在Redis存储的所有数据中,有一部分是被频繁访问的。有两种情况可能会导致热点问题的产生,一个是用户集中访问的数据,比如抢购的商品,明星结婚和明星出轨的微博。还有一种就是在数据进行分片的情况下,负载不均衡,超过了单个服务器的承受 能力。热点问题可能引起缓存服务的不可用,最终造成压力堆积到数据库。
热点数据发现
客户端
比如我们可不可以在所有调用了 get、set方法的地方, 加上key的计数。但是这样的话,每一个地方都要修改,重复的代码也多。如果我们用的是Jedis的客户端,我们可以修改Jedis的源码,在Jedis的Connection类的 sendCommand()里面,用一个HashMap进行key的计数。
但是这种方式有几个问题:
1、会对客户端的代码造成入侵。
2、不知道要存多少个key,可能会发生内存泄露的问题。
3、只能统计当前客户端的热点key。
代理层
第二种方式就是在代理端实现,比如TwemProxy或者Codis,但是不是所有的项目都使用了代理的架构。
服务端
第三种就是在服务端统计,Redis有一个monitor的命令,可以监控到所有Redis 执行的命令。
代码:
jedis.monitor(new JedisMonitor() {
@Override
public void onCommand(String command) {
System.out.println(f,#monitor: H + command);
}
});
Facebook的开源项目redis-faina就是基于这个原理实现的。它是一个python脚本,可以分析monitor的数据。
https://github.com/facebookarchive/redis-faina.git
redis-cli -p 6379 monitor | head -n 100000 | ./redis-faina.py
这种方法也会有两个问题:
1) monitor命令在高并发的场景下,会影响性能,所以不适合长时间使用。
2)只能统计一个Red is节点的热点key。
机器层面
还有一种方法就是机器层面的,通过对TCP协议进行抓包,也有一些开源的方案, 比如ELK的packetbeat插件。
当我们发现了热点key之后,我们来看下热点数据在高并发的场景下可能会出现的 问题,以及怎么去解决。
缓存雪崩就是Redis的大量热点数据同时过期(失效),因为设置了相同的过期时间,刚好这个时候Redis请求的并发量又很大,就会导致所有的请求落到数据库。
缓存雪崩的解决方案
1)加互斥锁或者使用队列,针对同一个key只允许一个线程到数据库查询
2)缓存定时预先更新,避免同时失效
3)通过加随机数,使key在不同的时间过期
4)缓存永不过期
缓存穿透
缓存穿透何时发生

在这里Redis起到了提升査询速度和保护数据库的作用。
还有一种情况,数据在数据库和Redis里面都不存在,可能是一次条件错误的査询。
在这种情况下,因为数据库值不存在,所以肯定不会写入Redis,那么下一次査询相同的key的时候,肯定还是会再到数据库查一次。
那么这种循环查询数据库中不存在的值,并且每次使用的是相同的key的情况,我们有没有什么办法避免应用到数据库查询呢?
1)缓存空数据
2)缓存特殊字符串,比如&&
我们可以在数据库缓存一个空字符串,或者缓存一个特殊的字符串,那么在应用里面拿到这个特殊字符串的时候,就知道数据库没有值了,也没有必要再到数据库查询了。
但是这里需要设置一个过期时间,不然的会数据库已经新增了这一条记录,应用也还是拿不到值。
这个是应用重复查询同一个不存在的值的情况,如果应用每一次查询的不存在的值 是不一样的呢?即使你每次都缓存特殊字符串也没用,因为它的值不一样,比如我们的 用户系统登录的场景,如果是恶意的请求,它每次都生成了一个符合ID规则的账号,但 是这个账号在我们的数据库是不存在的,那Redis就完全失去了作用。
这种因为每次查询的值都不存在导致的Redis失效的情况,我们就把它叫做缓存穿透。
面试题:
如何在海量元素中(例如10亿无序、不定长、不重复)快速判断一个元素是否存在?
