最近在工作中需要对EXCEL表进行操作,故而对xlrd和xlwt模块进行了一番学习,功能很强大,我就常用的一些基本功能做点总结吧。
模块的安装:
xlrd和xlwt模块不是自带模块。需要进行安装,安装方法不多说,有很多种通常用下面的这种方法安装简单方便。
pip install xlrd
pip install xlwt
导入模块:import xlrd,xlwt
xlrd模块的使用
获取表格名称的方法:
(1) 打开excel文件并获取所有sheet(表格)
>>> import xlrd >>> workbook = xlrd.open_workbook(r'D:路径文件名.xlsx') >>> print workbook.sheet_names() [u'Sheet1', u'Sheet2', u'Sheet3']
(2) 根据下标获取sheet名称
>>> sheet2_name=workbook.sheet_names()[1] >>> print sheet2_name Sheet2
(3) 根据sheet索引或者名称获取sheet内容
#根据名字获取sheet内容 >>> sheet_name = work_book.sheet_by_name('Sheet1') #如果知道表格名可以这样写,注意这里需要区分大小写。 <xlrd.sheet.Sheet object at 0x0393B5B0> #得到的是对象的地址。
#根据索引获取sheet内容 >>> sheet_name = work_book.sheet_by_index(0) <xlrd.sheet.Sheet object at 0x0346B5D0> #得到的是对象的地址。
#获取表格信息(名字,行数,列数) >>> print(sheet_name.name, sheet_name.nrows, sheet_name.ncols) Sheet1 9 4 #表名为Sheet1 行数9 列数4
(4) 根据sheet名称(索引)获取整行和整列的值
>>> sheet_name = work_book.sheet_by_name('Sheet1') #按名称获取值 >>> sheet_name = work_book.sheet_by_index(0) #按索引获取值 >>>print(sheet_name.row_values(2)) ['第2行1列', '第2行2列', '第2行3列', '第2行4列'] >>>print(sheet_name.col_values(3)) ['第四列', '第1行4列', '第2行4列', '第3行4列', '第4行4列', '第5行4列', '第6行4列', '第7行4列', '第8行4列']
(5)获取指定单元格的内容(三种方法)
>>> print(sheet_name.cell(1, 2).value) 第1行3列 >>> print(sheet_name.cell_value(1, 2)) 第1行3列 >>> print(sheet_name.row(1)[2].value) #row和col方法一样,是以行或列为基准,通过下标获取单元格内容 第1行3列 >>> print(sheet_name.col(2)[1].value) 第1行3列
(6)获取单元格内容的数据类型
>>> print(sheet_name.cell(1, 0).ctype) 1 #注意:ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error #ctype类型数值表示:0为空格,1为字符型,2为数值型,3为日期型,4为布尔型,5为错误
(7)获取单元内容为日期类型的方式
使用xlrd的xldateastuple处理为date格式,先判断表格的ctype=3时xlrd才能执行操作,如下:
from datetime import date >>> print(sheet_name.cell(0, 0).ctype) 3 #先判断是否为日期型 >>> print(sheet_name.cell(0, 0).value) 43271.0 #获得单元格中日期的值 >>> print(xlrd.xldate_as_tuple(sheet_name.cell(0, 0).value, work_book.datemode)) (2018, 6, 20, 0, 0, 0) #获得元祖形式的日期值 >>> data_time_value = xlrd.xldate_as_tuple(sheet_name.cell(0, 0).value, work_book.datemode) >>> print(date(*data_time_value[:3])) 2018-06-20 #通过date获得日期值 ('*'星号是剥掉元祖或列表括号) >>> print(date(*data_time_value[:3]).strftime('%Y/%m/%d')) 2018/06/20 #再通过strftime格式化输出
那么如果是在脚本中需要获取并显示单元格内容为日期类型的,可以先做一个判断。判断ctype是否等于3,如果等于3,则用时间格式处理:
if (sheet_name.cell(row, col).ctype == 3): data_time_value = xlrd.xldate_as_tuple(sheet_name.cell_value(row, col), book.datemode) date_time = date(*data_time_value[:3]).strftime('%Y/%m/%d')
(8) 获取合并单元格的内容
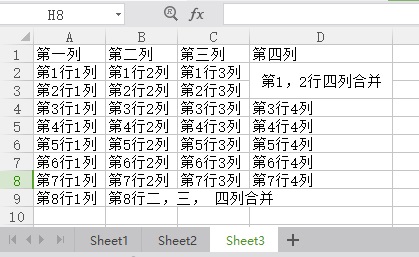
>>> print(sheet_name.cell(1, 3).value) #第四列的1行和2行合并单元格 第1,2行四列合并 >>> print(sheet_name.cell(2, 3).value) #同样是第四列,读取第2行值时显示为空 '' >>> print(sheet_name.cell(8, 1).value) #第8行,二、三、四列合并 第8行二,三, 四列合并 >>> print(sheet_name.cell(8, 2).value) '' >>> print(sheet_name.cell(8, 3).value) #同样是第8行,读取三、四列值时显示为空 ''
那么我们可以看出,当单元格合并的时候,只能读取合并单元格第一个单元格的值时才有值,其他合并的单元格没有对应的值。
让我们以整行和整列读取的值来更直观的看一下。
>>> print(sheet_name.row_values(8)) ['第8行1列', '第8行二,三, 四列合并', '', ''] >>> print(sheet_name.col_values(3)) ['第四列', '第1,2行四列合并', '', '第3行4列', '第4行4列', '第5行4列', '第6行4列', '第7行4列', '']
如何准确的读取到合并单元格的内容呢?我们可以使用merged_cells方法,一次性将所有合并单元格全部读取出来。
>>> sheet_name = work_book.sheet_by_index(2) >>> print(sheet_name.merged_cells) [(8, 9, 1, 4), (1, 3, 3, 4)]
注意:mergedcells返回的这四个参数的含义是:(row,rowrange,col,colrange),其中(row,rowrange)为一对,(col,colrange)为一对。读取规则与列表的下标读取规则一致,"顾前不顾后"。也就是,包含row值,不包括rowrange的值,col同理一样,下标数都是从0开始。
>>> print(sheet_name.cell(8, 1).value) 第8行二,三, 四列合并 >>> print(sheet_name.cell(1, 3).value) 第1,2行四列合并
由于合并单元格的第一个单元格是有值的,所以,通过merged_cells得到的4个下标值,只取每对的第一个值便可以得到组合表格的值了。
那么可以通过提取每对下标的最小下标值,来对合并的表格单元取值。
>>>merge_lis =[] >>>for (row_l,row_h,col_l,col_h) in sheet_name.merged_cells: ... merge_lis.append([row_l,col_l]) >>>for i in merge_lis: ... print(sheet_name.cell(i[0], i[1]).value) 第8行二,三, 四列合并 第1,2行四列合并
未完待续。。。 xlwt