一、集合接口
设计意义:数据类型的一种(源于数据结构),一般语言所必须具备的;
1.集合的接口与实现分离(与普通的数据结构类似),也就是每一个实现的集合都有一个相应的接口,示例如下:
/*接口例子*/ interface Queue<E> { void add(E element); E remove(); int size(); } /*对应实现的例子*/ class CirularArrayQueue<E> implements Queue<E> { CircularrArrayQueue(int capacity){......}; public void add(E element){......}; public E remove(){......}; ...... }
接口与实现分离目的:使用多态减少代码的修改量(“增加内聚,降低耦合”思想);示例如下:
/*结合中使用接口的意义*/ Queue<Customer> expressLane = new CirularArrayQueue<>(100); expressLane.add(new Customer("Harry")); /*多态随时替换子类*/ Queue<Customer> expressLane = new LinkedListQueue<>(); expressLane.add(new Customer("Harry"));
2.java类库的集合接口和迭代器接口
迭代器:用于访问对应集合的每个元素的一个工具;
迭代器有自己的接口,使用其中的方法可以有效遍历元素,且有一种简写方法:如下:
1 /*迭代器接口中的方法*/ 2 public interface Iterator<E> 3 { 4 E next(); //通过反复使用next可以访问集合中的每个元素 5 boolean hasNext(); 6 void remove(); 7 } 8 9 /*经典迭代器遍历元素方法*/ 10 Collection<String> c = ...; 11 Iterator<String> iter = c.itertor(); 12 while(iter.hasNext()){ 13 String element = iter.next(); 14 ... 15 } 16 17 /*Iterator简写的for each方法*/ 18 for(String elements : c){ 19 /*做一些对每个元素的处理*/ 20 }
关于for each使用的解释:for each可以在任何实现了Iterable接口的对象中使用,而Iterable接口中调用了泛型的Iterator方法,而所有集合类的基础接口Collection则扩展了Iterable接口,所以标准类库中的任何接口都可以使用“for each”循环;
需要注意一点:集合分为了有序集合和无序集合,所以遍历的时候,有序集合会根据相应顺序遍历,而无序集合则是随机的;但是都可以遍历到所有的元素;
关于迭代器的细节:游标是如何移动,如何取值,待研究;
iterator元素的方法:删除:示例:删除的remove方法与next的关联性非常大,想要remove前必须使用next定位到下一个元素;
/*删除数组集合中的第一个元素的方法*/ Iterator<String> it = c.iterator(); it.next(); it.remove();
注意:Collection接口(集合类的基础接口)中有许多的泛型方法,这些方法都比较实用,但是如果以后需要使用,就必须要把这些方法全部实现一遍,比较繁琐;解决办法就是用一个AbstractCollection抽象类来实现这个接口,以后如果有需要就直接可以继承该抽象类。
二、具体集合的特征的对比
部分常见集合:
ArrayList(数组有序表);
LinkeList(链表有序集合);
HashSet(散列无序集合);
TreeSet(树有序集合-存无序取有序);
HashMap(散列键值对有序集合);
TreeMap(树有序键的映射的结合);
1.链表:LinkedList(实现了List接口,元素有序)
链表特点:双向链接,删除/增加元素方便,但是因为没有索引,导致只能遍历来查找元素,在随机访问(也就是有目的的访问个别元素)的时候不建议使用这种集合,可以使用ArrayList(可以存储对象)或者数组(只能存基础类型);
常用方法:List-add();Iterator-next()-迭代器后向遍历;Iterator-previous()-迭代器前向遍历;Iterator-remove()-迭代器删除;Iterator-add()-迭代器增加;
设计类时容易出现的问题,两个迭代器对同一个集合进行并发修改,导致数据错误;解决方法:创建容器类的时候,可以给类增加一个"多个迭代器"读取的方法,另外增加一个只有一个迭代器且可以“读”与“写”的方法;
2.数组列表-常见集合:ArrayList
