本文主要分为三部分:
- GP优化需要准备的一些关于优化之外的知识,包括清空缓存、性能监控、执行计划分析。
- 具体优化措施,从以下四个方面考虑:
- 表、字段
- sql
- GP配置、服务器配置
- 硬件及节点资源
- GP的性能极限分析
1. 前置知识
1.1 GP清除缓存
数据库一般都有缓存,所以我们为了测试查询性能,需要将缓存清除。
停止数据库并不能清空缓存,因为缓存是由操作系统创建的,一般只有重启操作系统可以完全清空.
参考思路如下:
#!/usr/bin/sudo bash
gpstop -r
sync //清空高速缓存前尝试将数据刷新至磁盘
//释放linux内存
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
gpstart
1.2 性能监控Performance Monitor
新一代Greenplum监控管理平台Pivotal Greenplum Command Center (GPCC)。
实际使用过程中发现对于6-8秒的查询(单表亿级数据),GPCC反应比较慢,CPU、IO等信息为0,目前拟采用其他工具,实时监控CPU、内存、IO、网络等信息。
1.3 执行计划分析
- EXPLAIN会为查询显示其查询计划和估算的代价,但是不执行该查询。
- EXPLAIN ANALYZE除了显示查询的查询计划之外,还会执行该查询。EXPLAIN ANALYZE会丢掉任何来自SELECT语句的输出,但是该语句中的其他操作会被执行(例如INSERT、UPDATE或者DELETE)。
https://www.cnblogs.com/arthurqin/p/6243277.html
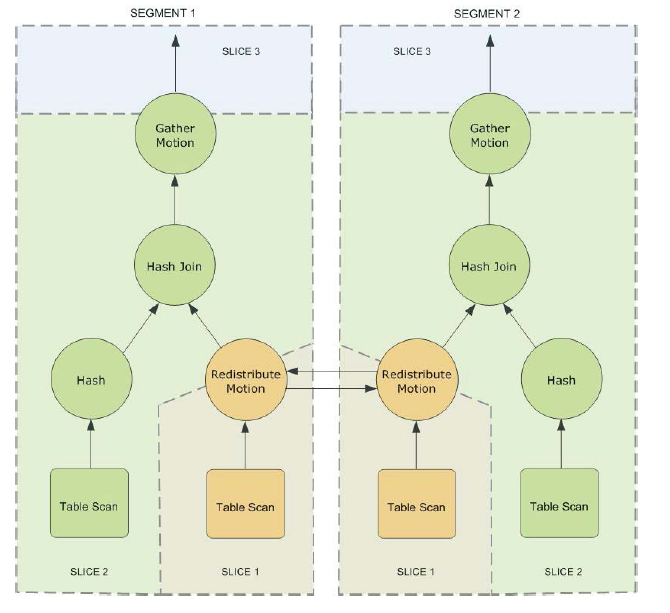
slice、motion
GPDB 有一个特有的算子:移动( motion )。移动操作涉及到查询处理期间在 Segment 之间移动数据。motion 分为广播( broadcast )、重分布( redistribute motion )、Gather motion。正是 motion 算子将查询计划分割为一个个 slice ,上一层 slice 对应的进程会读取下一层各个 slice 进程广播或重分布的数据,然后进行计算。
每一个广播或重分布或gather会产生一个slice。每一个切片在每个数据节点会对应发起一个进程来处理该slice负责的数据。SQL中要控制切片的数量,如果太多,应适当将sql拆分,避免由于进程太多,给数据库、机器带来太多的负担,也容易导致sql失效。
Gather motion的作用就在于将每个节点上面的中间结果集中到主节点上面。
优化
总的思路
- 表、字段
- sql
- GP配置、OS配置
- 硬件及节点资源
1、表字段设计
如上面例子所示,优化某些字段的设计,以提高性能
2、表存储方式
Heap 或 Append-Only存储:GP默认使用堆表。堆表最好用在小表,如:维表(初始化后经常更新)。Append-Only表不能update和delete。一般用来做批量数据导入。 不建议单行插入。
多列查询请求
- 行存储 => 在select或where子句中,查询所有列或大部分列
- 列存储 => 在where或having子句中,查询单列的值汇总或单行过滤
若数据需要频繁地更新或者插入,则使用行存储。
若需要同时访问一个表的很多字段,则使用行存储。
对于通用或者混合型业务,建议使用行存储。
若查询访问的字段数目较少,或者仅在少量字段上进行聚合操作,则使用列存储。
若仅常常修改表的某一字段而不修改其他字段,则使用列存储。
3、压缩
对于大AO表和分区表使用压缩,以提高系统I/O。
在字段级别配置压缩。
考虑压缩比和压缩性能之间的平衡。
压缩的性能取决于硬件、查询调优设置、其它因素。
- QuickLZ - 低压缩率、低cpu消耗、压缩数据块
- zlib - 高压缩率、低速
4、列存储
列存里面可以启动压缩。
只适合append-only表。
5、索引
高基数的列(唯一值多)
一般来说,在Greenplum数据库中索引不是必需的。
对于高基数的列存储表,如果需要遍历且查询选择性较高,则创建单列索引。
频繁更新的列不要建立索引。
在加载大量数据之前删除索引,加载结束后再重新创建索引。
