上一篇文章已经对ArrayList进行了分析,那么这篇文章就来讲讲经常和它进行对比的LinkedList吧。
LinkedList是啥
LinkedList本质上是一个双向的链表,首先在这里解释下链表的组成结构。
一个链表是由许多的节点(Node)所组成的,而每个节点内部其实由三部分组成:
1.指向前一个节点内存地址的引用
2.这个节点本身所拥有的元素
3.指向后一个节点内存地址的引用
这么说比较抽象,还是一样,用一张图来解释下每个节点的组成:

可以看到,正是因为每个节点都维护了它前一个节点和后一个节点的引用,所以无论是从前往后还是从后往前都可以查询到每一个节点,即双向链表。
节点定义在源码中相关部分如下:
1 private static class Node<E> { 2 E item; //实际元素的值 3 Node<E> next; //指向下一个节点的地址 4 Node<E> prev; //指向上一个节点的地址 5 6 Node(Node<E> prev, E element, Node<E> next) { //节点构造方法 7 this.item = element; 8 this.next = next; 9 this.prev = prev; 10 } 11 }
如果还是觉得比较抽象,不妨想象一下生活中常见的铁链,应该就比较好理解啦~
LinkedList核心源码分析(JDK Version 1.8)
首先是相关属性:
1 transient int size = 0; 2 3 transient Node<E> first; 4 5 transient Node<E> last;
第一行的size指的是链表中节点的个数
第三行的first指向了链表中的头节点
第五行的last指向了链表中的尾节点
然后是相关的方法:
1.获取集合中某个索引处元素的方法
1 /** 2 * 返回指定位置处节点的元素值 3 * 4 * @param 指定位置 5 * @return 节点元素 6 * @throws 越界异常 7 */ 8 public E get(int index) { 9 checkElementIndex(index); //检查用户指定索引位置是否越界 10 return node(index).item; //返回指定索引处节点的元素值 11 } 12 13 /** 14 * 返回指定索引位置处的节点 15 */ 16 Node<E> node(int index) { 17 // LinkedList是双向链表,所以可以进行双向查找,效率提高 18 if (index < (size >> 1)) { //如果指定位置在list节点数量的一半之前,则从前向后查找 19 Node<E> x = first; //首先x保存的是头节点 20 for (int i = 0; i < index; i++) 21 x = x.next; //循环往后查找,每次循环前都将x的引用指向当前节点的下一个节点 22 return x; //跳出循环时x的引用就是index位置处的节点对象 23 } else { //如果指定位置在list节点数量的一半之后,则从后向前查找 24 Node<E> x = last; 25 for (int i = size - 1; i > index; i--) 26 x = x.prev; 27 return x; 28 } 29 }
可以看到这里先判断用户指定索引位置是在list总节点数量的一半之前还是之后,以之确定查找元素的方向,提高查找效率。
2.设置集合中某个索引处为新元素的方法
1 /** 2 * 将指定位置处节点的元素值替换为自定义的值 3 * 4 * @param 指定索引位置 5 * @param 要替换成自定义的值 6 * @return 原先被替换了的值 7 * @throws 越界异常 8 */ 9 public E set(int index, E element) { 10 checkElementIndex(index); //检查索引是否越界 11 Node<E> x = node(index); //获取指定索引处原先的节点对象 12 E oldVal = x.item; //将原先该节点的值保存下来 13 x.item = element; //将该节点的元素值替换为新值 14 return oldVal; //返回该节点原先的元素值 15 }
就是替换值的一个过程,没啥好说的。
3.往链表中添加节点的方法
