0. AI为什么需要知识图谱?
人工智能分为三个阶段,从机器智能到感知智能,再到认知智能。
机器智能更多强调这些机器的运算的能力,大规模的集群的处理能力,GPU的处理的能力。
在这个基础之上会有感知智能,感知智能就是语音识别、图像识别,从图片里面识别出一个猫,识别人脸,是感知智能。感知智能并非人类所特有,动物也会有这样的一些感知智能。
再往上一层的认知智能,是人类所特有的,是建立在思考的基础之上的,认知的建立是需要思考的能力,而思考是建立在知识的基础之上,必须有知识的基础、有一些常识,才能建立一些思考,形成一个推理机制。
AI需要从感知智能迈向认知智能,本质上知识是一个基础,然后基于知识的推理,刚好知识图谱其实是具备这样的一个属性。
1. 知识图谱发展历史与基本概念
知识图谱本质上是一种大型的语义网络,它旨在描述客观世界的概念实体事件以及及其之间的关系。以实体概念为节点,以关系为边,提供一种从关系的视角来看世界。
深度学习是这个阶段大数据、人工智能火爆的原因,虽然深度学习的表示学习能力能够获得事物的底层空间特征,但这些特征是通过一个黑夹子获得,并且是一个连续的向量,人类根本无法理解,人类只能理解语义的场景。而知识图谱正是为深度学习和语义空间提供了连接,弥补了其中的沟鸿。

1.1 语义网络(Semantic Network)
语义网络可以理解为,现存的词汇都是可以串联起来的。用相互连接的节点和边来表示知识。节点表示对象、概念,边表示节点之间的关系。
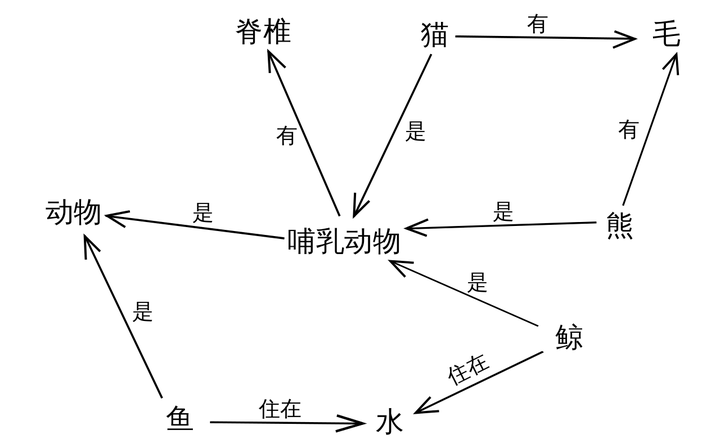
语义网络的优点:
-
容易理解和展示。
-
相关概念容易聚类。
语义网络的缺点:
-
节点和边的值没有标准,完全是由用户自己定义。
-
多源数据融合比较困难,因为没有标准。
-
无法区分概念节点和对象节点。
-
无法对节点和边的标签(label,我理解是schema层,后面会介绍)进行定义。
简而言之,语义网络可以比较容易地让我们理解语义和语义关系。其表达形式简单直白,符合自然。然而,由于缺少标准,其比较难应用于实践。看过上一篇文章的读者可能已经发现,RDF的提出解决了语义网络的缺点1和缺点2,在节点和边的取值上做了约束,制定了统一标准,为多源数据的融合提供了便利。
1.2 Ontology本体
Ontology:通常翻译为“本体”。本体本身是个哲学名词。在上个世纪80年代,人工智能研究人员将这一概念引入了计算机领域。Tom Gruber把本体定义为“概念和关系的形式化描述”【4】。通俗点讲,本体相似于数据库中的Schema,比如足球领域,主要用来定义类和关系,以及类层次和关系层次等。OWL是最常用的本体描述语言。本体通常被用来为知识图谱定义Schema。
1.3 The Semantic Web 语义网
语义互联网的核心内涵是:Web不仅仅要通过超链接把文本页面链接起来,还应该把事物链接起来,使得搜索引擎可以直接对事物进行搜索,而不仅仅是对网页进行搜索。谷歌知识图谱是语义互联网这一理念的商业化实现。也可以把语义互联网看做是一个基于互联网共同构建的全球知识库。
