http://www.cnblogs.com/wangguchangqing/p/6070286.html
想实现个循环缓冲区(Circular Buffer),搜了些资料多数是基于循环队列的实现方式。使用一个变量存放缓冲区中的数据长度或者空出来一个空间来判断缓冲区是否满了。偶然间看到分析Linux内核的循环缓冲队列kfifo的实现,确实极其巧妙。kfifo主要有以下特点:
- 保证缓冲空间的大小为2的次幂,不是的向上取整为2的次幂。
- 使用无符号整数保存输入(in)和输出(out)的位置,在输入输出时不对in和out的值进行模运算,而让其自然溢出,并能够保证
in-out的结果为缓冲区中已存放的数据长度,这也是最能体现kfifo实现技巧的地方; - 使用内存屏障(Memory Barrier)技术,实现单消费者和单生产者对
kfifo的无锁并发访问,多个消费者、生产者的并发访问还是需要加锁的。
本文主要以下三个部分:
- 关于2的次幂问题,判断是不是2的次幂以及向上取整为2的次幂
- Linux内核中
kfifo的实现及简要分析 - 根据
kfifo实现的循环缓冲区,并进行一些测试
关于内存屏障的本文不作过多分析,可以参考WikiMemory Barrier。另外,本文所涉及的整数都默认为无符号整数,不再做一一说明。
1. 2的次幂
-
判断一个数是不是2的次幂
kfifo要保证其缓存空间的大小为2的次幂,如果不是则向上取整为2的次幂。其对于2的次幂的判断方式也是很巧妙的。如果一个整数n是2的次幂,则二进制模式必然是1000...,而n-1的二进制模式则是0111...,也就是说n和n-1的每个二进制位都不相同,例如:8(1000)和7(0111);n不是2的次幂,则n和n-1的二进制必然有相同的位都为1的情况,例如:7(0111)和6(0110)。这样就可以根据n & (n-1)的结果来判断整数n是不是2的次幂,实现如下:/* 判断n是否是2的幂 若n为2的次幂, 则 n & (n-1) == 0,也就是n和n-1的各个位都不相同。例如 8(1000)和7(0111) 若n不是2的次幂, 则 n & (n-1) != 0,也就是n和n-1的各个位肯定有相同的,例如7(0111)和6(0110) */ static inline bool is_power_of_2(uint32_t n) { return (n != 0 && ((n & (n - 1)) == 0)); } -
将数字向上取整为2的次幂
如果设定的缓冲区大小不是2的次幂,则向上取整为2的次幂,例如:设定为5,则向上取为8。上面提到整数n是2的次幂,则其二进制模式为100...,故如果正数k不是n的次幂,只需找到其最高的有效位1所在的位置(从1开始计数)pos,然后1 << pos即可将k向上取整为2的次幂。实现如下:static inline uint32_t roundup_power_of_2(uint32_t a) { if (a == 0) return 0; uint32_t position = 0; for (int i = a; i != 0; i >>= 1) position++; return static_cast<uint32_t>(1 << position); }
2. Linux实现kfifo及分析
Linux内核中kfifo实现技巧,主要集中在放入数据的put方法和取数据的get方法。代码如下:
unsigned int __kfifo_put(struct kfifo *fifo, unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/*
* Ensure that we sample the fifo->out index -before- we
* start putting bytes into the kfifo.
