上篇我们实现了分布式爬取,本篇来说下爬虫的部署。
分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序。这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修改好代码后,重新打包上传然后执行(当然你愿意每台登上去后修改代码也行)。本篇我们使用scrapd来进行部署。
使用scrapyd来部署爬虫大体只需要几步:
- 在需要运行爬虫的主机上安装scrapyd,并且启动scrapyd服务
- 使用scrapy-client把项目打包成egg文件,部署到scrapyd服务
- 使用scrapyd提供的网络API来对爬虫进行操作,包括启动爬虫、停止爬虫等操作。
一、安装相关的库
pip install scrapyd (需要运行爬虫的主机都要安装)
pip install scrapyd-client (本机主机安装即可,作用是为了把爬虫项目部署到远程主机的scrapyd去)
二、修改scrapyd配置文件
[root@kongqing /]# whereis scrapyd scrapyd: /etc/scrapyd /root/.pyenv/shims/scrapyd [root@kongqing /]# cd /etc/scrapyd [root@kongqing scrapyd]# ls scrapyd.conf [root@kongqing scrapyd]# vim scrapyd.conf
bind_address=0.0.0.0 #修改为0.0.0.0可以使用其他任意主机进行连接
三、启动scrapyd,直接命令行输入scrapyd(这样就启动了一个网络的监听,端口默认是6800)

四、使用本机浏览器打开47.98.xx.xx:6800 (前面换成自己安装好scrapyd的远程主机IP地址)
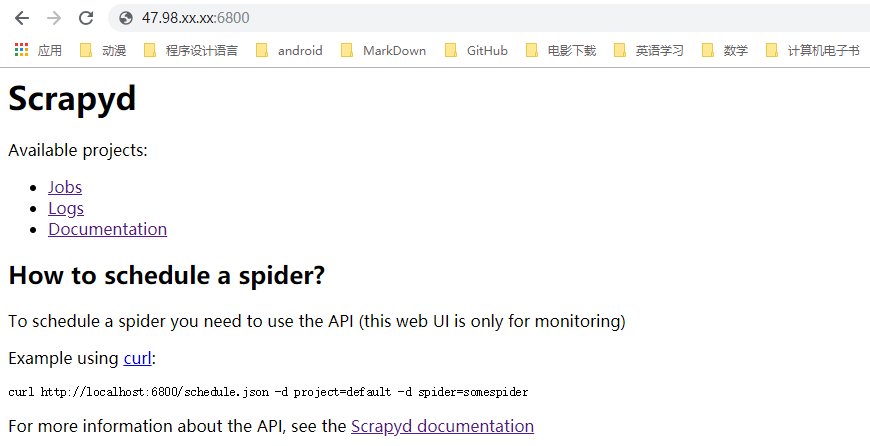
解释一波:
- jobs代表的就是爬虫项目
- logs代表的是日志文件,也就是你爬虫运行时显示的那些信息
- Documentation这个指的scrapyd的文档,教你对爬虫项目进行启停等操作的
当然,目前里面还没有项目,所以jobs、logs里面都是空的。
五、修改本地爬虫文件scrapy.cfg文件(前面解释过,这个文件是用来做爬虫部署用的)
[settings] default = lagou.settings [deploy] #url = http://localhost:6800/ #本地的直接能运行,我就不改了 project = lagou [deploy:aliyun] #:后面是别名,自己设置,用来识别部署的是哪台设备,避免弄混 url = http://47.98.xx.xx:6800/ #远程主机的地址及端口 project = lagou
六、使用scrapyd_client将项目部署到远程主机
- 在scrapy.cfg文件所在目录打开cmd命令行,(地址栏输入cmd,或者shift+右键打开)
- 执行部署命令scrapyd-deploy aliyun --version 201812010050