在万维网诞生之初,网络上的内容只是人类可读,而计算机无法理解和处理。比如,我们浏览一个网页,我们能够轻松理解网页上面的内容,而计算机只知道这是一个网页。网页里面有图片,有链接,但是计算机并不知道图片是关于什么的,也不清楚链接指向的页面和当前页面有何关系。语义网正是为了使得网络上的数据变得机器可读而提出的一个通用框架。“Semantic”就是用更丰富的方式来表达数据背后的含义,让机器能够理解数据。“Web”则是希望这些数据相互链接,组成一个庞大的信息网络,正如互联网中相互链接的网页,只不过基本单位变为粒度更小的数据,如下图。
1.4 链接数据Linked Data
Tim Berners Lee于2006年提出,是为了强调语义互联网的目的是要建立数据之间的链接,而非仅仅是把结构化的数据发布到网上。他为建立数据之间的链接制定了四个原则【2】。从理念上讲,链接数据最接近于知识图谱的概念。但很多商业知识图谱的具体实现并不一定完全遵循Tim所提出的那四个原则。
链接数据起初是用于定义如何利用语义网技术在网上发布数据,其强调在不同的数据集间创建链接。Tim Berners Lee提出了发布数据的四个原则,并根据数据集的开放程度将其划分为1到5星5个层次。链接数据也被当做是语义网技术一个更简洁,简单的描述。当它指语义网技术时,它更强调“Web”,弱化了“Semantic”的部分。对应到语义网技术栈,它倾向于使用RDF和SPARQL(RDF查询语言)技术,对于Schema层的技术,RDFS或者OWL,则很少使用。链接数据应该是最接近知识图谱的一个概念,从某种角度说,知识图谱是对链接数据这个概念的进一步包装。
语义网和链接数据是万维网之父Tim Berners Lee分别在1998年和2006提出的。相对于语义网络,语义网和链接数据倾向于描述万维网中资源、数据之间的关系。
1.5 RDF,RDFS与OWL
RDF(Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。
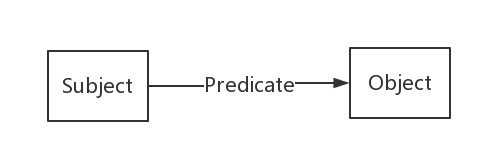
RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。
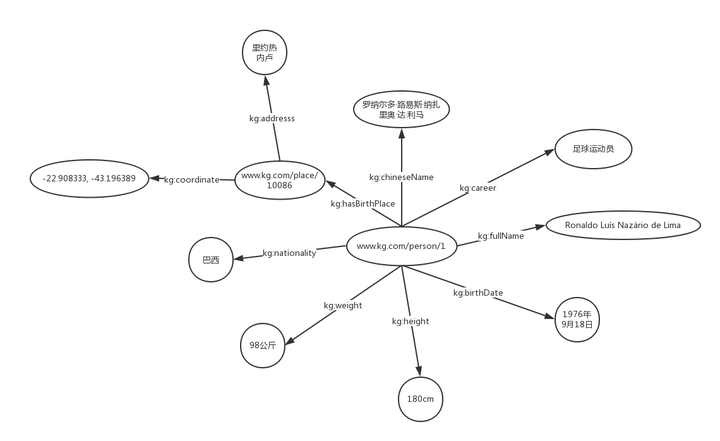
1.6 图数据库
https://zhuanlan.zhihu.com/p/42351039
2. 分类
2.1 Common Sense Knowledge Graph(常识知识图谱)
对于 Common Sense Knowledge Graph,一般而言我们比较在乎的 Relation 包括 isA Relation、isPropertyOf Relation。
2.2 百科全书式知识图谱(Encyclopedia Knowledge Graph