*/
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len;
return len;
}
unsigned int __kfifo_get(struct kfifo *fifo,unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len;
return len;
} put返回实际保存到缓冲区中的数据长度,get返回的是实际取到的数据长度。在上面代码中,需要注意到在写入、取出时候的两次min运算。关于kfifo的分析,已有很多资料了,也可参考眉目传情之匠心独运的kfifo 。
Linux内核实现的kfifo的有以下特点:
- 使用内存屏障 Memory Barrier
- 初始化缓冲区空间时要保证缓冲区的大小为2的次幂
- 使用无符号整数保存in和out(输入输出的指针),并且在放入取出数据的时候不做模运算,让其自然溢出。
优点:
- 实现单消费者和单生产者的无锁并发访问。多消费者和多生产者的时候还是需要加锁的。
- 使用与运算
in & (size-1)代替模运算 -
在更新in或者out的值时不做模运算,而是让其自动溢出。这应该是kfifo实现最牛叉的地方了,利用溢出后的值参与运算,并且能够保证结果的正确。溢出运算保证了以下几点:
- in - out为缓冲区中的数据长度
- size - in + out 为缓冲区中空闲空间
- in == out时缓冲区为空
- size == (in - out)时缓冲区满了
3.模仿kfifo实现的循环缓冲
主要是模仿其无符号溢出的运算方法,并没有利用内存屏障实现单生产者和单消费者的无锁并发访问。初始化及输入输出的代码如下:
struct kfifo{
uint8_t *buffer;
uint32_t in; // 输入指针
uint32_t out; // 输出指针
uint32_t size; // 缓冲区大小,必须为2的次幂
kfifo(uint32_t _size)
{
if (!is_power_of_2(_size))
_size = roundup_power_of_2(_size);
buffer = new uint8_t[_size];
in = 0;
out = 0;
size = _size;
}
// 返回实际写入缓冲区中的数据
uint32_t put(const uint8_t *data, uint32_t len)
{
// 当前缓冲区空闲空间
len = min(len,size - in + out);
// 当前in位置到buffer末尾的长度
auto l = min(len, size - (in & (size - 1)));
// 首先复制数据到[in,buffer的末尾]
memcpy(buffer + (in & (size - 1)), data, l);
// 复制剩余的数据(如果有)到[buffer的起始位置,...]
memcpy(buffer, data + l, len - l);
in += len; // 直接加,不作模运算。当溢出时,从buffer的开始位置重新开始
return len;
}
// 返回实际读取的数据长度
uint32_t get(uint8_t *data, uint32_t len)
{
// 缓冲区中的数据长度
len = min(len, in - out);
// 首先从[out,buffer end]读取数据
auto l = min(len, size - (out & (size - 1)));
memcpy(data, buffer + (out & (size - 1)), l);
// 从[buffer start,...]读取数据
memcpy(data + l, buffer, len - l);
out += len; // 直接加,不错模运算。溢出后,从buffer的起始位置重新开始
return len;
}在初始化缓冲空间的时候要验证size是否为2的次幂,如果不是则向上取整为2的次幂。下面着重分析下在放入取出数据时对指针in和out的处理,以及在溢出后怎么能够保证in - out仍然为缓冲区中的已有的数据长度。
put和get方法详解
在向缓冲区中put数据的时候,需要两个参数:要put的数据指针data和期望能够put的数据长度len,返回值是实际存放到缓冲区中的数据长度(当缓冲区中空间不足时该值小于len)。下面详细的解释下put中每个语句的作用。
put函数中的第一句是len = min(len,size - in + out)计算实际向缓冲区中写入数据的大小。如果想要写入的数据len大于缓冲区中的空闲空间size - in + out,则只填充满缓冲空间。
因为是循环缓冲区,所以其空闲空间有两部分:从in到缓冲空间的末尾->[in,buffer end]和缓冲空间的起始位置到out->[buffer start,out]。
auto l = min(len, size - (in & (size - 1)));这个是判断[in,buffer end]这部分空间是否足够写入数据memcpy(buffer + (in & (size - 1)), data, l);向[in,buffer end]这部分空间写入数据memcpy(buffer, data + l, len - l);如果数据还没有写完,则向[buffer start,out]这部分空间写入数据。in += len更新in,不做模运算,让其自然溢出。