1 /** 2 * add方法,默认把元素添加到链表的尾部 3 * 4 * @param e 要添加的元素 5 * @return true 添加成功 6 */ 7 public boolean add(E e) { 8 linkLast(e); //实际调用的是linkLast(e)这个方法 9 return true; 10 } 11 12 /** 13 * 将元素e设置为链表尾部节点 14 */ 15 void linkLast(E e) { 16 final Node<E> l = last; //将原先的尾节点赋值给 l变量(可能为空) 17 final Node<E> newNode = new Node<>(l, e, null); //新建一个保存元素e的节点,前驱指向原来的尾节点 l,后驱指向为null 18 last = newNode; //将当前的尾节点更新为新建的这个节点 19 if (l == null) //若原先尾节点为null,说明这个链表原先就是空的,此次放入的e元素是其第一个节点 20 first = newNode; //将当前链表的头节点设置为新增的e元素节点(此时链表中有且只有一个节点,头节点和尾节点都指向这个e元素节点) 21 else //若原先尾节点不是null,则说明原先链表里就存在节点 22 l.next = newNode; //那么将原先的尾节点(已经在上面第16行赋值给了 l 变量)的后驱指向新建的这个节点即可(这个新建节点已经在上面第18行设置为了当前链表的尾节点) 23 size++; //链表节点数量加1 24 modCount++; 25 }
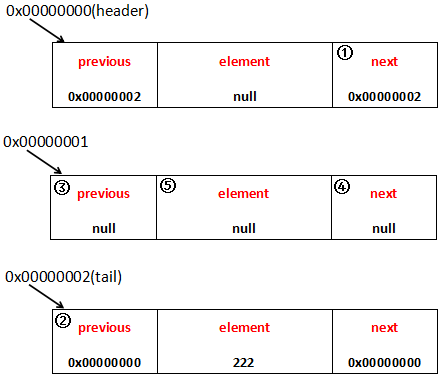
简单来说就是分原来链表中 有节点/无节点 两种情况。 看起来有些麻烦,用张图来表示这个过程吧:

简单描述一下整个插入节点111、222的过程(从上往下):
1.最开始,链表中只有一个空元素的节点,其内存地址为00000000,此时头节点和尾节点都指向这个节点
2.然后插入元素111的节点,该节点对应内存地址为00000001,将空元素节点的后驱指向111节点内存地址,
并将111节点的前驱和后驱都指向上一个空元素节点的内存地址(因为LinkedList是一个双向链表,所以尾节点的后驱会指向头节点,头节点的前驱会指向尾节点)
此时头节点为null元素的节点,尾节点为111元素的节点
3.然后插入元素222的节点,该节点对应内存地址为00000002,将111元素节点的后驱指向该节点内存地址④
并将222节点的前驱指向111元素节点的内存地址③,且将222节点的后驱指向头节点空元素的内存地址②,并将头节点的前驱指向该222节点的内存地址⑤
此时头节点为null元素的节点,尾节点为222元素的节点,即图片中目前的状态。
P.S 我还是觉得看源码及注释比较容易理解呢。。。这段描述就当做一个辅助参考吧 :)
4.删除链表中节点的方法
1 /** 2 * 删除链表中第一个和指定元素相同的节点,删除成功返回true 3 * 链表中没有要删除的元素节点,则返回false 4 * 5 * @param o 需要删除的元素 6 * @return true/false 7 */ 8 public boolean remove(Object o) { 9 if (o == null) { //如果要删除的元素为 null 10 for (Node<E> x = first; x != null; x = x.next) { 11 if (x.item == null) { //找到第一个为null的元素 12 unlink(x); //调用unlink()方法删除节点 13 return true; 14 } 15 } 16 } else { //如果要删除元素非null 17 for (Node<E> x = first; x != null; x = x.next) { 18 if (o.equals(x.item)) { //找到第一个和该元素相等的节点 19 unlink(x); //调用unlink()方法删除节点 20 return true; 21 } 22 } 23 } 24 return false; 25 } 26 27 /** 28 * 删除节点 29 */ 30 E unlink(Node<E> x) { 31 // assert x != null; 32 final E element = x.item; //分别获取要删除节点的 前驱节点、元素、后驱节点 33 final Node<E> next = x.next; 34 final Node<E> prev = x.prev; 35 36 if (prev == null) { //如果当前要删除节点指向的前驱节点为空,则说明要删除的节点就是头节点 37 first = next; //将头节点变更为当前删除节点的下一个节点 38 } else { //如果当前要删除的节点不是头节点 