今天复习的时候,看到了缓冲流,知道了缓冲流是内置了一个数组,增加了效率
但是当我看到一个例子的时候我就迷惑了,诶,不是内置了数组吗,怎么还需要传递一个数组增加效率呢
有关的代码如下,无关代码就不列了
try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe")); ){ // 读写数据 int b; byte[] bytes = new byte[8*1024]; while ((b = bis.read(bytes)) != ‐1) { bos.write(bytes, 0 , len); } } catch (IOException e) { e.printStackTrace(); }
可以看到在用了Buffered缓冲流的基础上,这个代码仍然添加了另一个数组,并且实测效率的确上升了
然后经过研究我终于知道是为啥了
----------------------------
首先声明一下缓冲流的基本原理:是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率
通过看源码,知道了这个默认的缓冲区数组大小是8192


然后我们来捋一捋定义:标红的部分,减少的是 系统IO次数 ,但是 缓冲区读写 这个部分,缓冲流做了优化吗,答案是没有
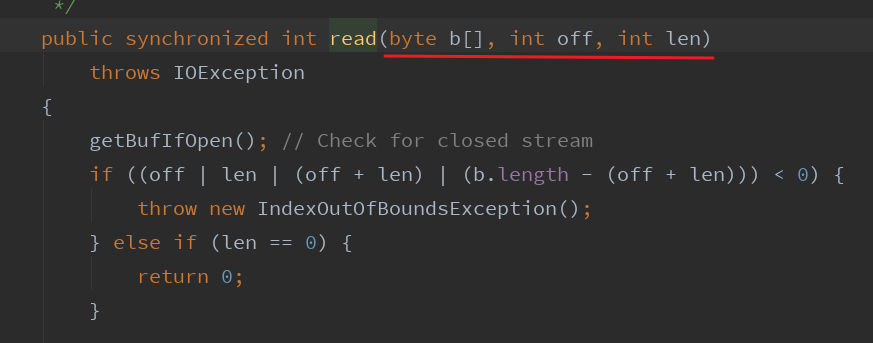
我们回到源码,字节缓冲输入流的add()无参方法如下,看返回值我们知道它返回的是int,诶,为什么不是返回数组呢,不是内置了数组吗?

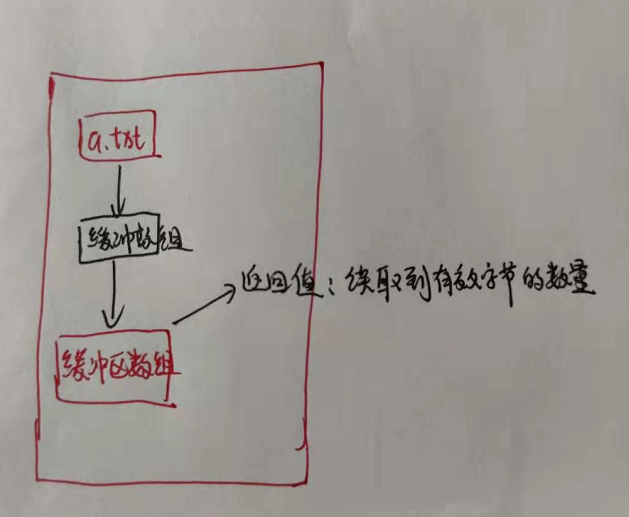
画一个示意图来说明吧,为什么说返回的是数组呢,因为返回给缓冲流的的确是数组,但是我们还有一个返回值就是我们每次读取的一个字节,源码的数据返回类型是int也证明了这一点,我们可以输出上面我提供的代码里面的b
就会知道的确每一次从被读取的文件中读数据是一个个字节读的,这样效率就很低下

因此就有了我提供的代码里面的那种写法,缓冲区数组不再一个个读取,而是一次读取一个字符数组,这样在缓冲区读写这个部分进行了再次优化,实际过程如下(部分)
并且源码里也提供了这种写法(源码完全解读有些难度,暂时没有时间去做)
这样的话每次返回值就是读取到的有效字节的数量,就可以按照代码里那样进行while()循环体里面的操作
while ((b = bis.read(bytes)) != ‐1) { bos.write(bytes, 0 , len); }
还有个问题:为什么我们加的这个数组就比内置的缓冲区数组更快读写呢,因为我们的数组是一连串的读下去,而缓冲区数组需要一个个读,一个个返回,消耗了更多资源,所以更慢
---------综上-------
缓冲流内置的缓冲区数组增加的效率的原因是在文件所在位置,也就是磁盘位置,到缓冲流这个部分的IO次数进行了优化,但是没有对读取磁盘文件这个步骤做优化,仍是单字节读取
我们可以使用数组读取的方式从磁盘读,进一步提升速度