当我们要做一个主题分析时,基本上都会有这样一个流程,采集数据,数据预处理,数据入库,数据分析等一系列的操作。但是这些操作往往我们需要布置做一遍,有时候甚至需要定时定点的去做,比如数据采集。当我们每天都需要做一系列的重复的工作时,我们肯定首先就是想到,能不能我只做一遍,剩下的交给一个机器人自动帮我完成或者交给电脑自动帮我完成。
这时候领克就推出了一款叫做azkaban的工作流调度软件,是开源免费的。我们的Apache基金会呢也有一款开源的工作流调度软件,名为oozie。它俩都是作为工作流调度的软件,都能帮我们实现一系列工作的调度,但是它们之间实现的原理却不太一样。
Azkaban与Oozie的介绍
Azkaban是由linkedin(领英)公司推出的一个批量工作流任务调度器,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
Oozie 是一个用来管理 Hadoop生态圈job的工作流调度系统。由Cloudera公司贡献给Apache。Oozie是运行于Java servlet容器上的一个java web应用。Oozie的目的是按照DAG(有向无环图)调度一系列的Map/Reduce或者Hive等任务。Oozie 工作流由hPDL(Hadoop Process Definition Language)定义(这是一种XML流程定义语言)。
Azkaban与Oozie的原理
Azkaban:

mysql服务器: 存储元数据,如项目名称、项目描述、项目权限、任务状态、SLA规则等
AzkabanWebServer:对外提供web服务,使用户可以通过web页面管理。职责包括项目管理、权限授权、任务调度、监控executor。
AzkabanExecutorServer:负责具体的工作流的提交、执行。
Oozie:
Oozie对工作流的编排,是基于workflow.xml文件来完成的。用户预先将工作流执行规则定制于workflow.xml文件中,并在job.properties配置相关的参数,然后由Oozie Server向MR提交job来启动工作流。
Azkaban与Oozie的安装
Azkaban:
Azkaban三种部署模式
- solo server mode:该模式中webServer和executorServer运行在同一个进程中,进程名是AzkabanSingleServer。使用自带的H2数据库。这种模式包含Azkaban的所有特性,但一般用来学习和测试。
- two-server mode: 该模式使用MySQL数据库, Web Server和Executor Server运行在不同的进程中。
- multiple-executor mode该模式使用MySQL数据库, Web Server和Executor Server运行在不同的机器中。且有多个Executor Server。该模式适用于大规模应用。
Azkaban源码编译
Azkaban3.x在安装前需要自己编译成二进制包。并且提前安装好Maven、Ant、Node等软件。
编译环境
yum install –y git
yum install –y gcc-c++
下载源码并解压
wget https://github.com/azkaban/azkaban/archive/3.51.0.tar.gz
tar -zxvf 3.51.0.tar.gz
cd ./azkaban-3.51.0/
编译源码
./gradlew build installDist -x test
编译成功之后就可以在指定的路径下取得对应的安装包了。
#solo-server模式安装包路径
azkaban-solo-server/build/distributions/
#two-server模式和multiple-executor模式web-server安装包路径
azkaban-web-server/build/distributions/
#two-server模式和multiple-executor模式exec-server安装包路径
azkaban-exec-server/build/distributions/
#数据库相关安装包路径
azkaban-db/build/distributions/
Azkaban的安装,这里就不讲solo模式的和two server模式的了,步骤都是一样的,只是安装的机器不同而已。
节点规划

安装包解压到指定目录
mkdir /export/servers/azkaban
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz –C /export/servers/azkaban/
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz –C /export/servers/azkaban/
配置web-server服务器
生成ssl证书:
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成keystore的密码及相应信息,输入的密码请记住。
完成上述工作后,将在当前目录生成keystore证书文件,将keystore拷贝到 azkaban web服务器根目录中。
如: cp keystore azkaban-web-server-0.1.0-SNAPSHOT/
配置conf/azkaban.properties:
# Azkaban Personalization Settings azkaban.name=Test azkaban.label=My Local Azkaban azkaban.color=#FF3601 azkaban.default.servlet.path=/index web.resource.dir=web/ default.timezone.id=Asia/Shanghai # 时区注意后面不要有空格 # Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager user.manager.xml.file=conf/azkaban-users.xml # Azkaban Jetty server properties. 