大纲:
1、双层装饰器
单层装饰器
双层装饰器
原理
2、字符串的格式化
3、format字符串格式化
4、生成器
5、递归
6、模块的安装
7、json模块
8、pickle模块
9、time模块
10、datetime模块
11、logging模块
双层装饰器
还是老样,没有改变:


USER_INFO = {} def check_login(func): def inner(*args, **kwargs): if USER_INFO.get("is_login", None): # 用get方法拿字典里面的内容,如果字典里面没有我们要拿的参数,不会报错,给他默认返回的为None ret = func(*args, **kwargs) return ret else: print("请登录") return inner def check_admin(func): # 判断是否为管理员用户 def inner(*args, **kwargs): if USER_INFO.get("is_login", None): if USER_INFO.get("user_type", None) == 2: # 如果用户类型等于2,表示为管理员用户 ret = func(*args, **kwargs) return ret else: print("无权限查看") # 否者无权限查看 else: print("请登录") return inner @check_admin def index(): # 超级管理员可以查看 print("index") @check_login def home(): # 登录可以查看 """ 普通用户的功能 :return: """ print("home") def login(): # 登录 user = input("请输入用户名:") if user == "admin": USER_INFO["is_login"] = True USER_INFO["user_type"] = 2 else: # 否者如果不为admin,表示登录的用户为普通用户 USER_INFO["is_login"] = True USER_INFO["is_login"] = 1 def main(): while True: inp = input("1、登录;2、查看信息;3超级管理员 >>>") if inp == "1": login() elif inp == "2": home() elif inp == "3": index() main()
输出:
1、登录;2、查看信息;3超级管理员 >>>2 请登录 1、登录;2、查看信息;3超级管理员 >>>3 请登录 1、登录;2、查看信息;3超级管理员 >>>1 请输入用户名:user 1、登录;2、查看信息;3超级管理员 >>>2 home 1、登录;2、查看信息;3超级管理员 >>>3 无权限查看 1、登录;2、查看信息;3超级管理员 >>>1 请输入用户名:admin 1、登录;2、查看信息;3超级管理员 >>>2 home 1、登录;2、查看信息;3超级管理员 >>>3 index 1、登录;2、查看信息;3超级管理员 >>>
新变化:
# 从版本以一中我们可以看到很多我们的check_admin里面重复了check_login的代码(check_admin又判断登录,又判断权限), # 如果我们又加上了超级管理员,那我们就会又写一个重复的装饰器, # 所以我们需要用到双层装饰器,先用check_login,判断是否登录,然后用check_admin判断是否为管理员 USER_INFO = {} def check_login(func): def inner(*args, **kwargs): if USER_INFO.get("is_login", None): # 用get方法拿字典里面的内容,如果字典里面没有我们要拿的参数,不会报错,给他默认返回的为None ret = func(*args, **kwargs) return ret else: print("请登录") return inner def check_admin(func): # 判断是否为管理员用户 def inner(*args, **kwargs): if USER_INFO.get("user_type", None) == 2: # 如果用户类型等于2,表示为管理员用户 ret = func(*args, **kwargs) return ret else: print("无权限查看") # 否者无权限查看 return inner # 为什么check_login写上面,我们从下向上看,从index()开始, # 可以看到先用admin装饰后,比如变成了nindex这个函数,然后再用login装饰进行装饰,比如又变成了nnindex,然后python是从上向下执行, # 所以python会执行nnindex,判断是否登录,然后在执行nindex,判断是否为管理员,如果没有登录, # 提示登录,如果已经登录(不为管理员),提示无权限 @check_login @check_admin def index(): # 管理员可以查看 """ 管理员的功能 :return: """ print("index") @check_login def home(): # 登录可以查看 """ 普通用户的功能 :return: """ print("home") def login(): # 登录 user = input("请输入用户名:") if user == "admin": USER_INFO["is_login"] = True USER_INFO["user_type"] = 2 else: # 否者如果不为admin,表示登录的用户为普通用户 USER_INFO["is_login"] = True USER_INFO["is_login"] = 1 def main(): while True: inp = input("1、登录;2、查看信息;3超级管理员 >>>") if inp == "1": login() elif inp == "2": home() elif inp == "3": index() main()
输出:
