打开网址:http://mv.688ing.com/
输入视频播放地址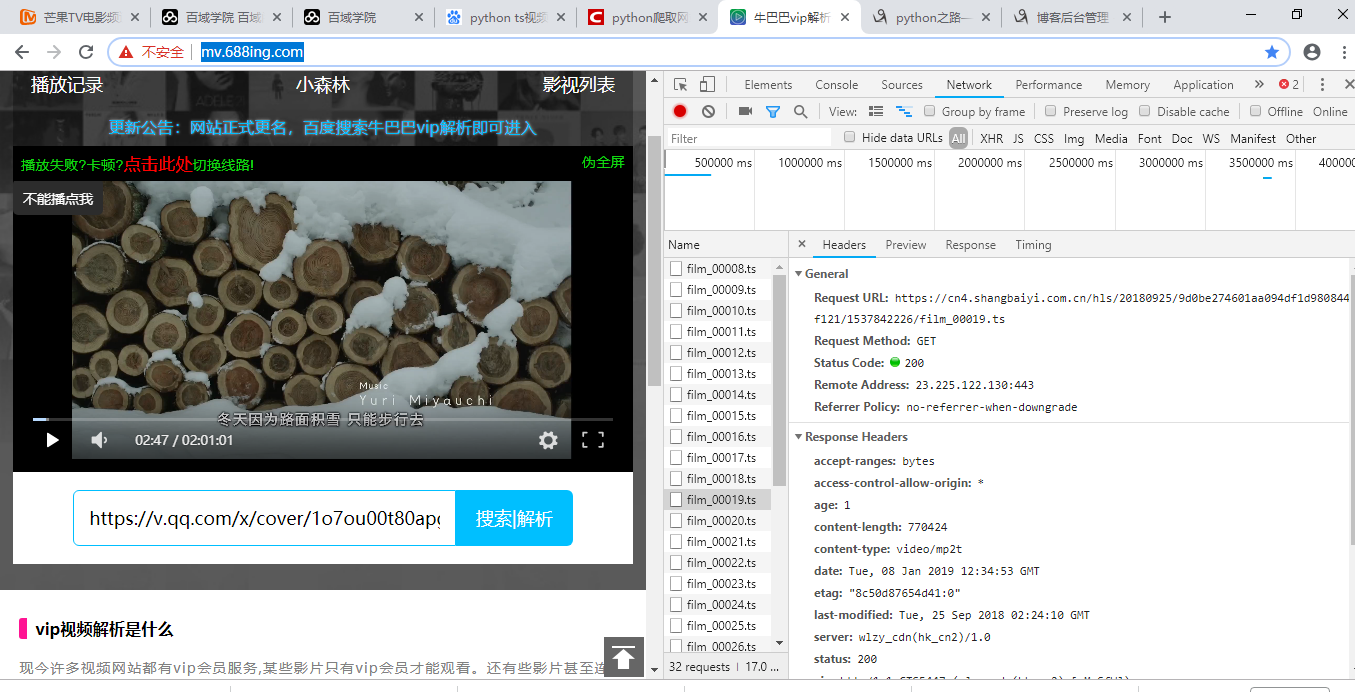
发现很多链接以.ts结尾。
# import requests import os def download(): headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} for i in range(1,100): if i <10: link='https://cn4.shangbaiyi.com.cn/hls/20180925/9d0be274601aa094df1d98084483f121/1537842226/film_0000.ts'+str(i)+'.ts'#构造下载链接 elif i <100: link='https://cn4.shangbaiyi.com.cn/hls/20180925/9d0be274601aa094df1d98084483f121/1537842226/film_000.ts'+str(i)+'.ts' dest_resp = requests.get(link,headers=headers) #视频是二进制数据流,content就是为了获取二进制数据的方法 data = dest_resp.content #保存数据的路径及文件名 download_path = os.getcwd() + "download" path = r'C:UserslenovoDesktop新建文件夹' with open(os.path.join(path, str(i) + ".ts"), 'wb') as f:#写入文件夹 f.write(data) print(i) merge_file(r'C:UserslenovoDesktop新建文件夹')#存视频的文件夹 def merge_file(path):#合并视频 os.chdir(path) cmd = "copy /b * new.tmp" os.system(cmd) os.system('del /Q *.ts') os.system('del /Q *.mp4') os.rename("new.tmp", "new.mp4") if __name__ == '__main__': download()