开启使用ssl 并且知道端口 jetty.use.ssl=true jetty.ssl.port=8443 jetty.maxThreads=25 # Azkaban Executor settings 指定本机Executor的运行端口 executor.host=localhost executor.port=12321 # KeyStore for SSL ssl相关配置 注意密码和证书路径 jetty.keystore=keystore jetty.password=123456 jetty.keypassword=123456 jetty.truststore=keystore jetty.trustpassword=123456 # Azkaban mysql settings by default. Users should configure their own username and password. database.type=mysql mysql.port=3306 mysql.host=node-1 mysql.database=azkaban_two_server mysql.user=root mysql.password=hadoop mysql.numconnections=100 #Multiple Executor 设置为false azkaban.use.multiple.executors=true #azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1 azkaban.executorselector.comparator.Memory=1 azkaban.executorselector.comparator.LastDispatched=1 azkaban.executorselector.comparator.CpuUsage=1
添加azkaban.native.lib=false 和 execute.as.user=false属性:
1 mkdir -p plugins/jobtypes 2 3 vim commonprivate.properties 4 #键入下方代码 5 azkaban.native.lib=false 6 7 execute.as.user=false 8 9 memCheck.enabled=false
exec-server服务器配置
配置conf/azkaban.properties:
1 # Azkaban Personalization Settings 2 azkaban.name=Test 3 azkaban.label=My Local Azkaban 4 azkaban.color=#FF3601 5 azkaban.default.servlet.path=/index 6 web.resource.dir=web/ 7 default.timezone.id=Asia/Shanghai 8 9 # Azkaban UserManager class 10 user.manager.class=azkaban.user.XmlUserManager 11 user.manager.xml.file=conf/azkaban-users.xml 12 13 # Loader for projects 14 executor.global.properties=conf/global.properties 15 azkaban.project.dir=projects 16 17 # Where the Azkaban web server is located 18 azkaban.webserver.url=https://node-2:8443 19 20 # Azkaban mysql settings by default. Users should configure their own username and password. 21 database.type=mysql 22 mysql.port=3306 23 mysql.host=node-1 24 mysql.database=azkaban_two_server 25 mysql.user=root 26 mysql.password=hadoop 27 mysql.numconnections=100 28 29 # Azkaban Executor settings 30 executor.maxThreads=50 31 executor.port=12321 32 executor.flow.threads=30
集群启动
先启动exec-server,再启动web-server。启动webServer之后进程失败消失,可通过安装包根目录下对应启动日志进行排查。

需要手动激活executor
cd /export/servers/azkaban/execserver
curl -G "node-2:$(<./executor.port)/executor?action=activate" && echo

然后重新启动webServer就可以了。
Oozie:
修改hadoop相关配置
配置httpfs服务
修改hadoop的配置文件 core-site.xml
1 <!--允许通过httpfs方式访问hdfs的主机名、域名;--> 2 <property> 3 <name>hadoop.proxyuser.root.hosts</name> 4 <value>*</value> 5 </property> 6 <!--允许访问的客户端的用户组--> 7 <property> 8 <name>hadoop.proxyuser.root.groups</name> 9 <value>*</value> 10 </property>
配置jobhistory服务
修改hadoop的配置文件mapred-site.xml
1 <property> 2 <name>mapreduce.jobhistory.address</name> 3 <value>node-1:10020</value> 4 <description>MapReduce JobHistory Server IPC host:port</description> 5 </property> 6 7 <property> 8 <name>mapreduce.jobhistory.webapp.address</name> 9 <value>node-1:19888</value> 10 <description>MapReduce JobHistory Server Web UI host:port</description> 11 </property> 12 <!-- 配置运行过的日志存放在hdfs上的存放路径 --> 13 <property> 14 <name>mapreduce.jobhistory.done-dir</name> 15 <value>/export/data/history/done</value> 16 </property> 17 18 <!-- 配置正在运行中的日志在hdfs上的存放路径 --> 19 <property> 20 <name>mapreduce.jobhistory.intermediate-done-dir</name> 21 <value>/export/data/history/done_intermediate</value> 22 </property>