如果是缓存穿透的这个问题,我们要避免到数据库查询不存的数据,肯定要把这10 亿放在别的地方。为了加快检索速度,我们要把数据放到内存里面来判断,问题来了:
如果我们直接把这些元素的值放到基本的数据结构(List、Map、Tree)里面,比如
一个元素1字节的字段,10亿的数据大概需要900G的内存空间,这个对于普通的服务器来说是承受不了的。
所以,我们存储这几十亿个元素,不能直接存值,我们应该找到一种最简单的最节省空间的数据结构,用来标记这个元素有没有出现。(比如签到表按顺序打钩)
这个东西我们就把它叫做位图,他是一个有序的数组,只有两个值,0和1。0代表 不存在,1代表存在。

那我们怎么用这个数组里面的有序的位置来标记这10亿个元素是否存在呢?我们是不是必须要有一个映射方法,把元素映射到一个下标位置上?
对于这个映射方法,我们有几个基本的要求:
1)因为我们的值长度是不固定的,我希望不同长度的输入,可以得到固定长度的输出。
2)转换成下标的时候,我希望他在我的这个有序数组里面是分布均匀的,不然的话全部挤到一对去了,我也没法判断到底哪个元素存了,哪个元素没存。
这个就是哈希函数,比如MD5、SHA-1等等这些都是常见的哈希算法。
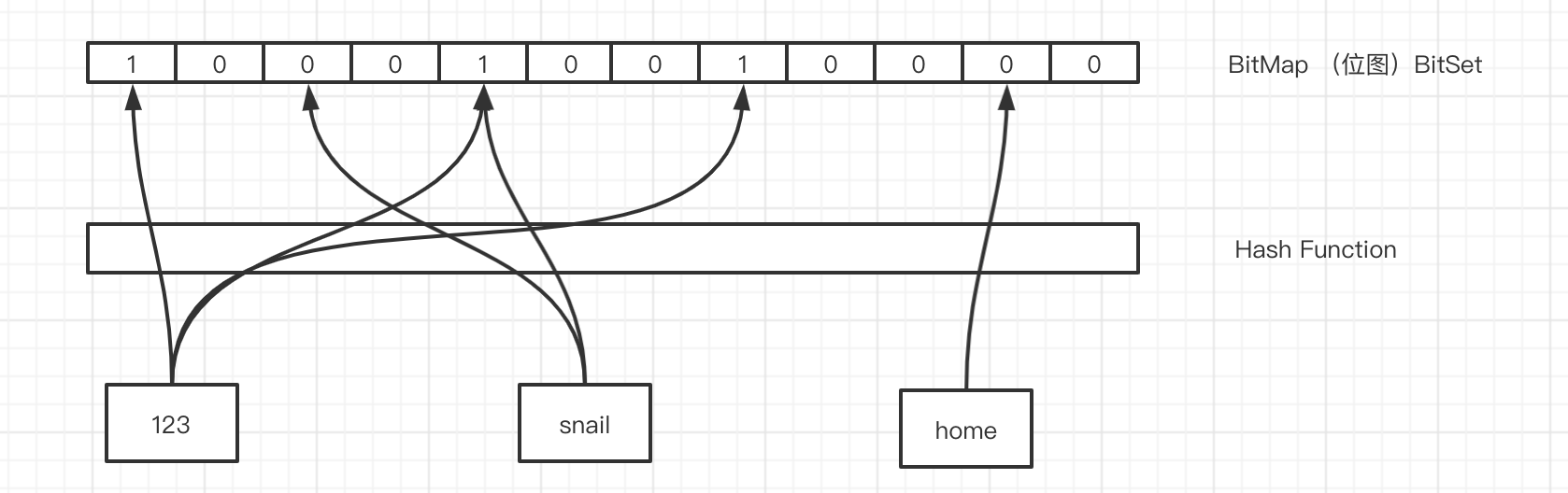
比如,这3个元素,我们经过哈希函数和位运算,得到了相应的下标。
哈希碰撞
这个时候,123和snail经过计算得到的哈希值是一样的,那么再经过位运算得到的 下标肯定是一样的,我们把这种情况叫做哈希冲突或者哈希碰撞。
如果发生了哈希碰撞,这个时候对于我们的容器存值肯定是有影响的,从数据结构和映射方法这两个角度来分析,我们可以通过哪些方式去降低哈希碰撞的概率呢?
