六、Hadoop1.x与Hadoop2的区别
1、变更介绍
Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更:
l HDFS的NameNodes可以以集群的方式布署,增强了NameNodes的水平扩展能力和可用性;
l MapReduce将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator)。
1.1、HDFS的变化 - 增强了NameNode的水平扩展及可用性
1.1.1、Hadoop的1.X架构的介绍
而在1.x中的NameNodes只可能有一个,虽然可以通过SecondaryNameNode与NameNode进行数据同步备份,但是总会存在一定的时延,如果NameNode挂掉,但是如果有部份数据还没有同步到SecondaryNameNode上,还是可能会存在着数据丢失的问题。
架构如下:
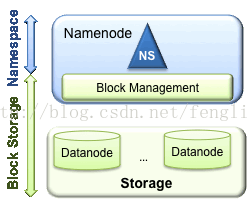
包含两层:
Namespace
l 包含目录、文件以及块的信息
l 支持对Namespace相关文件系统的操作,如增加、删除、修改以及文件和目录的展示
Block Storage Service包含两部份
l 块管理(在Namenode中实现的)
提供数据节点群集成员的登记,并定期通过心跳进行检查。
提供块报告以及块的存储位置的维护
提供对块的操作,如对块进行增删改的操作及获取块的存储地址
对块的复本的的复制以及存储位置的管理
l 存储 - 提供Datanode进行数据的本地存储,并提供读写的操作
1.1.1、Hadoop的2.X架构的介绍
在2.X中,HDFS的变化,主要体现在增强了NameNode的水平扩展及可用性,可以同时部署多个NameNode,这些NameNodes之间是相互独立,也就是说他们不需要相互协调,DataNode同时在所有NameNodes注册,做为他们共有的存储节点,并向定时向所有的这些NameNodes发送心跳块使用情况的报告,并处理所有NameNodes向其发送的指令。
架构如下:
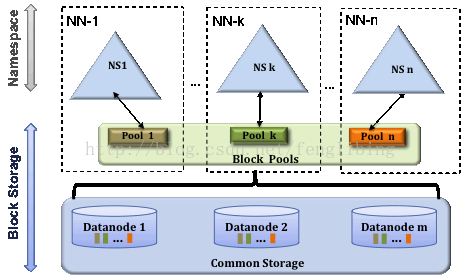
存储块池(Block Pool)
一个存储块池是由一组存储块组成,它属于一个单独的Namespace(Namenode),集群中所有存储块池的存储块都是存放在Datanodes中的。每个存储块池与其它的存储块池都是独立管理的,因而其在为新的块生成Block IDs时,就不需要与其它Namespace(Namenode)中的存储块池进行协作,即使一个Namespace(Namenode)挂掉了,也不会使得Datanodes中的块被访问不到,因为其它Namespace(Namenode)中的存储块池也存放了Datanodes中所有存储块的信息。
一个命名空间(Namespace)和它的块池一起被称为命名空间向量。它是一个自包含的管理单元。当一个Namenode/namespace被删除,存储于Datanodes中的相应的存储块池也会被删除掉,在集群的更新过程中,每个命名空间向量都是以一个整体进行升级的。
集群ID(ClusterID)
集群ID的加入,是用于确认集群中所有的节点,也可以在格式化其它Namenodes时指定集群ID,并使其加入到某个集群中。
1.2、MapReduce拆分JobTracker为资源管理及任务生命周期管理两个独立的组件
MapReduce在Hadoop2中称为MR2或YARN,将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的服务,用于管理全部资源的ResourceManager以及管理每个应用的ApplicationMaster,ResourceManager用于管理向应用程序分配计算资源,每个ApplicationMaster用于管理应用程序、调度以及协调。一个应用程序可以是经典的MapReduce架构中的一个单独的任务,也可以是这些任务的一个DAG(有向无环图)任务。ResourceManager及每台机上的NodeManager服务,用于管理那台机的用户进程,形成计算架构。每个应用程序的ApplicationMaster实际上是一个框架具体库,并负责从ResourceManager中协调资源及与NodeManager(s)协作执行并监控任务。
架构图:
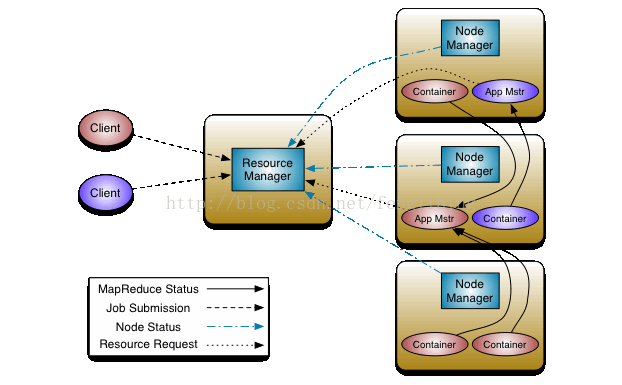
其中ResourceManager包含两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
定时调用器(Scheduler):
定时调度器负责向应用程序分配置资源,它不做监控以及应用程序的状 态跟踪,并且它不保证会重启由于应用程序本身或硬件出错而执行失败 的应用程序。
应用管理器(ApplicationManager):
应用程序管理器负责接收新任务,协调并提供在ApplicationMaster容 器失败时的重启功能。
节点管理器(NodeManager):
NodeManager是ResourceManager在每台机器的上代理,负责容器的管 理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler提供这些资源使用报告。
应用总管(ApplicationMaster):