重启history-server服务、重启Hadoop集群服务。
上传oozie的安装包并解压
oozie的安装包上传到/export/softwares
tar -zxvf oozie-4.1.0-cdh5.14.0.tar.gz
解压hadooplibs到与oozie平行的目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
tar -zxvf oozie-hadooplibs-4.1.0-cdh5.14.0.tar.gz -C ../
添加相关依赖
oozie的安装路径下创建libext目录
cd /export/servers/oozie-4.1.0-cdh5.14.0
mkdir -p libext
拷贝hadoop依赖包到libext
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra hadooplibs/hadooplib-2.6.0-cdh5.14.0.oozie-4.1.0-cdh5.14.0/* libext/
上传mysql的驱动包到libext
mysql-connector-java-5.1.32.jar
添加ext-2.2.zip压缩包到libext
ext-2.2.zip
修改oozie-site.xml
cd /export/servers/oozie-4.1.0-cdh5.14.0/conf
vim oozie-site.xml
oozie默认使用的是UTC的时区,需要在oozie-site.xml当中配置时区为GMT+0800时区
1 <property> 2 <name>oozie.service.JPAService.jdbc.driver</name> 3 <value>com.mysql.jdbc.Driver</value> 4 </property> 5 <property> 6 <name>oozie.service.JPAService.jdbc.url</name> 7 <value>jdbc:mysql://node-1:3306/oozie</value> 8 </property> 9 <property> 10 <name>oozie.service.JPAService.jdbc.username</name> 11 <value>root</value> 12 </property> 13 <property> 14 <name>oozie.service.JPAService.jdbc.password</name> 15 <value>hadoop</value> 16 </property> 17 <property> 18 <name>oozie.processing.timezone</name> 19 <value>GMT+0800</value> 20 </property> 21 22 <property> 23 <name>oozie.service.coord.check.maximum.frequency</name> 24 <value>false</value> 25 </property> 26 27 <property> 28 <name>oozie.service.HadoopAccessorService.hadoop.configurations</name> 29 <value>*=/export/servers/hadoop-2.7.5/etc/hadoop</value> 30 </property>
初始化mysql相关信息
上传oozie的解压后目录的下的yarn.tar.gz到hdfs目录
bin/oozie-setup.sh sharelib create -fs hdfs://node-1:9000 -locallib oozie-sharelib-4.1.0-cdh5.14.0-yarn.tar.gz
本质上就是将这些jar包解压到了hdfs上面的路径下面去
创建mysql数据库
mysql -uroot -p
create database oozie;
初始化创建oozie的数据库表
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie-setup.sh db create -run -sqlfile oozie.sql
打包项目,生成war包
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie-setup.sh prepare-war
配置oozie环境变量
1 vim /etc/profile 2 export OOZIE_HOME=/export/servers/oozie-4.1.0-cdh5.14.0 3 export OOZIE_URL=http://node03.hadoop.com:11000/oozie 4 export PATH=$PATH:$OOZIE_HOME/bin 5 source /etc/profile
启动关闭oozie服务
启动命令
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozied.sh start
关闭命令
bin/oozied.sh stop
如果意外关闭或者关机没关闭,那么重启之后再次启动会报错,需先删除上次启动时产生的pid文件,并且kill刚刚启动失败的进程,再次启动即可

浏览器web UI页面
http://node-1:11000/oozie/
Azkaban与Oozie实战
Azkaban使用实战
shell command调度
创建job描述文件
vim command.job
#command.job type=command command=echo 'hello'
将job资源文件打包成zip文件
zip command.job
通过azkaban的web管理平台创建project并上传job压缩包
首先创建Project

上传zip包
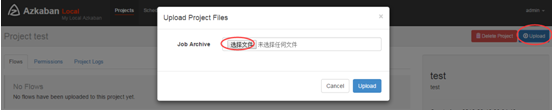
启动执行该job

job依赖调度
创建有依赖关系的多个job描述
第一个job:foo.job
1 # foo.job 2 type=command 3 command=echo foo
第二个job:bar.job依赖foo.job