39 prev.next = next; //将前一个节点的后驱指向当前被删除节点的下一个节点 40 x.prev = null; //被删除节点的前驱置为null 41 } 42 43 if (next == null) { //如果当前要删除节点指向的后驱节点为空,则说明要删除的节点就是尾节点 44 last = prev; //将尾节点变更为当前删除节点的前一个节点 45 } else { //如果当前要删除的节点不是尾节点 46 next.prev = prev; //将当前删除节点后一个节点的前驱指向当前被删除节点的上一个节点 47 x.next = null; //被删除节点的后驱置为null 48 } 49 50 x.item = null; //被删除节点元素置为null 51 size--; //链表节点数量减1 52 modCount++; 53 return element; //返回被删除节点的元素 54 }
可以看到删除节点其实调用的都是 unlink(Node<E> x) 这个方法,只是分为要删除的节点为头节点、尾节点、和既不是头节点也不是尾节点的一般节点这三种情况。同样用图表示一下删除节点的过程:
接着上面一张图中节点的状态,同样"简单"描述一下删除节点111的过程:
1.首先循环链表,找到第一个元素值为111的节点,即内存地址为00000001的这个节点,并调用 unlink(Node<E> x) 这个方法。
2.判断出删除的该节点不是头节点,则将前一个节点(即内存地址为00000000的节点)的后驱引用指向当前删除节点的后一个节点(即内存地址为00000002的节点)①,并将当前删除节点的前驱引用置为null③
3.同样删除的节点并不是尾节点,则会将后一个节点(00000003节点)的前驱引用指向当前删除节点的前一个节点(00000000节点)②,并将当前删除节点的后驱引用置为null④
4.最后,将当前删除节点的元素置为null⑤,这个节点就变为了无效引用的节点,会被GC发现并回收该节点内存空间,也即完成了一次删除节点的过程。
注:以上图片均来源于 博客园——五月的仓颉 ,非本人原创 !
老生常谈的ArrayList VS LinkedList
这个问题想必前几年面试过的童鞋都快被问吐了 :)
其实如果看到这里的话答案已经很清楚了,问这道题的本质意图就是想看你是否清楚这两个集合底层的数据结构以及这种数据结构的特性,顺便看看你对这块源码的熟悉程度。
只要回答出ArrayList底层是数组结构,因为数组有维护索引,所以查询效率高;而做插入、删除操作时,因为要判断扩容(复制一份新数组)且数组中的元素可能要大规模的后移或前移一个索引位置,所以效率差。
而LinkedList因为底层为链表结构,查询时需要从头节点(或尾节点)开始遍历所以查询效率差;但同时也因为是链表结构,做插入、删除操作时只要断开当前删除节点前驱、后驱引用,并将原来的前、后节点的引用链接起来,所以效率高。
但是假设你这么回答,ArrayList的就是查询效率高,插入删除效率低;LinkedList就是查询效率低,插入删除效率高,那么如果面试官是一个较真的人,他会问你真的是这样吗?
如果我ArrayList在尾部插入节点,并且这次插入节点并不需要扩容操作呢?而我LinkedList要查询的节点其实就是头节点(或尾节点)呢?又或者我使用了迭代器遍历LinkedList呢?你还是确信你给出的答案吗?
所以,我们在回答问题的时候不能一概说某某好、某某不好,要透过问题看到问题的本质,讲清楚、讲明白与问题相关技术的本质,并且能说出每个技术的适用场景以及优缺点,这么做保证能让面试官满意。
一个关于LinkedList的注意点
最后再讲一个需要注意的点,千万不要使用普通for循环遍历LinkedList,这么做会让你崩溃!可以选择使用foreach或迭代器来进行遍历操作。注:普通for循环指的是 for(int i=0; i<100; i++){....} 这样的遍历方式。
为什么呢?想必聪明的童鞋们已经知道答案了 ;),其实主要就是两种遍历方式取数据的方式不同:
普通for循环是直接从头(尾)结点开始一个接一个往后(前)取,每次都要把当前循环到的节点对象取出来并和要查找的节点进行比较;
而foreach或迭代器是直接从内存地址下手,直接定位要查找节点开始的内存地址,计算出结束的内存地址后取出的这段内存地址就是要寻找的节点。
还不是很明白的童鞋,可以看一下这篇文章,应该讲的非常清楚了:
https://blog.csdn.net/zhangyuan19880606/article/details/51252361
好了,到这里LinkedList就全部讲完了,希望本篇文章能够让大家有所收获。
预告下一篇文章内容: HashMap分析