1、登录;2、查看信息;3超级管理员 >>>2 请登录 1、登录;2、查看信息;3超级管理员 >>>3 请登录 1、登录;2、查看信息;3超级管理员 >>>1 请输入用户名:user 1、登录;2、查看信息;3超级管理员 >>>2 home 1、登录;2、查看信息;3超级管理员 >>>3 无权限查看 1、登录;2、查看信息;3超级管理员 >>>1 请输入用户名:admin 1、登录;2、查看信息;3超级管理员 >>>2 home 1、登录;2、查看信息;3超级管理员 >>>3 index 1、登录;2、查看信息;3超级管理员 >>>
输出效果完全一样,注意看v2的注释
装饰器的原理(多层原理也一样):
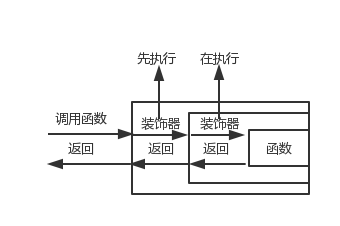
字符串的格式化:
%[(name)] [flags] [width].[precision] typecode
# 字符串格式化 # %[(name)] [flags] [width].[precision] typecode # 常规的格式化 string = "博客网址:www.cnblogs.com/%s,园龄:%d个月" % ("smelond", 1) print(string) # %[(name)]可选,用于指定的key: string = "博客网址:www.cnblogs.com/%(name)s,园龄:%(age)d个月" % {"name": "smelond", "age": 1} # 用字典方式 print(string) # flags 可选,可供选择的值有(听说没卵用) # + 右对齐:正数前加正号,负数前加负号 # - 左对齐:正数前无符号,负数前加负号 # 空格 右对齐:正数前加空格,负数前加负号 # 0 右对齐:正数前无符号,负数前加负号;用0填充空白处 string = "博客网址:www.cnblogs.com/%(name)+20s,园龄:%(age)-10d个月" % {"name": "smelond", "age": 1} # 占有20个空格,smelond在其中,向右对齐 print(string) # width 可选,占有宽度 # .precision 可选,小数点后保留的位数 string = "数值:%(p).2f" % {"p": 1.23656} # 在后面加上.然后数字,代表保留几位,有四舍五入功能 print(string) # typecode 必选 # s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置 # r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置(面向对象内容) # c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置 # o,将整数转换成 八 进制表示,并将其格式化到指定位置 # x,将整数转换成十六进制表示,并将其格式化到指定位置 string = "%c___%o___%x" % (65, 15, 15) # 将十进制转换为其他进制(A,17,f) print(string) # d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置 # e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e) # E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E) # f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位) # F,同上 string = "%d--------%f--------%e--------%E-------%.2ef" % (100000000, 1.23456, 10000000, 10000000, 10000000) print(string) # g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;) # G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;) string = "%g-------%g-------%G-------%G" % (10000000, 100, 10000000, 100) print(string) # %,当字符串中存在格式化标志时,需要用 %%表示一个百分号 string = "name:%s %% %%%%" % "smelond" # 如果需要输出一个%,但是前面已经有了一个占位符,那就需要输出%%才能代表一个%,否者会报错,需要输出%%,就需要%%%% print(string) # # 注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
博客网址:www.cnblogs.com/smelond,园龄:1个月 博客网址:www.cnblogs.com/smelond,园龄:1个月 博客网址:www.cnblogs.com/ smelond,园龄:1 个月 数值:1.24 A___17___f 100000000--------1.234560--------1.000000e+07--------1.000000E+07-------1.00e+07f 1e+07-------100-------1E+07-------100 name:smelond % %%
format格式化:
# [[fill]align] [sign] [#] [0] [widht] [,] [.precision] [type]
# fill 【可选】空白处填充的字符 # align 【可选】对齐方式(需配合width使用) # < ,内容左对齐 # > ,内容右对齐(默认) # =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号 + 填充物 + 数字 # ^ ,内容居中 # sign 【可选】有无符号数字 # +,正号加正,负号加负; # -,正号不变,负号加负; # 空格 ,正号空格,负号加负; # # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示 # , 【可选】为数字添加分隔符,如:1, 000, 000 # width 【可选】格式化位所占宽度 # .precision 【可选】小数位保留精度 # type 【可选】格式化类型 # 传入” 字符串类型 “的参数 # s,格式化字符串类型数据 # 空白,未指定类型,则默认是None,同s # 传入“ 整数类型 ”的参数 # b,将10进制整数自动转换成2进制表示然后格式化 # c,将10进制整数自动转换为其对应的unicode字符 # d,十进制整数 # o,将10进制整数自动转换成8进制表示然后格式化; # x,将10进制整数自动转换成16进制表示然后格式化(小写x) # X,将10进制整数自动转换成16进制表示然后格式化(大写X) # 传入“ 浮点型或小数类型 ”的参数 # e, 转换为科学计数法(小写e)表示,然后格式化; # E, 转换为科学计数法(大写E)表示,然后格式化; # f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化; # F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化; # g, 自动在e和f中切换 # G, 自动在E和F中切换 # % ,显示百分比(默认显示小数点后6位)
# 两个最基本的格式化 string = "asdfasgsdf__{0}__asdf__{0}__adhkg__{1}__".format(123, "smelond") print(string) # asdfasgsdf__123__asdf__123__adhkg__smelond__ string = "___{name:s}___{age:d}___{name:s}".format(name="smelond", age=16) print(string) # ___smelond___16___smelond # 一些常用的用法 # 空白处填充*,^字符居中,20个空格,s:字符串形式{:*^20s} # +有符号数值,d:十进制{:+d} # x 直接转换为16进制 # #如果后面输入的为x,那就转换为16进制后再前面加上0x{:#x} string = "_____{:*^20s}_____{:+d}_____{:x}_____{:#x}".format("smelond", 123, 15, 15) print(string) # _____******smelond*******_____+123_____f_____0xf string = "百分比:{:%}".format(1.2345) print(string) # 百分比:123.450000%
# 一些常用的用法 tpl = "i am {},age {},{}".format("seven", 16, "smelond") print(tpl) # i am seven,age 16,smelond tpl = "i am {},age {},{}".format(*["seven", 16, "smelond"]) print(tpl) # i am seven,age 16,smelond,注意,如果是列表要在前面加上* tpl = "i am {0},age {1}, really {0}".format("seven", 16) print(tpl) # i am seven,age 16, really seven tpl = "i am {0},age {1}, really {0}".format(*["seven", 16]) print(tpl) # i am seven,age 16, really seven,列表需要加上* tpl = "i am {name}, age {age}, really {name}".format(name="smelond", age=16) print(tpl) # i am smelond, age 16, really smelond tpl = "i am {name}, age {age}, really {name}".format(**{"name": "smelond", "age": 16}) print(tpl) # i am smelond, age 16, really smelond,注意,如果是字典需要加上两个* tpl = "i am {0[0]}, age {0[1]}, really {1[2]}".format([1, 2, 3], [11, 22, 33]) print(tpl) # i am 1, age 2, really 33,列表里面的列表 tpl = "i am {:s}, age {:d}".format("smelond", 16) print(tpl) # i am smelond, age 16 tpl = "i am {name:s}, age {age:d}".format(name="smelond", age=16) print(tpl) # i am smelond, age 16 tpl = "i am {name:s}, age {age:d}".format(**{"name": "smelond", "age": 16}) print(tpl) # i am smelond, age 16,字典需要加上** tpl = "numbers:{:b},{:o},{:d},{:x},{:X},{:%}".format(15, 15, 15, 15, 15, 15.87612) print(tpl) # s:1111,17,15,f,F,1500.000000% tpl = "numbers:{0:b},{0:o},{0:d},{0:x},{0:X},{0:%}".format(15) print(tpl) # s:1111,17,15,f,F,1500.000000% tpl = "numbers:{num:b},{num:o},{num:d},{num:x},{num:X},{num:%}".format(num=15) print(tpl) # s:1111,17,15,f,F,1500.000000%
生成器的使用(生成器是使用函数创建的):