1 # bar.job 2 type=command 3 dependencies=foo 4 command=echo bar
将所有job资源文件打到一个zip包中
在azkaban的web管理界面创建工程并上传zip包
启动工作流flow
HDFS任务调度
1 # fs.job 2 type=command 3 command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz
除了job文件内容不一样,其他步骤都是一致的
MAPREDUCE任务调度
1 # mrwc.job 2 type=command 3 command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout
除了job文件内容不一样,其他步骤都是一致的
HIVE脚本任务调度
1 # hivef.job 2 type=command 3 command=/home/hadoop/apps/hive/bin/hive -f 'test.sql'
除了job文件内容不一样,其他步骤都是一致的,这里既可以执行SQL文件也可以执行SQL语句,语法见hive篇
定时任务调度

上述图片中,选择左边schedule表示配置定时调度信息,选择右边execute表示立即执行工作流任务。

Oozie使用实战:
yarn容器资源分配属性
yarn-site.xml:
1 <!—节点最大可用内存,结合实际物理内存调整 --> 2 <property> 3 <name>yarn.nodemanager.resource.memory-mb</name> 4 <value>3072</value> 5 </property> 6 <!—每个容器可以申请内存资源的最小值,最大值 --> 7 <property> 8 <name>yarn.scheduler.minimum-allocation-mb</name> 9 <value>1024</value> 10 </property> 11 <property> 12 <name>yarn.scheduler.maximum-allocation-mb</name> 13 <value>3072</value> 14 </property> 15 16 <!—修改为Fair公平调度,动态调整资源,避免yarn上任务等待(多线程执行) --> 17 <property> 18 <name>yarn.resourcemanager.scheduler.class</name> 19 <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> 20 </property> 21 <!—Fair调度时候是否开启抢占功能 --> 22 <property> 23 <name>yarn.scheduler.fair.preemption</name> 24 <value>true</value> 25 </property> 26 <!—超过多少开始抢占,默认0.8--> 27 <property> 28 <name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name> 29 <value>1.0</value> 30 </property>
mapreduce资源申请配置
设置mapreduce.map.memory.mb和mapreduce.reduce.memory.mb配置
否则Oozie读取的默认配置 -1, 提交给yarn的时候会抛异常Invalid resource request, requested memory < 0, or requested memory > max configured, requestedMemory=-1, maxMemory=8192
mapred-site.xml
1 <!—单个maptask、reducetask可申请内存大小 --> 2 <property> 3 <name>mapreduce.map.memory.mb</name> 4 <value>1024</value> 5 </property> 6 <property> 7 <name>mapreduce.reduce.memory.mb</name> 8 <value>1024</value> 9 </property>
更新hadoop配置重启集群
重启hadoop集群
重启oozie服务
Oozie调度shell脚本
准备配置模板
#把shell的任务模板拷贝到oozie的工作目录当中去 cd /export/servers/oozie-4.1.0-cdh5.14.0 cp -r examples/apps/shell/ oozie_works/ #准备待调度的shell脚本文件 cd /export/servers/oozie-4.1.0-cdh5.14.0 vim oozie_works/shell/hello.sh #注意:这个脚本一定要是在我们oozie工作路径下的shell路径下的位置 #!/bin/bash echo "hello world" >> /export/servers/hello_oozie.txt
修改配置模板
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/shell
vim job.properties
1 nameNode=hdfs://node-1:8020 #HadoopNameNode地址 2 jobTracker=node-1:8032 #Hadoop ResourceManager地址 3 queueName=default 4 examplesRoot=oozie_works 5 oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell #地址一定要跟你上传到HDFS上的路径保持一致 6 EXEC=hello.sh
jobTracker:在hadoop2当中,jobTracker这种角色已经没有了,只有resourceManager,这里给定resourceManager的IP及端口即可。
queueName:提交mr任务的队列名;
examplesRoot:指定oozie的工作目录;
oozie.wf.application.path:指定oozie调度资源存储于hdfs的工作路径;
EXEC:指定执行任务的名称。
修改workflow.xml