类似集合:Vector;与ArrayList区别:Vector是线程安全的,同步的,可以多个线程同时访问,但是ArrayList是线程不安全的,不同步的,多个线程同时访问可能会出现问题;
3.散列集:散列表一般用于实现几个重要的数据结构:最简单的是set类型,set是没有任何重复元素类型的集合;
散列表:一种常见的数据结构,散列表为每个对象计算一个整数,作为散列码,而散列表使用链表数组实现,每个列表成为桶,每个同种存放相同散列码的对象索引;所以在查找的时候,可以先定位到桶,再定位到同种的元素,加快了查询的速度;
设计中的注意点:
1.将桶数设置为一个素数,防止键的聚集;(素数定义:素数也叫质数,即在正整数中,除了1与本身之外没有其他约数的数(1除外))
2.如果可以预计元素个数,一般桶数设置为元素个数的75%-150%,如果散列表过满,会根据“装填因子”再次进行散列,例如,装填因子为0.75,那么如果散列表中的元素达到了75%,那么就会用双倍的桶数再次进行散列
3.散列表的散列都是分布在散列表中的各个部分上的,所以散列表的访问是不能进行“指定索引的随机访问”的,所以只有不关心集合中元素的顺序才会用常见的散列集合,如:“HashSet”;
4.树集:树集是个有序的集合,可以将元素无序得插入到集合中,对集合遍历时,将每个值按照一定的顺序检索出;《出自:数据结构和算法导论》;
集合特点:
1.树集中添加元素的速度,比添加到散列中慢(因为需要进行一定计算),但是比添加到数组或链表中要快;
2.查找元素需要进行log2N次比较,[x=logaN对数定义:如果a的x次方等于N(a>0,且a不等于1),那么树x叫做以a为底N的对数]
5.对象的比较:树集有一个默认的比较器,实现了Comparable接口,可以进行平普通的树集元素比较,也可以进行特殊规则的比较,树集有个带有比较器的构造器,对象可以根据这个比较器规则进行比较;实现步骤如下:
1 /*编写自己的比较器*/ 2 class ItemComparator implements Comparator<Iterm> 3 { 4 public int compare(Item a,Item b) 5 String descrA = a.getDescription(); 6 String descrB = b.getDescription(); 7 return descrA.compareTo(descrB); 8 } 9 /*新建一个比较器对象*/ 10 ItemComparator comp = new ItemComparator(); 11 /*使用带比较器的构造器构造对象*/ 12 SortedSet<Item> sortByDescription = new TreeSet<>(comp); 13 14 /*下面为简化写法,用“匿名内部类”*/ 15 SortedSet<Item> sortByDescription = new TreeSet<>( 16 new Comparator<Iterm>(){ 17 String descrA = a.getDescription(); 18 String descrB = b.getDescription(); 19 return descrA.compareTo(descrB); 20 } 21 );
注意:树集和散列集具体使用哪种需要根据其特点使用;
6.双端队列:有两个端头的队列,可以同时从头部和尾部添加/删除元素,不支持从中间插入/删除元素,特征接口:Deque,实现类:ArrayDeque、LinkedList;
7.优先级队列:同Treeset类似,可以不按照顺序插入,但是按照顺序检出;
8.映射表:用于存放键值对
两个具体的实现例子为:HashMap(散列映射)、TreeMap(树结构映射),散列映射对键进行散列,树映射用键的顺序进行排列
映射表不是一个集合,但是映射表有对应的键集、值集合、键/值对集;
9.专用集与映射表类:具体需要研究
弱散列映射表
链接散列集与链接映射表
枚举集与映射表
标识散列映射表
三、集合的框架
基本概念:
框架:一个类的集,包含很多超类,具有很多有用的功能、策略和机制,框架的使用者可以直接使用子类继承框架来实现基本的功能;
集合框架的所有类:
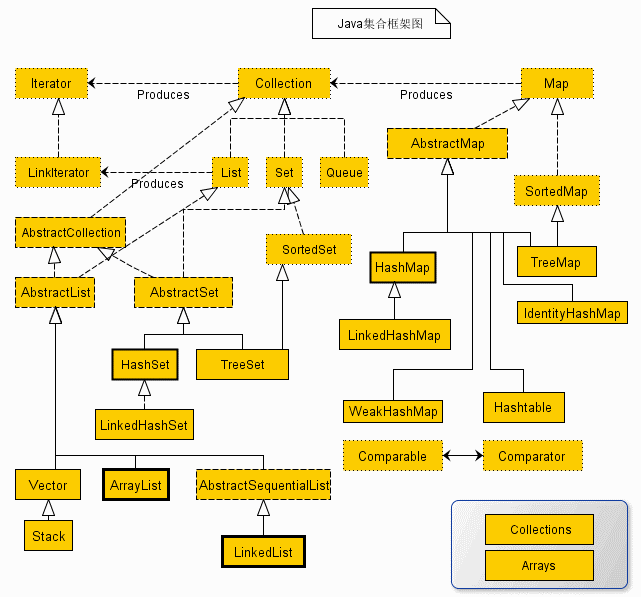
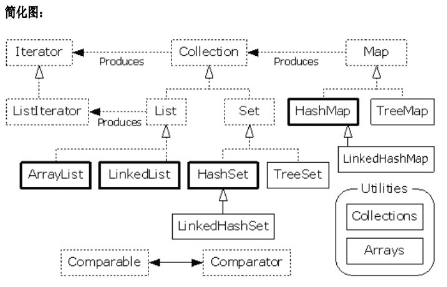
集合框架的接口:

1.视图与包装器:
视图概念:生成一个类,对原表进行操作,这种集合叫做视图;
视图应用:
a.轻量级包装器:
b.子范围:
c.不可修改的视图:
d.同部视图
e.检查视图
f.可选操作
2.批操作:常用方法:待补充
3.集合与数组之间的转换方式:待补充
四、算法(只介绍部分处理集合的算法)
1.排序与混排(待补充)
2.二分查找(待补充)
3.简单算法(待补充)
4.编写自己的算法(待补充)
五、遗留的集合
1.Hashtable类(待补充)
2.枚举(待补充)
3.属性映射表(待补充)
4.栈(待补充)
5.位集(待补充)