每个应用程序的ApplicationMaster负责从Scheduler申请资源,以及 跟踪这些资源的使用情况以及任务进度的监控。
2、具体变化
2.1、配置文件的路径
在1.x中,Hadoop的配置文件是放在$HADOOP_HOME/conf目录下的,关键的配置文件在src目录都有对应的存放着默认值的文件,如下:
|
配置文件 |
默认值配置文件 |
|
$HADOOP_HOME/conf/core-site.xml |
$HADOOP_HOME/src/core/core-default.xml |
|
$HADOOP_HOME/conf/hdfs-site.xml |
$HADOOP_HOME/src/hdfs/hdfs-default.xml |
|
$HADOOP_HOME/conf/mapred-site.xml |
$HADOOP_HOME/src/mapred/mapred-default.xml |
我们在$HADOOP_HOME/conf下面配置的core-site.xml等的值,就是对默认值的一个覆盖,如果没有在conf下面的配置文件中设置,那么就使用src下面对应文件中的默认值,这个在使用过程中非常方便,也非常有助于我们理解。
Hadoop可以说是云计算的代名词,其也有很多衍生的产品,不少衍生的配置方式都遵从Hadoop的这种配置方式,如HBase的配置文件也是$HBase/conf目录,核心配置的名称就是hbase-site.xml,如果学习了Hadoop再去学习HBase,从配置的理解上来说,就会有一种亲切的感觉。
可是在2.x中,Hadoop的架构发生了变化,而配置文件的路径也发生了变化,放到了$HADOOP_HOME/etc/hadoop目录,这样修改的目的,应该是让其更接近于Linux的目录结构吧,让Linux用户理解起来更容易。Hadoop 2.x中配置文件的几个主要的变化:
l 去除了原来1.x中包括的$HADOOP_HOME/src目录,该目录包括关键配置文件的默认值;
l 默认不存在mapred-site.xml文件,需要将当前mapred-site.xml.template文件copy一份并重命名为mapred-site.xml,并且只是一个具有configuration节点的空文件;
l 默认不存在mapred-queues.xml文件,需要将当前mapred-queues.xml.template文件copy一份并重命名为mapred-queues.xml;
l 删除了master文件,现在master的配置在hdfs-site.xml通过属性dfs.namenode.secondary.http-address来设置,如下:
|
<property> <name>dfs.namenode.secondary.http-address</name> <value>nginx1:9001</value> </property> |
l 增加了yarn-env.sh,用于设置ResourceManager需要的环境变量,主要需要修改JAVA_HOME;
l 增加yarn-site.xml配置文件,用于设置ResourceManager;
2.2、命令文件目录的变化
在1.x中,所有的命令文件,都是放在bin目录下,没有区分客户端和服务端命令,并且最终命令的执行都会调用hadoop去执行;而在2.x中将服务端使用的命令单独放到了sbin目录,其中有几个主要的变化:
l 将./bin/hadoop的功能分离。在2.x中./bin/hadoop命令只保留了这些功能:客户端对文件系统的操作、执行Jar文件、远程拷贝、创建一个Hadoop压缩、为每个守护进程设置优先级及执行类文件,另外增加了一个检查本地hadoop及压缩库是否可用的功能,详情可以通过命令“hadoop -help”查看。
而在1.x中,./bin/hadoop命令还包括:NameNode的管理、DataNode的管理、 TaskTracker及JobTracker的管理、服务端对文件系统的管理、文件系统的检查、获取队列 信息等,详情可以通过命令“hadoop -help”查看。
l 增加./bin/hdfs命令。./bin/hadoop命令的功能被剥离了,并不是代表这些命令不需要了,而是将这些命令提到另外一个名为hdfs的命令中,通过hdfs命令可以对NameNode格式化及启动操作、启动datanode、启动集群平衡工具、从配置库中获取配置信息、获取用户所在组、执行DFS的管理客户端等,详细可以通过“hdfs -help”查看。
l 增加./bin/yarn命令。原来1.x中对JobTracker及TaskTracker的管理,放到了新增的yarn命令中,该命令可以启动及管理ResourceManager、在每台slave上面都启一个NodeManager、执行一个JAR或CLASS文件、打印需要的classpath、打印应用程序报告或者杀死应用程序等、打印节点报告等,详情可以通过命令“yarn -help”查看。
l 增加./bin/mapred命令。该命令可以用于执行一个基于管道的任务、计算MapReduce任务、获取队列的信息、独立启动任务历史服务、远程目录的递归拷贝、创建hadooop压缩包,详情可以通过“./mapred -help”。
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow