本文转载自:https://blog.csdn.net/xiaosongshine/article/details/90600028
一、Self-Attention概念详解
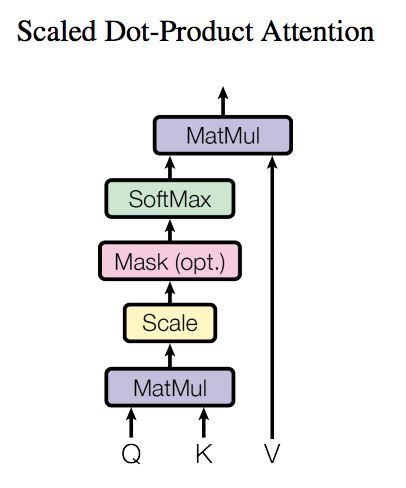
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度 其中
其中 为一个query和key向量的维度。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为

如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示

其中 是我们模型训练过程学习到的合适的参数。上述操作即可简化为矩阵形式
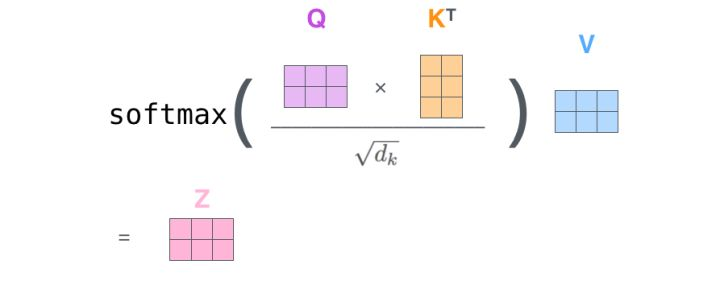
二、Self_Attention模型搭建
笔者使用Keras来实现对于Self_Attention模型的搭建,由于网络中间参数量比较多,这里采用自定义网络层的方法构建Self_Attention,关于如何自定义Keras可以参看这里:编写你自己的 Keras 层
Keras实现自定义网络层。需要实现以下三个方法:(注意input_shape是包含batch_size项的)
- build(input_shape): 这是你定义权重的地方。这个方法必须设 self.built = True,可以通过调用 super([Layer], self).build() 完成。
- call(x): 这里是编写层的功能逻辑的地方。你只需要关注传入 call 的第一个参数:输入张量,除非你希望你的层支持masking。
- compute_output_shape(input_shape): 如果你的层更改了输入张量的形状,你应该在这里定义形状变化的逻辑,这让Keras能够自动推断各层的形状
from keras.preprocessing import sequence
from keras.datasets import imdb
from matplotlib import pyplot as plt
import pandas as pd
from keras import backend as K
from keras.engine.topology import Layer
class Self_Attention(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(Self_Attention, self).__init__(**kwargs)
def build(self, input_shape):
# 为该层创建一个可训练的权重
#inputs.shape = (batch_size, time_steps, seq_len)
self.kernel = self.add_weight(name='kernel',
shape=(3,input_shape[2], self.output_dim),
initializer='uniform',
trainable=True)
super(Self_Attention, self).build(input_shape) # 一定要在最后调用它
def call(self, x):
WQ = K.dot(x, self.kernel[0])
WK = K.dot(x, self.kernel[1])
WV = K.dot(x, self.kernel[2])
print("WQ.shape",WQ.shape)
print("K.permute_dimensions(WK, [0, 2, 1]).shape",K.permute_dimensions(WK, [0, 2, 1]).shape)
QK = K.batch_dot(WQ,K.permute_dimensions(WK, [0, 2, 1]))
QK = QK / (64**0.5)
QK = K.softmax(QK)
print("QK.shape",QK.shape)
V = K.batch_dot(QK,WV)
return V
def compute_output_shape(self, input_shape):
return (input_shape[0],input_shape[1],self.output_dim)