第一种就是扩大维数组的长度或者说位图容量。因为我们的函数是分布均匀的,所以,位图容量越大,在同一个位置发生哈希碰撞的概率就越小。
是不是位图容量越大越好呢?不管存多少个元素,都创建一个几万亿大小的位图, 可以吗?当然不行,因为越大的位图容量,意味着越多的内存消耗,所以我们要创建一个合适大小的位图容量。
除了扩大位图容量,我们还有什么降低哈希碰撞概率的方法呢?
如果两个元素经过一次哈希计算,得到的相同下标的概率比较高,我可以不可以计算多次呢?原来我只用一个哈希函数,现在我对于每一个要存储的元素都用多个哈希函数计算,这样每次计算出来的下标都相同的概率就小得多了。
同样的,我们能不能引入很多个哈希函数呢?比如都计算100次,都可以吗?
当然也会有问题,第一个就是它会填满位图的更多空间,第二个是计算是需要消耗时间的。
所以总的来说,我们既要节省空间,又要很高的计算效率,就必须在位图容量和函数个数之间找到一个最佳的平衡。
布隆过滤器原理
布隆过滤器的工作原理:
首先,布隆过滤器的本质就是我们刚才分析的,一个位数组,和若干个哈希函数。
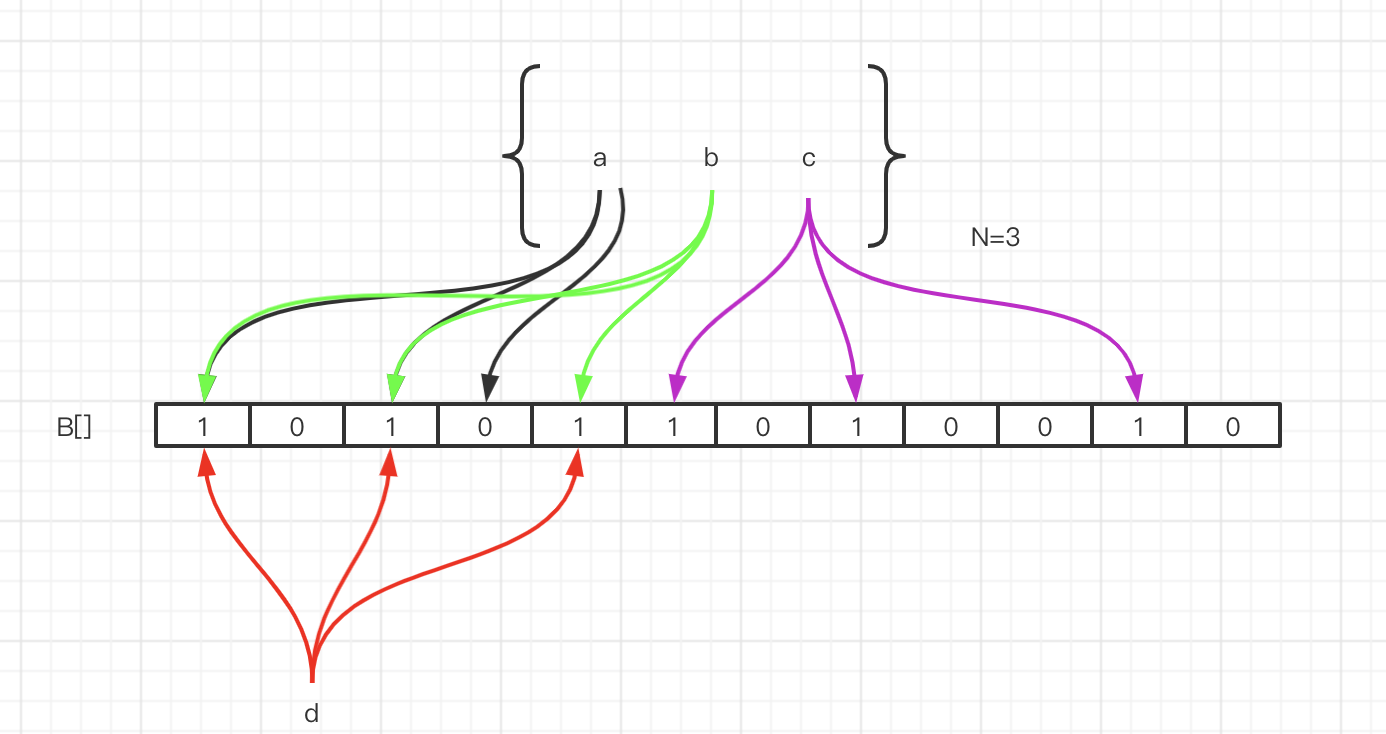
集合里面有3个元素,要把它存到布隆过滤器里面去,应该怎么做?首先是a元素, 这里我们用3次计算。b、c元素也一样。
元素已经存进去之后,现在我要来判断一个元素在这个容器里面是否存在,就要使用同样的三个函数进行计算。
比如d元素,我用第一个函数f1计算,发现这个位置上是1,没问题。第二个位置也是1,第三个位置也是1。
如果经过三次计算得到的下标位置值都是1,这种情况下,能不能确定d元素一定在这个容器里面呢?
