1 Linux命令
1.1 文件
cd path 路径名
cd .. 返回上一层
cd ~ 进入到当前Linux系统登录用户的主目录(或主文件夹)。在 Linux 系统中,~代表的是用户的主文件夹,即“/home/用户名”这个目录,如果当前登录用户名为 hadoop,则~就代表“/home/hadoop/”这个目录
ls #查看当前目录中的文件
ls -l #查看文件和目录的权限信息
mkdir input #在当前目录下创建input子目录
mkdir -p src/main/scala # 在当前目录下,创建多级子目录src/main/scala
cat /home/hadoop/word.txt `#把/home/hadoop/word.txt这个文件全部内容显示到屏幕上
cat file1 file2 > file3 #把当前目录下的file1和file2两个文件进行合并生成文件file3
head -5 word.txt #把当前目录下的word.txt文件中的前5行内容显示到屏幕上,可以显示前n行,自定义
cp /home/hadoop/word.txt /usr/local/ #把/home/hadoop/word.txt文件复制到“/usr/local”目录下,前面是文件后面三文件夹,后面三文件则进行重命名
rm ./word.txt #删除当前目录下的word.txt文件
rm –r ./test #删除当前目录下的test目录及其下面的所有文件
rm –r test* #删除当面目录下所有以test开头的目录和文件
tar -zxf ~/下载/spark-2.1.0.tgz -C /usr/local/ #把spark-2.1.0.tgz这个压缩文件解压到/usr/local目录下。* x : 从 tar 包中把文件提取出来;* z : 表示 tar 包是被 gzip 压缩过的,所以解压时需要用gunzip解压;* f : 表示后面跟着的是文件;* C:表示文件解压后转到指定的目录下。
mv spark-2.1.0 spark #把spark-2.1.0目录重新命名为spark
chown -R hadoop:hadoop ./spark # hadoop是当前登录Linux系统的用户名,把当前目录下的spark子目录的所有权限,赋予给用户hadoop
ifconfig #查看本机IP地址信息
exit #退出并关闭Linux终端
1.2 vim命令
vim afile 编辑afile文件,如果没有则是新文件
按字母i或者insert键开始插入内容
插入完毕后按Esc键退出编辑
输入:wq保存并退出,输入:q退出不保存,后面加叹号!表示强制执行
这里需要指出的是,在Linux系统中使用vim编辑器创建一个文件时,并不是以扩展名来区分文件的,不管是否有扩展名,都是生成文本文件,.txt扩展名只是我们自己人为添加,方便自己查看用的。也就是说,创建word.txt和word这两个文件,对于Linux系统而言都是默认创建了文本类型的文件,和是否有.txt扩展名没有关系。
1.3账户
安装gnome界面 yum groupinstall "GNOME Desktop"
设置默认启动 systemctl set-default multi-user.target //设置成命令模式 systemctl set-default graphical.target //设置成图形模式
useradd -m hadoop -s /bin/bash # 创建新用户hadoop并使用 /bin/bash 作为shell。
passwd hadoop #修改密码
visudo#打开文件添加管理员权限 hadoop ALL=(ALL) ALL
切换用户 login hadoop
切换root :sudo su
ssh无密码登陆
exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost ssh-keygen -t rsa # 会有提示,都按回车就可以 cat id_rsa.pub >> authorized_keys # 加入授权 chmod 600 ./authorized_keys # 修改文件权限
添加环境变量
vim ~/.bashrc #添加内容 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjd
source ~/.bashrc # 使变量设置生效
添加path变量vim ~/.bashrc
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
设置主机名
sudo vim /etc/hostname
然后执行如下命令修改自己所用节点的IP映射:先ip再tab再输入主机名,重启电脑生效
sudo vim /etc/hosts
ping命令,检测是否在同一个局域网内
ping Master -c 3 # 只ping 3次,否则要按 Ctrl+c 中断 ping Slave1 -c 3
1.4 SSH无密码登陆
例如Master要无密码ssh登陆Slave1,先在Master上
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost rm ./id_rsa* # 删除之前生成的公匙(如果有) ssh-keygen -t rsa # 一直按回车就可以
cat ./id_rsa.pub >> ./authorized_keys
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 Slave1 节点,注意目标机器+冒号+目标路径
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
scp ~/file1/file4.txt 192.168.0.4:~
scp 是 secure copy 的简写,用于在 Linux 下进行远程拷贝文件,类似于 cp 命令,不过 cp 只能在本机中拷贝。执行 scp 时会要求输入 Slave1 上 hadoop 用户的密码(hadoop),输入完成后会提示传输完毕。账户名@主机名加冒号: 加路径
在slave1节点上
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub # 用完就可以删掉了
2 Hadoop命令
格式化
hdfs namenode -format
启动:
在Master节点上
start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver
或
不推荐的用法
start-all.sh
查看进程
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程
缺少任一进程都表示出错。
查看DataNode
hdfs dfsadmin -report
另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
实际上有三种shell命令方式。
1. hadoop fs :适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
2. hadoop dfs:只能适用于HDFS文件系统
3. hdfs dfs:也只能适用于HDFS文件系统
命令以上述三个开头如 hadoop fs - 跟命令。最常见的命令。
hadoop fs -ls 列出文件信息
hadoop fs -cat path指定的文件内容输出
hdfs dfs -mkdir hado 创建文件
hadoop fs -ls input2
hadoop fs -put ~/file1/file*.txt input2
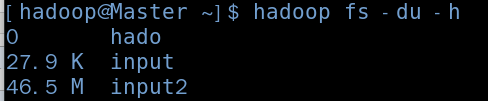
hadoop fs -du -h#显示文件系统的文件和大小
执行jar包
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.1.jar wordcount input2 output3