1 <workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf"> 2 <start to="shell-node"/> 3 <action name="shell-node"> 4 <shell xmlns="uri:oozie:shell-action:0.2"> 5 <job-tracker>${jobTracker}</job-tracker> 6 <name-node>${nameNode}</name-node> 7 <configuration> 8 <property> 9 <name>mapred.job.queue.name</name> 10 <value>${queueName}</value> 11 </property> 12 </configuration> 13 <exec>${EXEC}</exec> 14 <file>/user/root/oozie_works/shell/${EXEC}#${EXEC}</file> 15 <capture-output/> 16 </shell> 17 <ok to="end"/> 18 <error to="fail"/> 19 </action> 20 <decision name="check-output"> 21 <switch> 22 <case to="end"> 23 ${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'} 24 </case> 25 <default to="fail-output"/> 26 </switch> 27 </decision> 28 <kill name="fail"> 29 <message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> 30 </kill> 31 <kill name="fail-output"> 32 <message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message> 33 </kill> 34 <end name="end"/> 35 </workflow-app>
上传调度任务到hdfs
注意:上传的hdfs目录为/user/root,因为hadoop启动的时候使用的是root用户,如果hadoop启动的是其他用户,那么就上传到/user/其他用户
cd /export/servers/oozie-4.1.0-cdh5.14.0
hdfs dfs -put oozie_works/ /user/root
执行调度任务
通过oozie的命令来执行调度任务
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://node-1:11000/oozie -config oozie_works/shell/job.properties -run
从监控界面可以看到任务执行成功了。
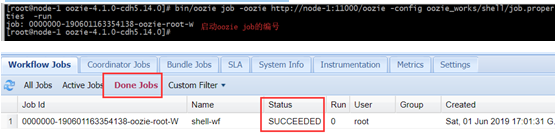
可以通过jobhistory来确定调度时候是由那台机器执行的。
Oozie调度Hive
准备配置模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra examples/apps/hive2/ oozie_works/
修改配置模板
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/hive2
vim job.properties
1 nameNode=hdfs://node-1:8020 2 jobTracker=node-1:8032 3 queueName=default 4 jdbcURL=jdbc:hive2://node-1:10000/default 5 examplesRoot=oozie_works 6 7 oozie.use.system.libpath=true 8 # 配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/hive2这个路径下 9 oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/hive2
workflow.xml无变化,之后的步骤都是一样的,执行之后可以在监控页面进行查看,但是执行之前确保hiveserver2的服务一定要启动。
Oozie调度MapReduce
准备配置模板
准备mr程序的待处理数据。用hadoop自带的MR程序来运行wordcount。
准备数据上传到HDFS的/oozie/input路径下去
hdfs dfs -mkdir -p /oozie/input
hdfs dfs -put wordcount.txt /oozie/input
拷贝MR的任务模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra examples/apps/map-reduce/ oozie_works/
删掉MR任务模板lib目录下自带的jar包
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib
rm -rf oozie-examples-4.1.0-cdh5.14.0.jar
拷贝官方自带mr程序jar包到对应目录
cp /export/servers/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib/
修改配置模板
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce
vim job.properties
1 nameNode=hdfs://node-1:8020 2 jobTracker=node-1:8032 3 queueName=default 4 examplesRoot=oozie_works 5 6 oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/map-reduce/workflow.xml 7 outputDir=/oozie/output 8 inputdir=/oozie/input
修改workflow.xml
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce
vim workflow.xml