对于 Encyclopedia Knowledge Graph,通常我们会预定义一些谓词,比如说 DayOfbirth、LocatedIn、SpouseOf 等等。
对于 Common Sense Knowledge Graph 通常带有一定的概率,但是 Encyclopedia Knowledge Graph 通常就是“非黑即白”,那么构建这种知识图谱时,我们在乎的就是 Precision(准确率)。
Common Sense Knowledge Graph 比较有代表性的工作包括 WordNet、KnowItAll、NELL 以及 Microsoft Concept Graph。而 Encyclopedia Knowledge Graph 则有 Freepase、Yago、Google Knowledge Graph 以及正在构建中的“美团大脑”。
3. 开源知识图谱
当前世界范围内知名的高质量大规模开放知识图谱,包括
- DBpedia[85][86]、
- Yago[87][88]、
- Wikidata[89]、
- BabelNet[90][91]、
- ConceptNet[92][93]
- Microsoft Concept Graph[94][95]
另外还有中文开放知识图谱平台 OpenKG。
3.1 OpenKG
中文开放知识图谱联盟 OpenKG旨在推动中文知识图谱的开放与互联,推动知识图谱技术在中国的普及与应用,为中国人工智能的发展以及创新创业做出贡献。联盟已经搭建有OpenKG.CN技术平台(图5),目前已有35家机构入驻。吸引了国内最著名知识图谱资源的加入,如 Zhishi.me, CN-DBPedia,PKUBase。并已经包含了来自于常识、医疗、金融、城市、出行等 15 个类目的开放知识图谱。
4. 应用场景
知识图谱主要包含两层重要的信息:图数据结构+语义规则。


5.开发流程
其中实现层大概分成六个步骤,分别是知识获取、知识抽取、知识融合、知识存储、知识推理、知识建模和知识发现,
- 知识获取 是获取外部数据的方式,包括爬虫和实时入库的技术方法;
- 知识抽取 是对三元组进行知识的抽取,包括实体抽取、关系抽取和属性的抽取;
- 知识融合 就是在抽取出来之后,存在很多的数据冗余和噪声,要去做实体的消歧,数据的整合;
- 知识存储 实际是要构建一个三元组RDF的数据结构,如果把所有的顶点和边构造出来之后,要对他进行图数据库的存储;
- 知识推理 如果要做一些深层次的知识问答,就要做很多的训练,无论有监督的还是半监督的;
- 知识建模 更多的是去理解语义,涉及到属性的映射,实体的连接;
- 知识发现 两大主要的应用是知识的检索和知识的问答。这些构建了知识图谱的实现层。
6.产品设计思路

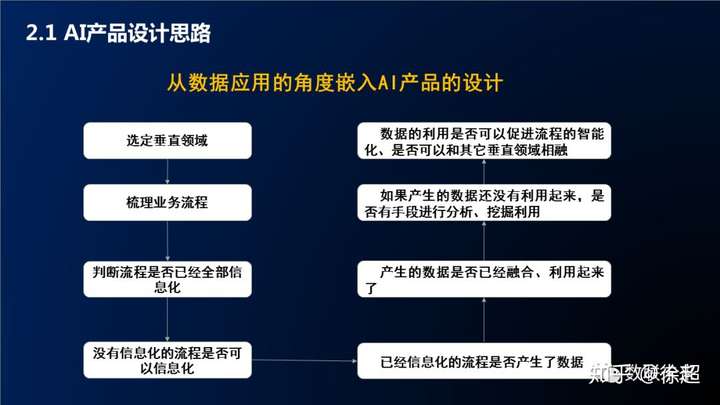

7.小结
知识图谱的构建思路都差不多,首先需要从应用场景出发,结合数据情况以及技术团队的积累,探索适合产品的落地方案,在迭代过程中打磨产品和技术。