(一)使用explain查看是否使用索引主要是以下这些列:
type:
| ALL | 表示全表扫描 | |
| const | 表示通过唯一索引或主键一次就找到了 | |
| ref | 非主键和唯一索引 |
key:
| NULL | 表示没有使用索引 |
| primary | 表示使用了主键 |
| 其它 | 普通索引 |
extra:
| using filesort |
排序时无法使用到索引时 |
| using where /using index |
不清楚 |
表:
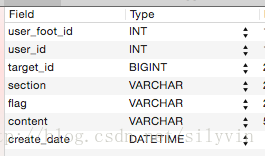
以下蓝色为使用索引,红色为未使用索引
主键:user_foot_id

type-const key-primary
不加索引:
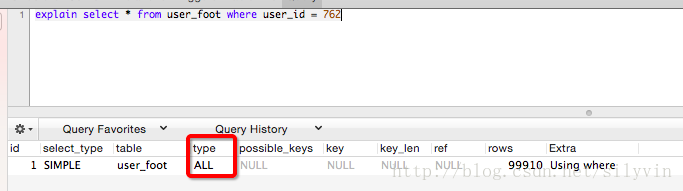
type-all key-null extra-using where
user_id 索引
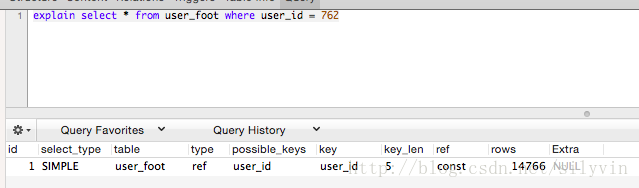
type-ref key-user_id
排序
user_id 索引

type-ref key-user_id extra-using where, using filesort
user_id + create_date 联合索引
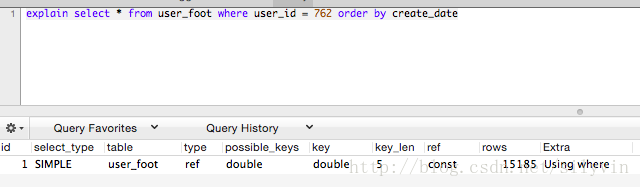
type-ref key-double extra-using where
create_date 索引
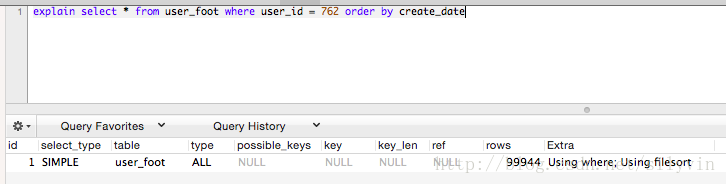
type-all key-null extra-using where, using filesort
create_date + user_id 联合索引
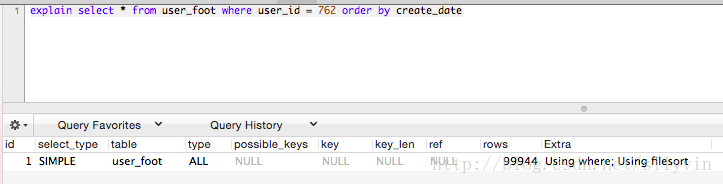
type-all key-null extra-using where, using filesort
user_id 索引
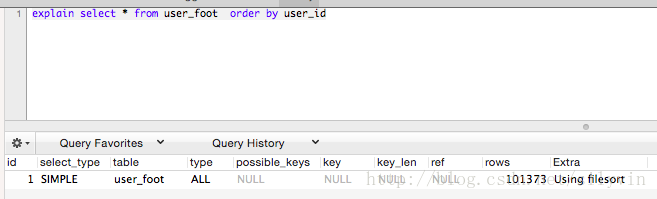
type-all key-null extra-using where, using filesort
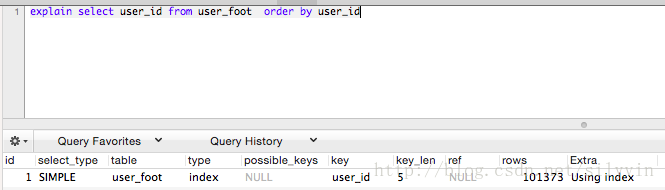
type-index key-user_id extra-using index
这就比较奇怪了,查了
explain 关于 order by 与索引
http://blog.csdn.net/superhosts/article/details/25720915
得到3个重要结论:
1) 如果这个图select 只查询索引字段,order by 索引字段会用到索引,要不然就是全表排列;
2) 如果有where 条件,这样order by 也会用到索引!
3) 如果即要查别的非索引字段,又没有where条件怎么办:造一个对索引字段的固定范围,放到where里:
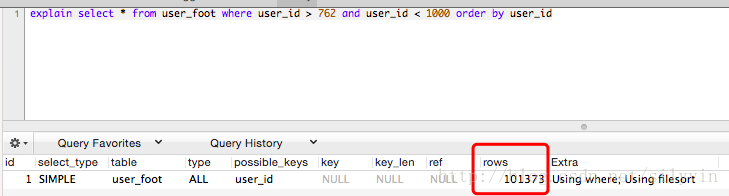
还是不行,也许order by 使用索引有行数限制,调整一下:

ok了
故,用不用索引不能单看经验,必须使用expalin实测
(二)然后补充一个连接:type
MySQL的Explain关键字查看是否使用索引
https://www.cnblogs.com/david97/p/8072164.html
-
type
-
依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
-
A:system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
-
B:const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
-
C:eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
-
D:ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
-
E:fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
-
F:ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
-
G:unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
-
H:index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
-
I:range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
-
J:index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
-
K:index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
-
L:all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
主要是 4种
const-唯一索引或主键
ref -非唯一索引和主键
range-索引范围(阿里要求)
all-未使用索引
https://www.cnblogs.com/acm-bingzi/p/mysqlExplain.html