1 <?xml version="1.0" encoding="UTF-8"?> 2 <workflow-app xmlns="uri:oozie:workflow:0.5" name="map-reduce-wf"> 3 <start to="mr-node"/> 4 <action name="mr-node"> 5 <map-reduce> 6 <job-tracker>${jobTracker}</job-tracker> 7 <name-node>${nameNode}</name-node> 8 <prepare> 9 <delete path="${nameNode}/${outputDir}"/> 10 </prepare> 11 <configuration> 12 <property> 13 <name>mapred.job.queue.name</name> 14 <value>${queueName}</value> 15 </property> 16 <!-- 开启使用新的API来进行配置 --> 17 <property> 18 <name>mapred.mapper.new-api</name> 19 <value>true</value> 20 </property> 21 22 <property> 23 <name>mapred.reducer.new-api</name> 24 <value>true</value> 25 </property> 26 27 <!-- 指定MR的输出key的类型 --> 28 <property> 29 <name>mapreduce.job.output.key.class</name> 30 <value>org.apache.hadoop.io.Text</value> 31 </property> 32 33 <!-- 指定MR的输出的value的类型--> 34 <property> 35 <name>mapreduce.job.output.value.class</name> 36 <value>org.apache.hadoop.io.IntWritable</value> 37 </property> 38 39 <!-- 指定输入路径 --> 40 <property> 41 <name>mapred.input.dir</name> 42 <value>${nameNode}/${inputdir}</value> 43 </property> 44 45 <!-- 指定输出路径 --> 46 <property> 47 <name>mapred.output.dir</name> 48 <value>${nameNode}/${outputDir}</value> 49 </property> 50 51 <!-- 指定执行的map类 --> 52 <property> 53 <name>mapreduce.job.map.class</name> 54 <value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value> 55 </property> 56 57 <!-- 指定执行的reduce类 --> 58 <property> 59 <name>mapreduce.job.reduce.class</name> 60 <value>org.apache.hadoop.examples.WordCount$IntSumReducer</value> 61 </property> 62 <!-- 配置map task的个数 --> 63 <property> 64 <name>mapred.map.tasks</name> 65 <value>1</value> 66 </property> 67 68 </configuration> 69 </map-reduce> 70 <ok to="end"/> 71 <error to="fail"/> 72 </action> 73 <kill name="fail"> 74 <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> 75 </kill> 76 <end name="end"/> 77 </workflow-app>
这一步最为复杂与繁琐,一定要细心,要彻底理解MR 程序的运行步骤,设置好每个步骤的Key和value的类型与对应类的类名。
后续步骤没有什么变化,运行MR程序调度最重要也是最容易出错就是workflow.xml配置的错误。报错仔细检查
Oozie任务串联
在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个action,实现多个任务之间的相互依赖关系。
需求:首先执行一个shell脚本,执行完了之后再执行一个MR的程序,最后再执行一个hive的程序。
准备工作目录
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
mkdir -p sereval-actions
准备调度文件
将之前的hive,shell, MR的执行,进行串联成到一个workflow当中。
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp hive2/script.q sereval-actions/
cp shell/hello.sh sereval-actions/
cp -ra map-reduce/lib sereval-actions/
修改配置模板
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
vim workflow.xml
1 <workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf"> 2 <start to="shell-node"/> 3 <action name="shell-node"> 4 <shell xmlns="uri:oozie:shell-action:0.2"> 5 <job-tracker>${jobTracker}</job-tracker> 6 <name-node>${nameNode}</name-node> 7 <configuration> 8 <property> 9 <name>mapred.job.queue.name</name> 10 <value>${queueName}</value> 11 </property> 12 </configuration> 13 <exec>${EXEC}</exec> 14 <!