['#GuoYue', '3NingTao', 'RenBaiqing', 'rRenBaiqing']
# ################### 列表扩展 (extend)###############################
# 参数必须是可迭代对象
# 把每个元素 循环迭代加入到原来的列表中
# 就地修改的
# names = ["3NingTao", "rRenBaiqing", "#GuoYue", "RenBaiqing"]
# names2 = [1,2,3,4,5,6]
# names.extend(names2)
# del names2
# # print(names,names2)
# print(names)
# # ['3NingTao', 'rRenBaiqing', '#GuoYue', 'RenBaiqing', 1, 2, 3, 4, 5, 6] [1, 2, 3, 4, 5, 6]
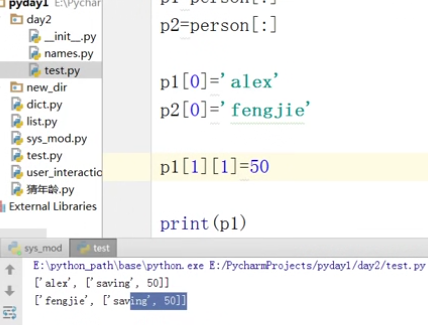
# ################### 列表复制 (浅 copy) ###############################
# 浅copy,只copy一次,是因为第一次的内存地址是又克隆的一份,而其他的地址没有复制,还是用的原来的内存地址,所以会变
# names = ["3NingTao", "rRenBaiqing",["aliyun","jack"], "#GuoYue", "RenBaiqing","XiaoMing"]
# names2 = names.copy()
# print(names)
# # ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
# print(names2)
# # ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
# names[4] = "小明"
# names2[2][0] = "ALIYUN"
# print(names)
# # ['3NingTao', 'rRenBaiqing', ['ALIYUN', 'jack'], '#GuoYue', '小明', 'XiaoMing']
# print(names2)
# # ['3NingTao', 'rRenBaiqing', ['ALIYUN', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
举例:银行同一账号,多个存款人
################### 列表复制 (深 copy.deecopy) ###############################
import copy
# 深copy 是完全独立的复制列表 ,如果是数据量特别大的情况下,这样做是不合适的,因为将又开辟一份内存空间。
names = ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
names2 = copy.deepcopy(names)
print(names)
# ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
print(names2)
# ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
names[2][0] = "ALIYUN"
print(names)
# ['3NingTao', 'rRenBaiqing', ['ALIYUN', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
print(names2)
# ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing']
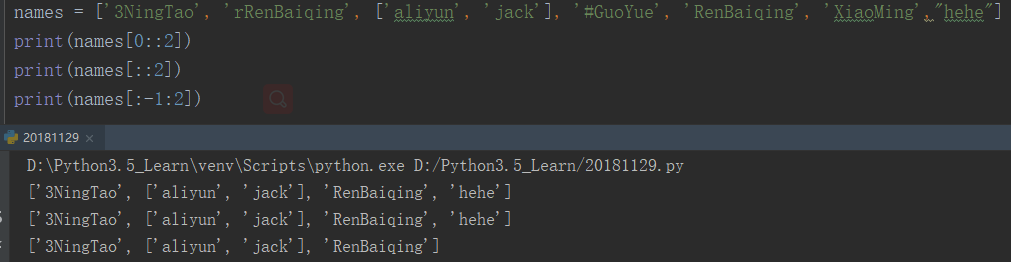
names = ['3NingTao', 'rRenBaiqing', ['aliyun', 'jack'], '#GuoYue', 'RenBaiqing', 'XiaoMing',"hehe"]
print(names[0::2])
print(names[::2])
print(names[:-1:2])
################### 列表 ###############################
# #!/usr/bin/env python
# # -*- coding:utf-8 -*-
# # __author__:anxu.qi
# # Date:2018/11/19
# ######################### 列表 #################################
aa_list = ["tami","beijing","fengshan","fengtai","apache","nginx"]
# print(aa_list)
## 索引
print(aa_list[0])
# tami
## 切片
print(aa_list[0:2])
# ['tami', 'beijing']
## len
print(aa_list[2:len(aa_list)])
# ['fengshan', 'fengtai', 'apache', 'nginx']
################# for ################
# aa_list = ["tami","beijing","fengshan","fengtai","apache","nginx"]
## 循环
for i in aa_list:
print(i)
"""
tami
beijing
fengshan
fengtai
apache
nginx
# """
############################# 列表内布提供的功能 ###############################
################################ append 追加 ##################################
# def append(self, p_object):
# 追加功能,在列表的最后添加
name_list = ["apache","nginx","tomcat","redis"]
name_list.append("mysql")
print(name_list)
# ['apache', 'nginx', 'tomcat', 'redis', 'mysql']
################################ count 统计次数 ##################################
# def count(self, value):
# 统计元素出现的次数
name_list = ["apache","nginx","tomcat","redis","tomcat","tomcat"]
print(name_list.count("tomcat"))
# 3
时间复杂度:考量算法的重要指标
index和count方法都是O(n) O(1) O(n2)
随着列表数据规模的增大,而效率下降
如何返回列表元素的个数?如何遍历?如何设计高效?
################################# extend 扩展 ##################################
# def extend(self, iterable):
# 扩展列表 iterable (可迭代的) # 相当于批量添加
name_list = ["apache","nginx","tomcat","redis"]
num_list = [11,22,33,44]
name_list.extend(num_list)
print(name_list)
# ['apache', 'nginx', 'tomcat', 'redis', 11, 22, 33, 44]
可以使用加号将两个列表相加,并重新付给一个新的变量,原来的列表都不会改变。

* :
重复操作,将本列表元素重负n次,返回新的列表
cc = name_list * 5
print(cc)
################################# index 获取索引 ##################################
# def index(self, value, start=None, stop=None):
# 获取某个元素的索引,默认不加是从左往右找,找到第一个即返回。
name_list = ["apache","nginx","tomcat","redis","hehe","nginx","redis","nginx"]
print(name_list.index("redis",4,7)) # 从下边1开始,到下标6结束,不包括下标6
# 6
################################ insert 插入 ##################################
# def insert(self, index, p_object):
# 表示在指定索引的位置插入数据
name_list = ["apache","nginx","tomcat","redis"]
name_list.insert(1,"mysql") # 先输入下标值,然后输入你要插入值。
print(name_list)
# ['apache', 'mysql', 'nginx', 'tomcat', 'redis']
insert 轻易不要用。如果是在最前或者是中间进行插入的话,要一移动其后面的所有值。效率很低。
name_list = ["apache", "nginx", "tomcat", "redis"]
name_list.insert(100, '777') # 如果超过索引,就在最尾部添加
name_list.insert(-100, '777') # 如果是负索引超过了,就在开头添加
################################ pop 末尾移除(就地修改) ##################################
# def pop(self, index=None):
# 没有指定索引,默认是移除最后一个,并可以获取删除的值
name_list = ["apache","nginx","tomcat","redis"]
v = name_list.pop()
print(v)
# redis
# 在原来列表中移除到最后一个元素,并赋值给aa
name_list = ["apache","nginx","tomcat","redis"]
aa = name_list.pop(2) # 根据下标值(索引值进行移除)
print(aa)
# tomcat
print(name_list)
# ['apache', 'nginx', 'redis']
# 可以使用下标值
name_list = ["apache","nginx","tomcat","redis"]
print(name_list.pop(2),11111111111) # pop中可以跟下标,移除的就是下标的值。
# tomcat 11111111111
################################ remove 移除 ##################################
# def remove(self, value):
# 移除某个元素 默认只移除第一个从左边匹配到的元素。
name_list = ["apache","nginx","tomcat","redis","apache","tomcat","apache"]
name2 = name_list.remove("apache") # 默认移除从左边移除的第一个apache
print(name_list)
# [ nginx', 'tomcat', 'redis', 'apache', 'tomcat', 'apache']
################################ reverse 反转 ##################################
# def reverse(self):
# 将当前列表进行反转,也就是前后顺序倒过来
name_list = ["apache","nginx","tomcat","redis"]
print(name_list.reverse())
print(name_list)
# ['redis', 'tomcat', 'nginx', 'apache']
################################ sort 排序 ##################################
# def sort(self, cmp=None, key=None, reverse=False):
reverse=Ture 为从大到小
reverse=False 为从小到大
# 将所有列表中的元素进行排序
name_list = ["apache","nginx","tomcat","redis","mysql"]
# cmp,key 参数先不进行讲解,后期再调整更新
################################ del 删除指定位置的元素 ##################################
name_list = ["apache","nginx","tomcat","redis","mysql"]
del name_list[1] # 删除列表中下标为1的元素
print(name_list)
# ['apache', 'tomcat', 'redis', 'mysql']
name_list = ["apache","nginx","tomcat","redis","mysql"]
del name_list[1:3] #删除列表中下标1到3的元素
print(name_list)
# ['apache', 'redis', 'mysql']
#################################################################################