# 普通函数 # def func(): # return 123 # # # ret = func() # 执行函数拿结果 # 生成器 def func(): # print("start") print(111) yield 1 print(222) yield 2 print(333) yield 3 # 如果在函数里面出现了yield,这个函数就称之为生成器 ret = func() print(ret) # for i in ret: # print(i) # 输出 # 循环第一次的时候就进入func函数里面去,进入后拿走yield后面的值,所以输出1,然后循环第二次, # 第二次进入func函数时,找到上一次结尾的位置,从结尾的位置又开始循环(往下走),所以就是输出2 # 然后第三次 r1 = ret.__next__() # 进入函数找到yield,获取yield后面的数据,然后我们就拿到了1 print(r1) r2 = ret.__next__() # 进入函数找到yield,获取yield后面的数据,然后我们就拿到了2 print(r2) r3 = ret.__next__() # 进入函数找到yield,获取yield后面的数据,然后我们就拿到了3 print(r3) # r4 = ret.__next__() # print(r4) # 从函数里面可以看到没有第4个yield,所以这句要报错 #输出: 111 1 222 2 333 3
# 基于生成器实现range功能 def myrange(arg): # 相当于这是一个生成器 start = 0 while True: if start > arg: return yield start start += 1 ret = myrange(3) # for i in ret: # print(i) r = ret.__next__() print(r) r = ret.__next__() print(r) r = ret.__next__() print(r) r = ret.__next__() print(r) # r = ret.__next__() # print(r)#第四次肯定报错,因为只循环3次,从0开始 输出: 0 1 2 3
python的递归:
自己拿着windows自带的画图工具画的,将就看吧,是有点丑
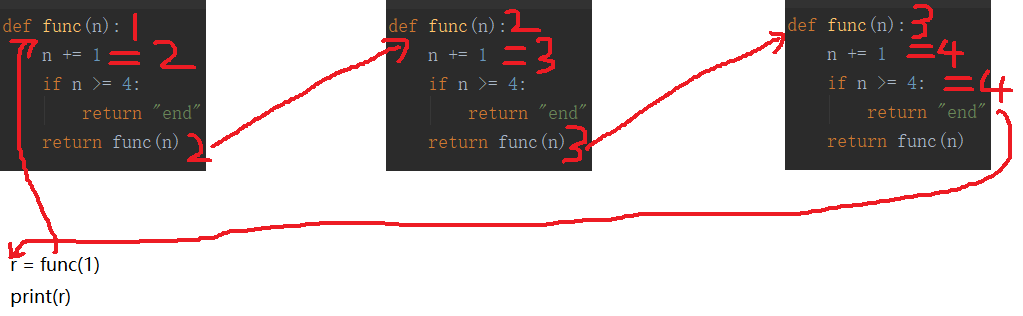
代码贴上
# 一个递给另外一个,一个简单的原理 def d(): r = "end" # 将字符串end赋给r return r # 返回一个变量r def c(): r = d() # 拿到函数d的返回值 return r def b(): r = c() # 拿到函数c的返回值 return r def a(): r = b() # 拿到函数b的返回值 print(r) # 拿到结果后输出 a() # 输出end # 递归 # 执行第一次时的效果 def func(n): # 现在n=1 n += 1 # n等于2 if n >= 4: # 当如果n>=4的时候 return "end" # 遇到return直接退出,然后返回一个字符串end return func(n) # 上面if如果没执行,肯定会执行这句,返回func函数,现在的n=2 r = func(1) # 传入实参1到func函数里去慢慢执行,然后接收返回值 print(r) #输出end
用递归实现一个1*2*3*4*5*6*7:
def func(n, x): # n=1,x=1.......n=2,x=2.......n=3,x=6 n += 1 # n=2.......n=3.......n=4 x *= n # x=x*n,x=2.......x=x*n,x=6.......x=x*n,x=24 if n >= 7: # 直到n等于7的时候,将x返回 return x return func(n, x) # n=2,x=2.......n=3,x=6....... r = func(1, 1) print(r) 输出:5040
def func(num): if num == 1: return 1 return num * func(num - 1) x = func(7) print(x) 输出:5040
事实证明,我太笨了,我那个太复杂了,而且全是运算,但是老师的感觉就轻快明了
模块的使用及安装
# 导入模块 # 单模块 import call_m # 直接调用当前目录下的call_m.py文件 import lib.commons # 调用lib目录下的commons.py文件 # 嵌套在文件夹下的模块 from lib import commons from src import commons as xxx # 如果重名,我们可以用as给他做一个别名 # call_m.login() # 输出里面的方法,就相当于调用了里面的函数 # lib.commons.logout()
安装requests模块
pip3 install requests
json模块
json只能处理基本的数据类型
import json
# json只能处理基本的数据类型
dic = {"k1": "v1"}
print(dic, type(dic))
# 用json模块将python的基本数据类型转换成为字符串形式
result = json.dumps(dic)
print(result, type(result))
s1 = '{"k1":123}'
# json将python字符串形式转换成为基本数据类型
dic = json.loads(s1)
print(dic, type(dic))
# py基本数据类型转换字符串
r = json.dumps([11, 22, 33])
# li = "['smelond','amanda']" #这种方法不行,因为其他语言里面 ' 和 "跟python不一样
li = '["smelond","amanda"]' # 反序列化时,一定要使用 "
print(r, type(r))
ret = json.loads(li)
print(ret, type(ret))
li = [11, 22, 33]
json.dump(li, open("db", "w")) # dump先把他进行序列化,然后写到文件里面
li = json.load(open("db", "r")) # 从文件里面把字符串读出来,读出来后会转换成为列表类型
print(li, type(li))
用json加requests模块调用天气的api接口
import json
import requests
import sys
