深度学习神经网络训练过程主要涉及到两个过程,一个是数据前向传播(data forward-propagation),输入数据经过网络正向计算,输出最终结果;另一个是误差反向传播(error backward-propagation),网络输出结果的误差和梯度反向传播,并更新权重。反向传播过程又可以细分为两部分:1)求梯度;2)梯度下降法更新权重。现在大家所说的backward-propagation,一般只是指第一步:求梯度,采用的策略就是链式法则。
最早在1974年,有个Harvard博士生Paul Werbos首次提出了backprop,不过没人理他,到了1986年,Rumelhart和Hinton一起重新发现了backprop,并且有效训练了一些浅层网络,一下子开始有了名气。
1. backward-propagation的重要性
前面已经说了,BP(Backward Propagation)的作用主要是将网络输出结果的误差和梯度反向传递,从而采用梯度下降法进行权重更新。所以其实我们需要的只是每个权重的梯度,完全可以不采用BP,直接对每个权重计算下梯度就可以了,但是这样会有很多冗余的计算过程,而采用BP,一层一层的反向传播梯度,就能避免这些冗余的计算,加速网络训练,这应该就是BP最重要的地方了。
如下面的计算图,若要分别计算a,b的梯度。
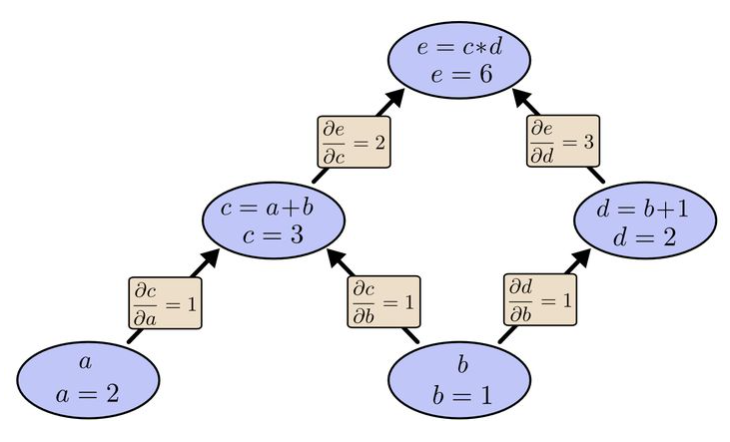
直接计算梯度
先计算a的梯度, 根据链式法则:
再计算b的梯度,根据链式法则:
很明显,(frac{partial e}{partial c})计算了两遍,是一个冗余的计算过程。
采用BP逐层计算梯度
BP是一层一层的反向计算,先计算e对c,d的梯度(frac{partial e}{partial c},frac{partial e}{partial d}),并将梯度信息(frac{partial e}{partial c},frac{partial e}{partial d})存储在c,d两个节点, 即:
再计算c,d对a,b的梯度,同时将梯度存储在a,b节点,即:
对比上述两个过程,很明显BP能节省计算量。经常刷算法题的同学,应该能感受到BP就是一个动态规划的过程,中间存储梯度就类似于dp数组值。
2.pytorch中反向传播
pytorch中的autograd模块实现了自动的反向传播,示例代码如下:
import torch
from torch import nn
def show_param(net):
# print(list(net.parameters()))
for index, param in enumerate(net.parameters()):
print("第{}层结点权重参数".format(index+1), param.data) # 打印权重参数
print("第{}层结点梯度".format(index+1), param.grad) # 打印梯度值
# 搭建网络
net = nn.Sequential(
nn.Linear(4, 3, bias=False), # 不采用bias
nn.ReLU(),
nn.Linear(3, 3, bias=False),
nn.ReLU(),
nn.Linear(3, 2, bias=False),
)
# 初始化网络
for m in net.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=1e-3)
# nn.init.constant_(m.bias, 0)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
lr = 0.01 # 学习速率
input = torch.randn((2, 4), requires_grad=True) # 输入数据, shape为(2, 4)
label = torch.empty(2, dtype=torch.long).random_(2) # 输入数据标签(随机赋值为0, 1, 必须是torch.long类型)
# print(net[0](input))
# 训练过程
for i in range(1):
output = net(input)
loss = criterion(output, label)
print("********反向传播前参数*********")
show_param(net)
loss.backward() # 反向传播,计算梯度值
print("********反向传播后参数*********")
show_param(net)
for param in net.parameters(): # 更新参数
param.data.sub_(param.grad.data*lr) # w = w-grad*lr
print("********梯度下降后参数*********")
show_param(net)
上面代码中搭建了一个三层的网络,其结构画出来如下:

在上图中,可以自己手动计算下权重参数的梯度,如w7,w4的梯度如下:
那么可以将下图中圈出来的部分存储在节点处,方便bp传递过程中使用:

参考: https://www.zhihu.com/question/27239198?rf=24827633
https://zhuanlan.zhihu.com/p/25081671
https://zhuanlan.zhihu.com/p/25416673
3. 采用Numpy实现backward
在看完pytorch中的backward的步骤后,应该能明白backward的作用了,但还是想看下backward过程中的细节问题,可以尝试自己用numpy实现下简单的神经网络和backward。
下面代码中采用numpy实现了一个简单的神经网络训练和推理过程,可以看到在Network类中我们维持了三个字典, 如下:
self.params = {}: 储存网络中的权重参数self.grads = {}: 储存网络中权重参数的梯度值self.cache = {}:缓存中间数据值,方便backward中使用
上面的self.cache = {},就是我们一直在强调的,在bp过程中储存的数据,方便bp过程中使用
# coding:utf-8
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_backward(dz, x):
z = sigmoid(x)
return dz * z * (1 - z)
def relu(x):