get和put很类似,首先判断是否有足够的数据取出;在取数据时首先从out取到buffer的末尾,如果不够则从buffer的开始位置取;最后更新out时也是不做模运算,让其溢出。看参看上面put的语句解释,这里就不再多说。
无符号溢出运算
kfifo之所以如次的简洁,很大一部分要归功于其in和out的溢出运算。这里就解释下在溢出的情况下,如何保证in - out仍然为缓冲区中的数据长度。首先来看图:
-
缓冲区为空
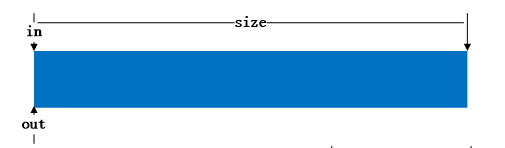
-
put 一堆数据后

-
get 一堆数据后

-
put的数据长度超过in到buffer末尾的长度,有一部分从put到buffer的起始位置

以上图片引用自linux内核数据结构之kfifo,其对
kfifo的分析也很详细。
前三种情况下从图中可以很清晰的看出in - out为缓冲区中的已有的数据长度,但是最后一种发现in跑到了out的前面,这时候in - out不是应该为负的么,怎么能是数据长度?这正是kfifo的高明之处,in和out都是无符号整数,那么在in < out 时in - out就是负数,把这个负数当作无符号来看时,其值仍然是缓冲区中的数据长度。这和in累加到溢出的情况基本一致,这里放在一起说。
这里使用8位无符号整数来保存in和out,方便溢出。这里假设out = 100,in = 255,size = 256,如下图
/*
--------------------------------------
| | | |
--------------------------------------
out = 100 in = 250
这时缓冲区中已有的数据为:in - out = 150,空闲空间为:size - (in - out) = 106
向缓冲区中put10个数据后
--------------------------------------
| | | |
--------------------------------------
in out
这时候 in + 10 = 260 溢出变为in = 4;这是 in - out = 4 - 100 = -96,仍然溢出-96十六进制为`0xA0`,将其直接转换为有符号数`0xA0 = 160`,在没put之前的数据为150,put10个后,缓冲区中的数据刚好为160,刚好为溢出计算结果。
*/进行上述运算的前提是,size必须为2的次幂。假如size = 257,则上述的运行就不会成功。
测试实例
上面描述都是基于运算推导的,下面据结合本文中的代码进行下验证。
测试代码如下:设置空间大小为128,in和out为8位无符号整数
int main()
{
uint8_t output[512] = { 0 };
uint8_t data[256] = { 0 };
for (int i = 0; i < 256; i++)
data[i] = i;
kfifo fifo(128);
fifo.put(data, 100);
fifo.get(output, 50);
fifo.put(data, 30);
auto c = fifo.put(data + 10, 92);
cout << "Empty:" << fifo.isEmpty() << endl;
cout << "Left Space:" << fifo.left() << endl;
cout << "Length:" << fifo.length() << endl;
uint8_t a = fifo.size - fifo.in + fifo.out;
uint8_t b = fifo.in - fifo.out;
cout << "=======================================" << endl;
fifo.get(output, 128);
cout << "Empty:" << fifo.isEmpty() << endl;
cout << "Left Space:" << fifo.left() << endl;
cout << "Length:" << fifo.length() << endl;
cout << "======================================" << endl;
fifo.put(output, 100);
cout << "Empty:" << fifo.isEmpty() << endl;
auto d = static_cast<uint8_t>(fifo.left());
auto e = static_cast<uint8_t>(fifo.length());
printf("Left Space:%d
", d);
printf("Length:%d
", e);
getchar();
return 0;
}执行结果:
- 第一个输出是将缓冲区填满的状态
- 第二个输出是将缓冲区取空的状态
- 第三个是in溢出的情况,具体来看看:
在第二个输出将缓冲区取空的时候,in = out = 178。接着,向缓冲区put了100个数据,这时候in += 100会溢出,溢出后in = 22。看输出结果:put前缓冲区为空,put100个数据后,缓冲区的空闲空间为28,数据长度为100,是正确的。