-- <argument>my_output=Hello Oozie</argument> --> 15 <file>/user/root/oozie_works/sereval-actions/${EXEC}#${EXEC}</file> 16 17 <capture-output/> 18 </shell> 19 <ok to="mr-node"/> 20 <error to="mr-node"/> 21 </action> 22 23 <action name="mr-node"> 24 <map-reduce> 25 <job-tracker>${jobTracker}</job-tracker> 26 <name-node>${nameNode}</name-node> 27 <prepare> 28 <delete path="${nameNode}/${outputDir}"/> 29 </prepare> 30 <configuration> 31 <property> 32 <name>mapred.job.queue.name</name> 33 <value>${queueName}</value> 34 </property> 35 <!-- 36 <property> 37 <name>mapred.mapper.class</name> 38 <value>org.apache.oozie.example.SampleMapper</value> 39 </property> 40 <property> 41 <name>mapred.reducer.class</name> 42 <value>org.apache.oozie.example.SampleReducer</value> 43 </property> 44 <property> 45 <name>mapred.map.tasks</name> 46 <value>1</value> 47 </property> 48 <property> 49 <name>mapred.input.dir</name> 50 <value>/user/${wf:user()}/${examplesRoot}/input-data/text</value> 51 </property> 52 <property> 53 <name>mapred.output.dir</name> 54 <value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value> 55 </property> 56 --> 57 58 <!-- 开启使用新的API来进行配置 --> 59 <property> 60 <name>mapred.mapper.new-api</name> 61 <value>true</value> 62 </property> 63 64 <property> 65 <name>mapred.reducer.new-api</name> 66 <value>true</value> 67 </property> 68 69 <!-- 指定MR的输出key的类型 --> 70 <property> 71 <name>mapreduce.job.output.key.class</name> 72 <value>org.apache.hadoop.io.Text</value> 73 </property> 74 75 <!-- 指定MR的输出的value的类型--> 76 <property> 77 <name>mapreduce.job.output.value.class</name> 78 <value>org.apache.hadoop.io.IntWritable</value> 79 </property> 80 81 <!-- 指定输入路径 --> 82 <property> 83 <name>mapred.input.dir</name> 84 <value>${nameNode}/${inputdir}</value> 85 </property> 86 87 <!-- 指定输出路径 --> 88 <property> 89 <name>mapred.output.dir</name> 90 <value>${nameNode}/${outputDir}</value> 91 </property> 92 93 <!-- 指定执行的map类 --> 94 <property> 95 <name>mapreduce.job.map.class</name> 96 <value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value> 97 </property> 98 99 <!-- 指定执行的reduce类 --> 100 <property> 101 <name>mapreduce.job.reduce.class</name> 102 <value>org.apache.hadoop.examples.WordCount$IntSumReducer</value> 103 </property> 104 <!-- 配置map task的个数 --> 105 <property> 106 <name>mapred.map.tasks</name> 107 <value>1</value> 108 </property> 109 110 </configuration> 111 </map-reduce> 112 <ok to="hive2-node"/> 113 <error to="fail"/> 114 </action> 115 116 117 118 119 120 121 <action name="hive2-node"> 122 <hive2 xmlns="uri:oozie:hive2-action:0.1"> 123 <job-tracker>${jobTracker}</job-tracker> 124 <name-node>${nameNode}</name-node> 125 <prepare> 126 <delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/> 127 <mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/> 128 </prepare> 129 <configuration> 130 <property> 131 <name>mapred.job.queue.name</name> 132 <value>${queueName}</value> 133 </property> 134 </configuration> 135 <jdbc-url>${jdbcURL}</jdbc-url> 136 <script>script.q</script> 137 <param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param> 