实际上是不能的。比如这张图里面,这三个位置分别是把a,b,c存进去的时候置成1的,所以即使d元素之前没有存进去,也会得到三个1,判断返回true。
所以,这个是布隆过滤器的一个很重要的特性,因为哈希碰撞不可避免,所以它会存在一定的误判率。这种把本来不存在布隆过滤器中的元素误判为存在的情况,我们把它叫做假阳性(False Positive Probability, FPP) 。
布隆过滤器的特点:
从容器的角度来说:
1、如果布隆过滤器判断元素在集合中存在,不一定存在
2、如果布隆过滤器判断不存在,一定不存在
从元素的角度来说:
3、如果元素实际存在,布隆过滤器一定判断存在
4、如果元素实际不存在,布隆过滤器可能判断存在
利用,第二个特性,我们是不是就能解决持续从数据库查询不存在的值的问题?
Guava 的实现
谷歌的Guava里面就提供了一个现成的布隆过滤器。
<dependency>
<groupld>com.google.guava</groupld>
<artifactld>guava</artifactld>
<version>21.0</version>
</dependency>
创建布隆过滤器:
BloomFilter<String> bf = BloomFilter. create(Funnels.stringFunnel(Charsets.UTF_8), insertions);
布隆过滤器提供的存放元素的方法是put()。
布隆过滤器提供的判断元素是否存在的方法是mightContain()。
if (bf.mightContain(data)) (
if (sets.contains (data)) (