优先使用 B 树索引。
不要为需要频繁更新的字段创建位图索引。
不要为唯一性字段、基数非常高或者非常低的字段创建位图索引。
不要为事务性负载创建位图索引。
一般来说不要索引分区表。如果需要建立索引,则选择与分区键不同的字段。
可优化部分小结果集查询。
6、分布键
7、 分组扩展
Greenplum数据库的GROUP BY扩展可以执行某些常用的计算,且比应用程序或者存储过程效率高。
GROUP BY ROLLUP(col1, col2, col3)
GROUP BY CUBE(col1, col2, col3)
GROUP BY GROUPING SETS((col1, col2), (col1, col3))
8、分区
黄金法则
目前Greenplum支持LIST和RANGE两种分区类型。
分区的目的是尽可能的缩小QUERY需要扫描的数据量,因此必须和查询条件相关联。
只为大表设置分区,不要为小表设置分区。
仅在根据查询条件可以实现分区裁剪时使用分区表。
建议优先使用范围 (Range) 分区,否则使用列表 (List) 分区。
根据查询特点合理设置分区。
不要使用相同的字段既做分区键又做分布键。
不要使用默认分区。
避免使用多级分区;尽量少地创建分区,每个分区的数据会多些。
通过查询计划的 EXPLAIN 结果来确保对分区表执行的查询是选择性扫描(分区裁剪)。
对于列存储的表,不要创建过多的分区,否则会造成物理文件过多:
Physical files = Segments * Columns * Partitions。
9、根据监控定位资源占用较多的情况:
- CPU
- 内存
- IO
- 网络
笔者目前耗费资源比较多的是内存,主要需要优化内存、增加内存。
10、 数据库配置优化
-
Greenplum企业应用实战第8章
-
查询缓存
-
线程数量与内存
-
gp_statement_mem :单个查询可以使用的内存总量。如果它太大,则并发数越小。所以要有所折衷。
11、硬件选型
-
- Greenplum企业应用实战第8章
- gp性能管理
硬件考虑因素:
- (1)Segment服务器具有相同的硬件配置;推荐:双核,32GB Mem,高速磁盘阵列,4个以上千兆网口。
- (2)Master服务器具有较高的cpu和内存资源;
- (3)基准性能:3.2GB/s(综合的系统磁盘读写速度)
12、 估值计算
估值计算是统计学的常用手段。因为数据量庞大,求精确数值需要耗费巨大的资源,而统计分析并不要求完全精确的数据,因此估值计算是一种折中的方法,广泛应用于统计分析场景。
秒级任意维度分析1TB级大表 - 通过采样估值满足高效TOP N等统计分析需求
13、 服务器参数调整
- 共享内存
- 网络
- 系统对用户的限制,比如打开文件句柄的数量。
GP的性能极限分析
MPP架构
Greenplum实现了基于数据库的分布式数据存储和并行计算
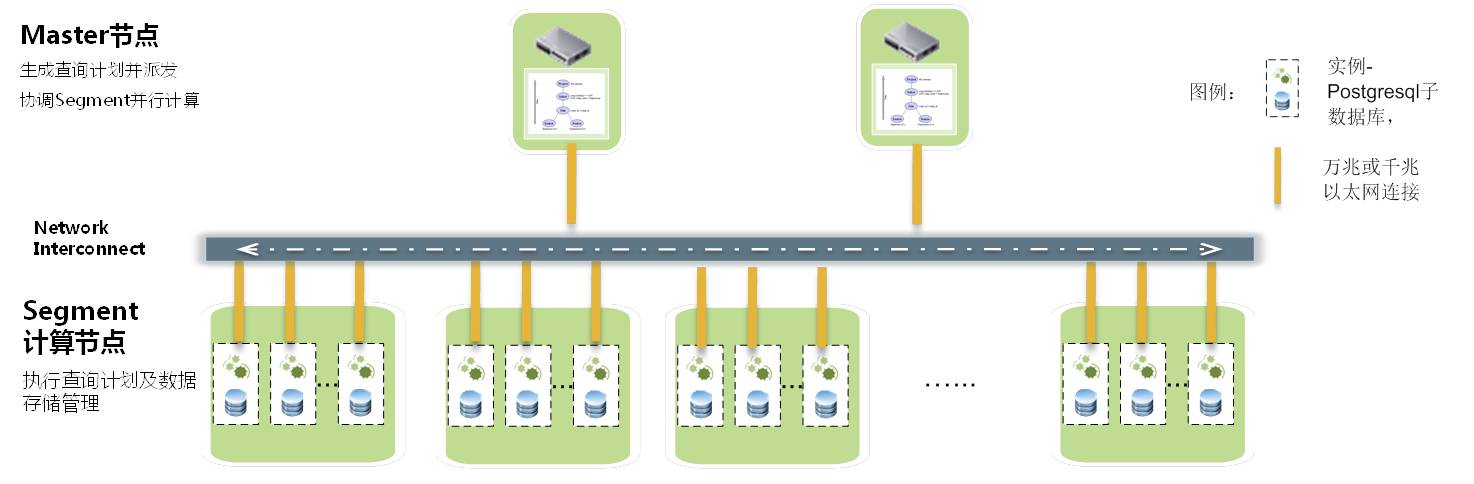
MPP架构的极限思考?
根据木桶原理以及这篇文章(https://clickhouse.yandex/benchmark.html#["100000000",["Greenplum"],["0","1","2"]])的测试结果,segment节点的PG实例的处理速度决定。如果OLAP的处理速度在3秒内,可以计算单segment在3秒以内能处理多少速度,然后再做横向扩展。
参考文献
- Greenplum性能调优
- gp性能管理
- http://greenplum.cn/articles/gpdb-best-practice.html
- 清空postgresql shared_buffers
- https://yq.aliyun.com/articles/73038?utm_campaign=wenzhang&utm_medium=article&utm_source=QQ-qun&201745&utm_content=m_15961
- Greenplum优化--SQL调优篇
- https://github.com/digoal/blog/blob/master/201707/20170725_01.md#greenplum-性能评估公式---阿里云hybriddb-for-postgresql最佳实践