138 <param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param> 139 </hive2> 140 <ok to="end"/> 141 <error to="fail"/> 142 </action> 143 <decision name="check-output"> 144 <switch> 145 <case to="end"> 146 ${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'} 147 </case> 148 <default to="fail-output"/> 149 </switch> 150 </decision> 151 <kill name="fail"> 152 <message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> 153 </kill> 154 <kill name="fail-output"> 155 <message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message> 156 </kill> 157 <end name="end"/> 158 </workflow-app>
其实仔细观察就会发现,这里面的逻辑就是开始节点指定要执行的任务,然后执行完的动作中指定另一个任务,以此类推。
job.properties配置文件
nameNode=hdfs://node-1:8020
jobTracker=node-1:8032
queueName=default
examplesRoot=oozie_works
EXEC=hello.sh
outputDir=/oozie/output
inputdir=/oozie/input
jdbcURL=jdbc:hive2://node-1:10000/default
oozie.use.system.libpath=true
# 配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/sereval-actions这个路径下
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/sereval-actions/workflow.xml
剩余的步骤都是一样的。执行完到监控系统上查看执行情况。
Oozie定时调度
在oozie当中,主要是通过Coordinator 来实现任务的定时调度, Coordinator 模块主要通过xml来进行配置即可。
Coordinator 的调度主要可以有两种实现方式
第一种:基于时间的定时任务调度:
oozie基于时间的调度主要需要指定三个参数,第一个起始时间,第二个结束时间,第三个调度频率;
第二种:基于数据的任务调度, 这种是基于数据的调度,只要在有了数据才会触发调度任务。
准备配置模板
第一步:拷贝定时任务的调度模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -r examples/apps/cron oozie_works/cron-job
第二步:拷贝我们的hello.sh脚本
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp shell/hello.sh cron-job/
修改配置模板
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/cron-job
vim job.properties
1 nameNode=hdfs://node-1:8020 2 jobTracker=node-1:8032 3 queueName=default 4 examplesRoot=oozie_works 5 6 oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/cron-job/coordinator.xml 7 #start:必须设置为未来时间,否则任务失败 8 start=2019-05-22T19:20+0800 9 end=2019-08-22T19:20+0800 10 EXEC=hello.sh 11 workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/cron-job/workflow.xml
修改coordinator.xml
vim coordinator.xml
1 <!-- 2 oozie的frequency 可以支持很多表达式,其中可以通过定时每分,或者每小时,或者每天,或者每月进行执行,也支持可以通过与linux的crontab表达式类似的写法来进行定时任务的执行 3 例如frequency 也可以写成以下方式 4 frequency="10 9 * * *" 每天上午的09:10:00开始执行任务 5 frequency="0 1 * * *" 每天凌晨的01:00开始执行任务 6 --> 7 <coordinator-app name="cron-job" frequency="${coord:minutes(1)}" start="${start}" end="${end}" timezone="GMT+0800" 8 xmlns="uri:oozie:coordinator:0.4"> 9 <action> 10 <workflow> 11 <app-path>${workflowAppUri}</app-path> 12 <configuration> 13 <property> 14 <name>jobTracker</name> 15 <value>${jobTracker}</value> 16 </property> 17 <property> 18 <name>nameNode</name> 19 <value>${nameNode}</value> 20 </property> 21 <property> 22 <name>queueName</name> 23 <value>${queueName}</value> 24 </property> 25 </configuration> 26 </workflow> 27 </action> 28 </coordinator-app>
workflow.xml跟之前的一样,剩余步骤相同,上传到HDFS上执行,在监控系统查看
两个工作流调度的系统,就大致这些内容了,更深层次的使用,可以参考官网文档。