x = np.copy(x)
x[x <= 0] = 0 # relu: max(0, x)
return x
def relu_backward(dz, x):
dx = np.copy(dz)
dx[x <= 0] = 0
return dx
def cross_entropy_loss(pred, target):
# target: (batch_size,), pred: (batch_size, nClass)
label = np.zeros((target.shape[0], pred.shape[1])) # one-hot encoding,编码
for i in range(target.shape[0]):
label[i, target[i]] = 1
pred_sft = np.exp(pred)/(np.sum(np.exp(pred), axis=1)[:, None]) # softmax求概率
loss = -np.sum(np.log(pred_sft)*label) # crossEntropy 求交叉熵损失
grad = cross_entropy_loss_backward(pred_sft, label) # 求交叉熵梯度,反向传播使用
return loss/pred.shape[0], grad #loss/pred.shape[0]:是为了将整个batch的loss平均后返回,方便外层调用使用,
# 注意:求导只是求-np.sum(np.log(pred_sft)*label)这一项的梯度, 这里不需要考虑batch_zie,后面backward过程中考虑了
def cross_entropy_loss_backward(pred_softmax, one_hot_label):
return pred_softmax - one_hot_label
# 详细推导过程:https://zhuanlan.zhihu.com/p/131647655
class Network(object):
def __init__(self, net_architecture, learning_rate):
assert len(net_architecture) > 0 and isinstance(net_architecture[0], dict),
print("wrong format of net_architecture:{}".format(net_architecture))
self.params = {} # 权值参数
self.grads = {} # 梯度
self.cache = {} # 缓存,方便backward propagation
self.net_arch = net_architecture
self.lr = learning_rate
for idx, layer in enumerate(net_architecture):
self.params["w{}".format(idx + 1)] = np.random.normal(0, pow(layer["output_dim"], -0.5),
(
layer["output_dim"], layer["input_dim"])) # 初始化weight
self.params["b{}".format(idx + 1)] = np.random.randn(layer["output_dim"], 1) * 0.1 # 初始化bias
def train(self, data, target, batch_size, loss_func="cross_entropy_loss"):
epoch_loss = 0
for j in range(0, data.shape[0], batch_size):
batch_data = data[j:j + batch_size]
batch_target = target[j:j + batch_size]
pred = self.forward(batch_data) # pred: shape(batch_size, nClass)
if loss_func == "cross_entropy_loss":
loss, loss_grad = cross_entropy_loss(pred, batch_target) # loss为一个batch的平均loss
self.backward(loss_grad)
else:
raise Exception("Unimplemented loss func")
self.update()
epoch_loss += loss
return epoch_loss*batch_size/data.shape[0] # 一个epoch的平均loss
def query(self, data):
pred = self.forward(data)
return np.argmax(pred, axis=1) # shape(batch_size, )
def forward_once(self, input_prev, w_cur, b_cur, activation="relu"):
output_cur = np.dot(w_cur, input_prev) + b_cur
if activation == "relu":
activation_func = relu
elif activation == "sigmoid":
activation_func = sigmoid
else:
raise Exception("Unimplemented activation func")
return activation_func(output_cur), output_cur
def forward(self, x):
input = x.T # x shape : from (batch_size, input_dim) to (input_dim, batch_size)
for idx, layer in enumerate(self.net_arch):
w = self.params["w{}".format(idx+1)]
b = self.params["b{}".format(idx+1)]
output, output_cur = self.forward_once(input, w, b, activation=layer["activation_func"])
self.cache["input{}".format(idx+1)] = input
self.cache["output{}".format(idx+1)] = output_cur # 储存wx+b,未经过激活函数的值
input = output
return output.T # output shape : from (output_dim, batch_size) to (batch_size, output_dim)
def backward_once(self, dx, w_cur, b_cur, input_cur, output_cur, activation="relu"):
n = input_cur.shape[1] # batch_size
if activation == "relu":
activation_backward = relu_backward
elif activation == "sigmoid":
activation_backward = sigmoid_backward
else:
raise Exception("Unimplemented activation func")
activation_grad = activation_backward(dx, output_cur)
bp_grad = np.dot(w_cur.T, activation_grad)
# 注意!!!: weight_grad: shape(5 10), 和w_cur的shape相同,但这个梯度是4组数据(batch_size=4)的梯度之和,除4表示求整个batch的平均梯度
weight_grad = np.dot(activation_grad, input_cur.T)/n
# 注意!!!: b_cur:shape(5, 1); activation_grad:shape(5, 4); 这里的4表示batch_size, 求和除4,相当于求整个batch的平均梯度
bias_grad = np.sum(activation_grad, axis=1, keepdims=True)/n
return bp_grad, weight_grad, bias_grad
def backward(self, dy):
bp_grad_input = dy.T # dy shape: from (batch_size, output_dim) to (output_dim, batch_size)
for idx, layer in reversed(list(enumerate(self.net_arch))):
w = self.params["w{}".format(idx + 1)]
b = self.params["b{}".format(idx + 1)]
input = self.cache["input{}".format(idx+1)]
output = self.cache["output{}".format(idx+1)]
bp_grad_output, weight_grad, bias_grad = self.backward_once(bp_grad_input, w, b, input, output, activation=layer["activation_func"])
self.grads["weight_grad{}".format(idx + 1)] = weight_grad
self.grads["bias_grad{}".format(idx + 1)] = bias_grad
bp_grad_input = bp_grad_output
def update(self): # 梯度下降,更新权重参数
for idx, layer in enumerate(self.net_arch):
self.params["w{}".format(idx + 1)] -= self.lr*self.grads["weight_grad{}".format(idx + 1)]
self.params["b{}".format(idx + 1)] -= self.lr*self.grads["bias_grad{}".format(idx + 1)]
if __name__ == "__main__":
net_architecture = [
{"input_dim": 10, "output_dim": 20, "activation_func": "relu"},
{"input_dim": 20, "output_dim": 10, "activation_func": "relu"},
{"input_dim": 10, "output_dim": 5, "activation_func": "sigmoid"},
]
learning_rate = 0.01
net = Network(net_architecture, learning_rate)
# 随机训练数据
train_data = np.random.randn(100, 10)
train_target = np.random.randint(0, 5, 100)
# 模拟训练train()
epoch = 1000
batch_size = 4
loss_list = []
for i in range(epoch):
epoch_loss = net.train(train_data, train_target, batch_size, loss_func="cross_entropy_loss")
loss_list.append(epoch_loss)
print("[Epoch {}/{}] training loss: {:.4f}".format(i+1, epoch, epoch_loss))
# 采用随机测试数据,模拟evaluate
test_data = np.random.randn(100, 10)
test_target = np.random.randint(0, 5, 100)
test_pred = net.query(test_data)
print(test_target, test_pred)
precision = np.sum(test_pred == test_target)/test_target.shape[0]
print("Test precision: {:.4f}%".format(precision*100))
参考:https://zhuanlan.zhihu.com/p/47051157