response = requests.get("http://www.sojson.com/open/api/weather/json.shtml?city=双流")
response.encoding = "utf-8"
dic = json.loads(response.text)
print(dic)
json/pickle
json更加适合跨语言操作,因为它传递的是字符串,基本数据类型
pickle,对python的所有类型的序列化,仅适用与python
pickle模块
pickle支持任何的类型
# pickle支持任何的类型
import pickle
# dumps a loads
li = [11, 22, 33]
r = pickle.dumps(li) # 字符方式
print(r)
result = pickle.loads(r)
print(result)
# dump a load
li = [11, 22, 33]
pickle.dump(li, open("db", "wb")) ##pickle是以字符方式存取,所以要加上b
resul = pickle.load(open("db", "rb")) # 读取
print(resul)
time&datetime模块
time模块
import time
print(time.process_time()) # 测量处理器运算时间,不包括sleep时间,不稳定
print(time.altzone) # 返回与utc时间的时间差,以秒计算
print(time.asctime()) # 返回时间格式“Sat Dec 30 17:32:59 2017”
print(time.localtime()) # 返回本地时间的struct time对象格式
tm = time.localtime() # 将返回的struct time格式的时间赋给tm
print("{}-{}".format(tm.tm_year, tm.tm_mon)) # 用format输出年月
print(time.gmtime(time.time() - 8000000)) # 返回utc时间的struc时间对象格式
print(time.asctime(time.localtime())) # 返回时间格式“Sat Dec 30 17:39:47 2017”
print(time.ctime()) # 返回时间格式“Sat Dec 30 17:41:44 2017”同上
# 日期字符串 转换 时间戳
string_2_struct = time.strptime("2017/12/30", "%Y/%m/%d") # 将日期字符串 转换 struct时间对象格式
print(string_2_struct)
struct_2_stamp = time.mktime(string_2_struct) # 将struct时间对象转换成为时间戳
print(struct_2_stamp)
print(time.ctime(struct_2_stamp)) # 返回时间为“Sat Dec 30 00:00:00 2017”格式
# 将时间戳转为字符串格式
print(time.gmtime(time.time() - 86640)) # 将utc时间戳转换struct_time格式
print(time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime())) # 将utc struct_time格式转换成指定的字符串格式
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # 将本地 struct_time格式转换成指定的字符串格式
datetime模块
import datetime print(datetime.datetime.now()) # 返回“2017-12-30 17:56:40.261813” print(datetime.date.fromtimestamp(time.time())) # 时间戳直接转换成为日期格式“2017-12-30” # 时间加减 print(datetime.datetime.now()) print(datetime.datetime.now() + datetime.timedelta(3)) # 当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) # 当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) # 当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 当前时间+30分钟 c_time = datetime.datetime.now() # print(c_time.replace(minute=3, hour=2)) # 时间替换,替换小时和分钟 print(c_time.replace(hour=2, minute=3)) # 时间替换,替换小时和分钟
logging模块
logging模式是一个日志模块,很多程序都需要一个记录日志,所以python为我们提供了这么一个模块,logging的日志分为5个等级:debug(),waring(),error(),critical()
日志等级(数字越大,表示危害越高):
critical = 50
error = 40
warning = 30
info = 20
debug = 10
注意:只有【当前写等级】大于【日志等级】时,日志文件才被记录
日志输出,最简单的用法:
import logging
logging.warning("user [smelond] attempted wrong password more than 3 times") # 可以直接输出到屏幕上
logging.critical("server is down")
将日志输出到文件里面:
import logging
logging.basicConfig(filename='example.log', level=logging.INFO) # 设置将输出内容保存到example.log
# level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里
logging.debug("this message should go to the log file") # 不会保存到日志文件里面
