转自:https://zhuanlan.zhihu.com/p/26499443
生成对抗网络GAN是由蒙特利尔大学Ian Goodfellow教授和他的学生在2014年提出的机器学习架构。
要全面理解生成对抗网络,首先要理解的概念是监督式学习和非监督式学习。监督式学习是指基于大量带有标签的训练集与测试集的机器学习过程,比如监督式图片分类器需要一系列图片和对应的标签(“猫”,“狗”…),而非监督式学习则不需要这么多额外的工作,它们可以自己从错误中进行学习,并降低未来出错的概率。监督式学习的缺点就是需要大量标签样本,这非常耗时耗力。非监督式学习虽然没有这个问题,但准确率往往更低。自然而然地希望能够通过提升非监督式学习的性能,从而减少对监督式学习的依赖。GAN可以说是对于非监督式学习的一种提升。
第二个需要理解的概念是“生成模型”, 如下图所示生成图片模型的概念示意图。这类模型能够通过输入的样本产生可能的输出。举个例子,一个生成模型可以通过视频的某一帧预测出下一帧的输出。另一个例子是搜索引擎,在你输入的同时,搜索引擎已经在推断你可能搜索的内容了。

基于上面这两个概念就可以设计生成对抗网络GAN了。相比于传统的神经网络模型,GAN是一种全新的非监督式的架构(如下图所示)。GAN包括了两套独立的网络,两者之间作为互相对抗的目标。第一套网络是我们需要训练的分类器(下图中的D),用来分辨是否是真实数据还是虚假数据;第二套网络是生成器(下图中的G),生成类似于真实样本的随机样本,并将其作为假样本。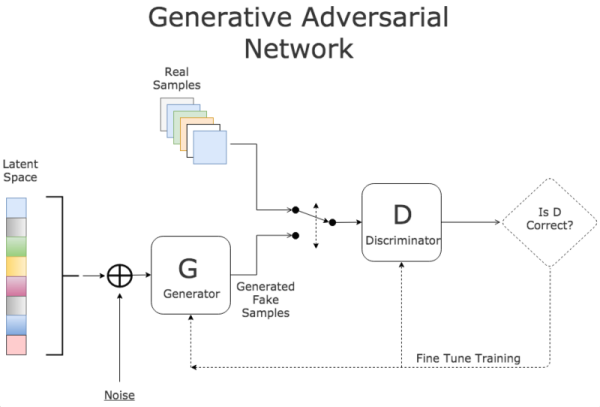
详细说明:
D作为一个图片分类器,对于一系列图片区分不同的动物。生成器G的目标是绘制出非常接近的伪造图片来欺骗D,做法是选取训练数据潜在空间中的元素进行组合,并加入随机噪音,例如在这里可以选取一个猫的图片,然后给猫加上第三只眼睛,以此作为假数据。
在训练过程中,D会接收真数据和G产生的假数据,它的任务是判断图片是属于真数据的还是假数据的。对于最后输出的结果,可以同时对两方的参数进行调优。如果D判断正确,那就需要调整G的参数从而使得生成的假数据更为逼真;如果D判断错误,则需调节D的参数,避免下次类似判断出错。训练会一直持续到两者进入到一个均衡和谐的状态。
训练后的产物是一个质量较高的自动生成器和一个判断能力较强强的分类器。前者可以用于机器创作(自动画出“猫”“狗”),而后者则可以用来机器分类(自动判断“猫”“狗”)。
最后这里给出一个生成对抗网络的列表。
参考资料
[1] https://www.linkedin.com/pulse/gans-one-hottest-topics-machine-learning-al-gharakhanian