//判断存在实际存在的时候,命中
right++;
continue;
}
//判断存在却不存在的时候,错误
wrong++;
}
布隆过滤器把误判率默认设置为0.03,也可以在创建的时候指定。
public static <T> BloomFilter<T> create(Fuimel<? super T> fiinnel, long expectedlnsertions) {
return create(fimnel, expectedlnsertions, 0.03D);
}
位图的容量是基于元素个数和误判率计算出来的。
long nuniBits = optimalNumOfBits(expectedInsertions, fpp);
根据位数组的大小,我们进一步计算出了哈希函数的个数。
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
存储100万个元素只占用了 0.87M的内存,生成了 5个哈希函数。
布隆过滤器在项目中的使用
布隆过滤器的工作位置:
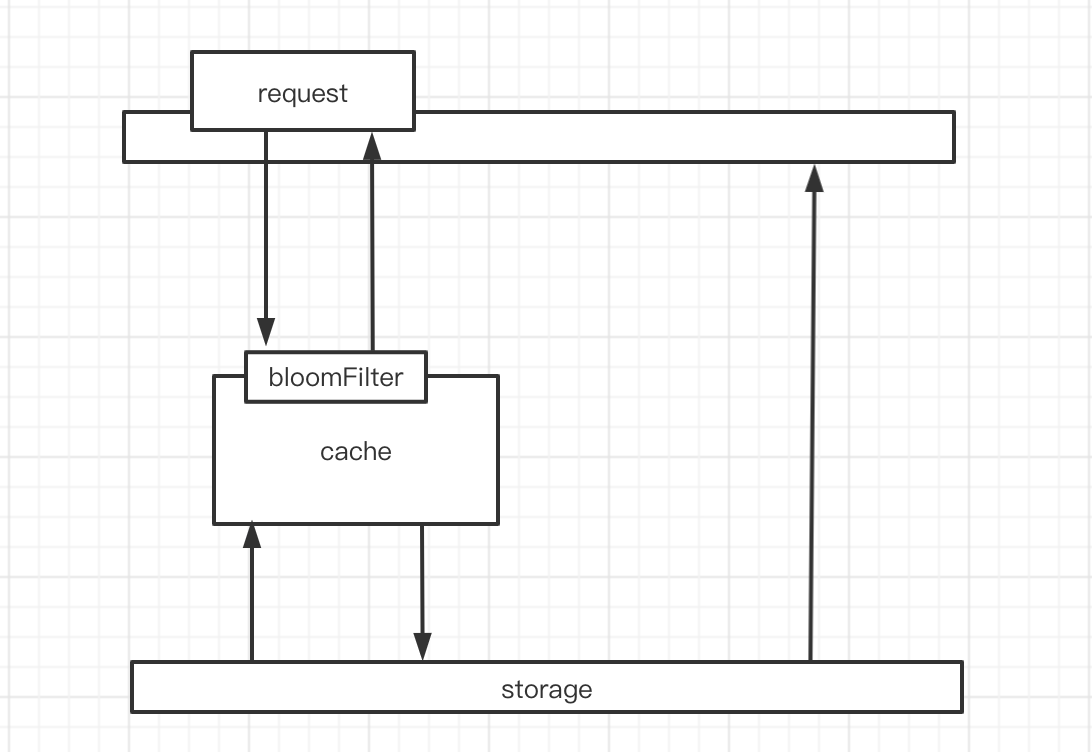
因为要判断数据库的值是否存在,所以第一步是加载数据库所有的数据。在去Redis査询之前,先在布隆过滤器査询,如果bf说没有,那数据库肯定没有,也不用去査了。 如果bf说有,才走之前的流程。
布隆过滤器的不足与变种
如果数据库删除了,布隆过滤器的数据也要删除。但是布隆过滤器里面没有提供删 除的方法。为什么布隆过滤器不提供删除的方法呢?或者说,如果删除了布隆过滤器的元素,会发生什么问题?