解释一波:
- 如果只输入命令scrapyd-deploy就是直接部署本机了,因为本机没有跟别名
- aliyun代表的是我的远程主机,也就是scrapy.cfg文件中的[deploy:aliyun]这部分。建议大家加别名,方便识别管理。
- --version是可选的,代表一个版本,后面的数字我是使用的当前时间,自己可以根据需要设置。默认是时间戳,也就是不使用--version它也会默认给你生成一个版本信息。
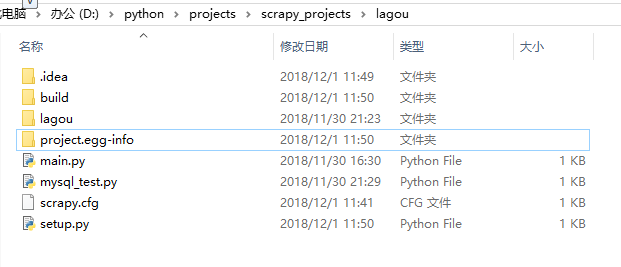
- 可以看到,成功执行部署命令后,本地项目目录多了两个文件夹
七、使用scrapyd网络API启停爬虫
打开API文档看一下,我们可以看到有以下这些方法:
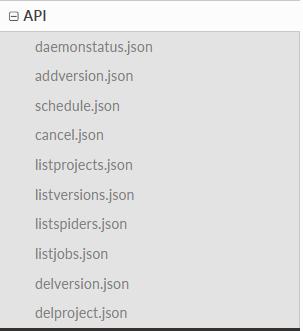
这里只解释两个用法,其他的自己看文档。
shedule.json:运行一个爬虫(会返回一个jobid),文档示例用法如下:
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
cancel.json:停止一个爬虫(需要有jobid),文档示例用法如下:
$ curl http://localhost:6800/cancel.json -d project=myproject -d job=6487ec79947edab326d6db28a2d86511e8247444
现在我们启动我们自己在远程主机上的爬虫项目。
- 首先执行以下代码:
curl http://47.98.xx.xx:6800/schedule.json -d project=lagou -d spider=lagou_c #修改为自己的远程主机IP,项目名是lagou,spider名字是lagou_c
- 我们用浏览器打开47.98.xx.xx:6800看下jobs,可以看到有一个爬虫在运行了
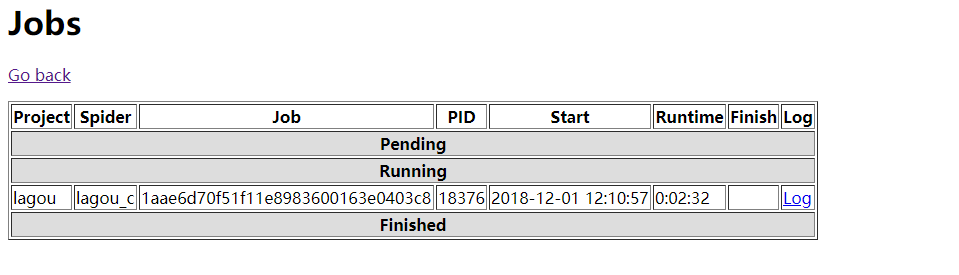
- 注意到那个蓝色的Log了么,爬虫的调试信息都在这里,我们点击就可以看到爬虫运行时的信息了

- 现在我们停止这个爬虫,使用命令
curl http://47.98.xx:xx/cancel.json -d project=lagou -d job=1aae6d70f51f11e8983600163e0403c8 (需要修改为自己的远程主机IP,项目名称,job就是之前运行时候的jobid
- 我们现在再到网页里看一下,显示刚刚那个爬虫已经停止了:
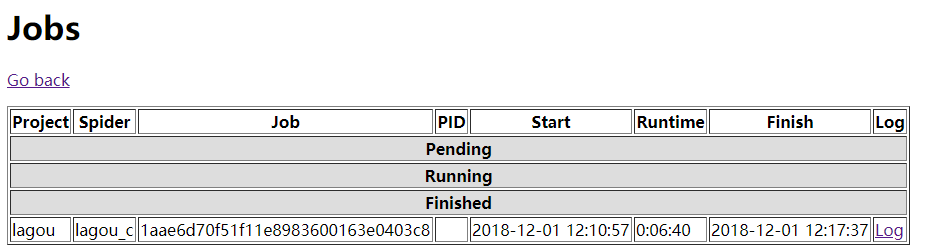
这样我们使用scrapyd就完成了爬虫部署到远程服务器的过程,如果你觉得使用网络API调用的方式不习惯的话,也可以用scrapyd_api来调用,不过需要生成egg文件,地址在这里,有兴趣的可以尝试。