1、训练误差和泛化误差
训练误差:训练集上表现出的误差
泛化误差:在任意测试样本上表现出的误差的期望
模型训练的目的就是降低泛化误差
2、模型选择及K折交叉验证
验证数据集:在实际训练模型的过程中,不能依据训练误差估计泛化误差,不能只依靠训练数据来选择模型,因此需要在原始数据集中预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。选择方式并不固定,为了保证数据集的随机性,可以采用随机选择的方式
K着交叉验证:训练数据集很少时,再在原始数据集中预留一部分作为验证数据集不适用。因此采用K折交叉验证,把原始训练数据集分割成K个不重合的子数据集,然后做K次模型训练和验证,每次,使用一个子数据集验证模型,剩下的K-1个模型训练模型。在K次训练和验证中,每次用来验证模型的子数据集都不同。最后对K次训练误差和验证误差求平均
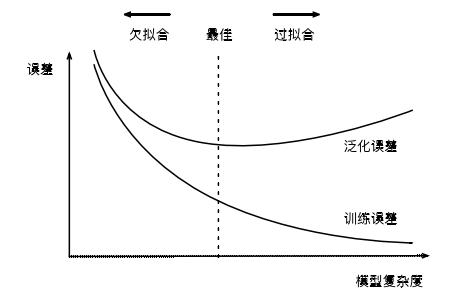
3、过拟合和欠拟合
过拟合:训练误差远小于在测试集上的误差
欠拟合:无法得到较低的训练误差
影响因素:重点是模型复杂度、训练数据集大小
4、权重衰减---解决模型过拟合
权重衰减等价于L2范数正则化(正则化通过为模型损失函数添加惩罚项使学到的模型参数值较小)
L2范数正则化:在模型损失函数上添加L2范数惩罚项
L2范数惩罚项:模型权重参数每个元素的平方和与一个正的常数的乘积
例如,线性回归中:
平方损失函数: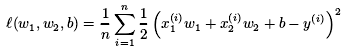
带L2范数惩罚项的新损失函数: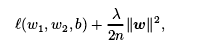 ,W=[W1,W2],
,W=[W1,W2],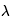 >0,||W||2=(W1)2+(W2)2
>0,||W||2=(W1)2+(W2)2
新损失函数中,权重迭代方式:

5、倒置丢弃法(drop)---解决模型过拟合
在一个含有单层隐藏层的多层感知机中,输入个数为4,隐藏层单元为5,每个隐藏单元的计算表达式为:
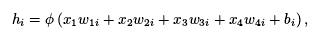
i=[1,2,3,4,5],ϕ是激活函数,x1, . . . , x4是输入,隐藏单元i的权重参数为w1i, . . . , w4i,偏差为bi
当对该隐藏层使用丢弃法时,这一层的每个隐藏单元都有一定概率被丢弃,且每个单元的被丢弃的概率一样(丢弃哪几个是随机的)。设丢弃概率为p,则有p的概率hi会被清零,有1-p的概率hi会除以1-p做拉伸(原因:保证丢弃法不会改变每个输入单元的期望值)
ξi为0和1的概率分别为p和1 − p,为0表示被丢弃
采用丢弃法之后,新的隐藏单元计算如下:
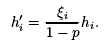

使用丢弃法之后的多层感知机(一种可能的结果)