logging.info("So should this") # 日志级别也为info,所以可以保存到文件
logging.warning("And this,too") # 这个等级大于info,所以也可以保存到文件里面
将日志输出到文件里面,并且加上时间:
logging.basicConfig(filename='example.log', level=logging.INFO, format="%(asctime)s (message)s", datefmt="%m%d%Y %H:%M:%S %p") # format格式化输出,后面放时间格式
# level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里
logging.debug("this message should go to the log file") # 不会保存到日志文件里面
logging.info("So should this") # 日志级别也为info,所以可以保存到文件
logging.warning("And this,too") # 这个等级大于info,所以也可以保存到文件里面
logging.warning("is when this event was logged.") # 大于info
输出:
01012018 20:16:36 PM So should this
01012018 20:16:36 PM And this,too
01012018 20:16:36 PM is when this event was logged.
以下来自alex li
日志输出格式:
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
logging模块记录日志涉及到的四个主要类:
logger提供了应用程序可以直接使用接口
handler将(logging创建)日志记录发送到合适的目的输出
filter提供了细度设备来决定输出哪条日志记录
formatter决定日志记录的最终输出格式
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些
Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建
一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把
文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建
chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就
自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
将日志文件输出到多个地方:
# 将日志输出到多个地方
import logging
# create logger
logger = logging.getLogger('TEST-LOG') # 设置一个名称
logger.setLevel(logging.INFO) # 设置一个最低日志输出等级,设置为了INFO等级,(全局)
# create console handler and set level to debug
ch = logging.StreamHandler() # 输出到屏幕上
ch.setLevel(logging.DEBUG) # 设置屏幕输出的最低日志等级但是会发现不能输出debug,因为我们上面的全局配置上最低设置成为了INFO等级,DEBIG>INFO
# create file handler and set level to warning
fh = logging.FileHandler("access.log") # 设置输出到文件
fh.setLevel(logging.WARNING) # 设置文件输出的最低等级
# create formatter
formatter_ch = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 格式化
formatter_fh = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s') # 格式化
# add formatter to ch and fh
ch.setFormatter(formatter_ch) # 设置输出到屏幕上的格式
fh.setFormatter(formatter_fh) # 设置输出到日志中的格式
# add ch and fh to logger
logger.addHandler(ch) # 添加handler
logger.addHandler(fh)
# 'application' code
logger.debug('debug message') # 输出提示(不能输出到任何地方)
logger.info('info message') # 输出提示(只能输出到屏幕,因为输出到文件最低等级需要WARNING)
logger.warning('warn message') # 输出提示(双方)
logger.error('error message') # 双方
logger.critical('critical message') # 双方
屏幕输出:
2018-01-02 11:44:34,121 - TEST-LOG - INFO - info message
2018-01-02 11:44:34,121 - TEST-LOG - WARNING - warn message
2018-01-02 11:44:34,121 - TEST-LOG - ERROR - error message
2018-01-02 11:44:34,121 - TEST-LOG - CRITICAL - critical message
文件输出:
2018-01-02 11:44:34,121 - WARNING - warn message
2018-01-02 11:44:34,121 - ERROR - error message
2018-01-02 11:44:34,121 - CRITICAL - critical message