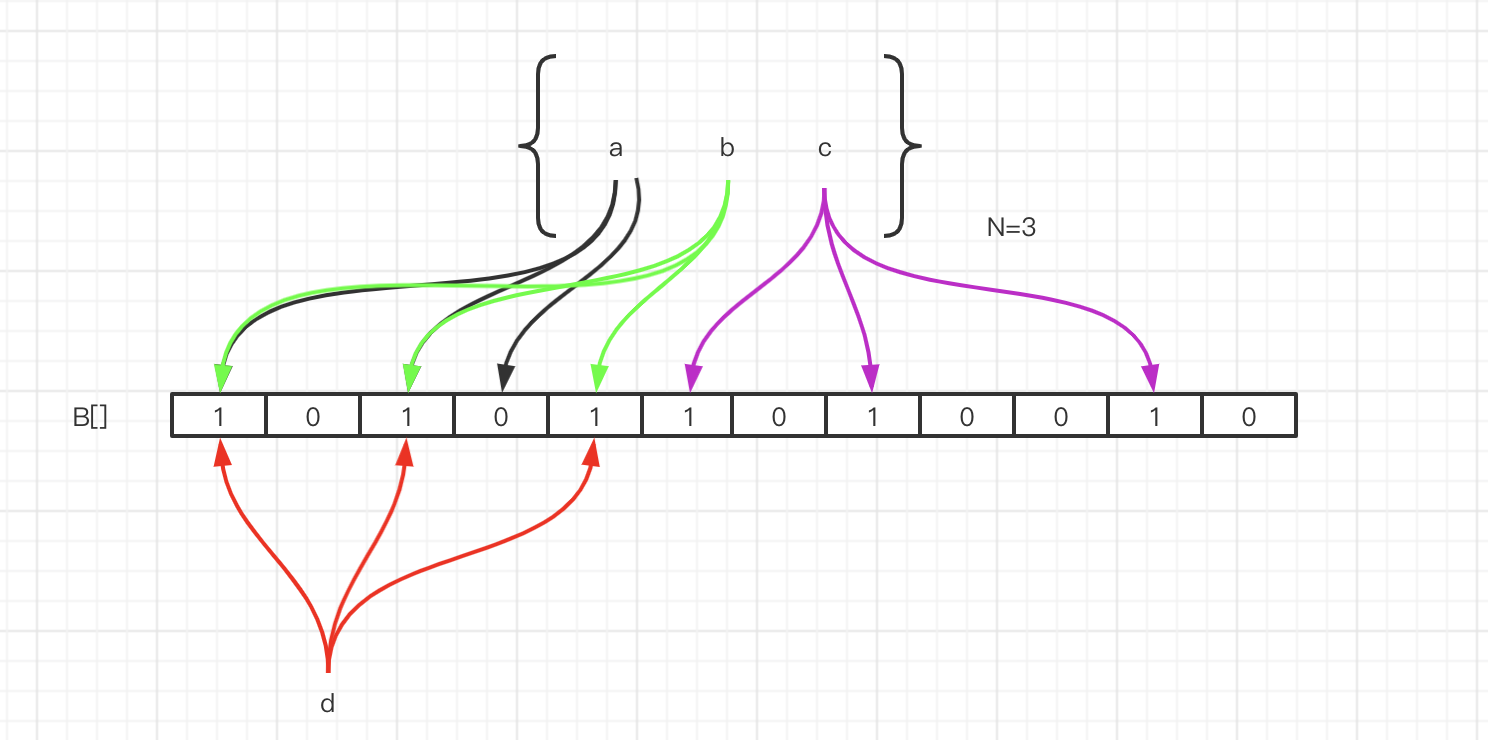
比如我们把a删除了,那个三个位置都要改成0。但是再来判断b元素是否存在的时候,因为有一个位置变成了0,所以b元素也判断不存在。就是因为存在哈希碰撞, 所以元素只能存入,不能删除。
那如果我们要实现删除的功能,怎么做呢?类似于HashMap的链地址法,我们可以在每个下标位置上增加一个计数器。比如这个位置命中了两次,计数器就是2。当删除 a元素的时候,先把计数器改成1。删除b元素的时候,计数器变成0,这个时候下标对应的位才置成0。
实际上在布隆过滤器提出来的几十年里面,出现了很多布隆过滤器的变种,这种通过计数器提供删除功能的bf就叫做Counting Bloom Filtero
布谷鸟过滤器
分布式环境的布隆过滤器?
https://github.com/redisson/redisson/wiki/目录
布隆过滤器的其他应用场景
如何在海量元素中快速判断一个元素是否存在。所以除了解决缓存穿透的问题之外,我们还有很多其他的用途。
比如爬数据的爬虫(爬过的url我们不需要重复爬,那么在几十亿的url里面,判断一个url是不是已经爬过了)
判断一个账号是不是spamer(我们的邮箱服务器,发送垃圾邮件的账号我们把它们叫做spamer)