本人原创,首发于开源中国。
大概和我不以程序员为职业有关吧,我本人是比较喜欢算法的那种,当然是比不了科班出身的。
比如我就写过很多版本的算术表达式解析器,优先级堆栈的;二叉树的;分治策略的;修正计算顺序的……
正则表达式两个我也写过两个,一个采用的回溯算法,另一个则是二叉树版本的,虽然这俩倒是都能用吧,但是对分组的处理(分组是采用递归调用的方法实现的,相当于另一个正则表达式)实在是不太好,这个缺点导致很多时候搜索的结果会遗漏很多,而二叉树版本的还有个缺点是选择操作“|”只能获得第一个匹配…………
就效果看,这俩都是残次品。
后来,我在vczh的博客里看到了他的一个科普贴子,在那里面,我才了解到还有有限自动机这种方法。
之后我花了不少时间去思考,因为总觉得这个方法太麻烦了,断断续续有2-3个月吧,想来想去也没想出什么更好的法子,最后还是觉得只有用有限自动机才合适。
不过多少我还是做了些修改的,倒不是为了效率,是为了减少打字量……
主要修改如下:
(1)不每个字符转移一次状态,而是尽可能的把连续的字符作为一个整体进行比对。
(2)不弄什么字母分组表,数据结构就使用指针链表,节省工作量
(3)“{a,b}”这种有次数限定的重复,vczh是采用复制节点实现的,我采用增加状态边来解决(效率会下降)
(4)分组命名,向前向后预查这些花哨而实用的功能,俺就丢了
那么,整体上看,正则表达式引擎的设计我就划分为如下几个步骤:
1)对规则字符串做预处理,主要是换行这类要使用转义符的字符,这个预处理可以把这些字符还原
2)将规则字符串进行划分,修正成操作符、操作数的列表形式
3)对这个列表进行处理,获得NFA状态转移图
4)将NFA状态转移图里的ε边消去,减少状态转移数
5)利用得到的状态转移图,对字符串进行匹配
第一步很容易解决,无非就是找到'\',然后将后跟't'、'n'、'r'等字符的修正为相应的制表、换行……
第二步也相对简单,无非是识别几个操作符:
'*'、'+'、'?'、'*?'、'+?'、'??'、'('、'(:'、')'、'|'、'['、']'、'{'、'}'
比较特殊的是:
因为把连续的字符看做一个整体,所以在后跟重复或者可选运算符时,要检查一下是否需要断开字符串;
'['后面要一直读取到前面不是'\'的']',期间不作分析,结果作为一个整体
'{'后面有'{a}'、'{a,}'、'{,a}'、'{a,b}'这几种形式,同样是读取为一个整体
还有一个隐藏的操作符,它的作用是将两个操作数连接起来,类似算术里的“*”,关于它另有介绍[*]
如此一来,列表里的成员记录的内容就会有好几种,python里这不算啥,C++里就麻烦一些,我采用的是struct和union来回嵌套+标志字节的办法来处理这个问题。
(如果使用正则表达式这一步非常轻松,可是如果用了就真成了笑话了)
[*]被隐藏了的“连接”运算符,比如“ab[cd]”这个字符串,分析后的两个元素“ab”和“[cd]”正是通过这个操作符连接的。这个隐藏运算符我是用后面的Operator类的一个补足函数来填充修复的,不然就得另外写一个函数了。
第三步,进行有限自动机的搭建操作
我们要构造一个有限自动机,而这个自动机是用一个表达式来构建的,很容易可以想到,我们完全可以把表达式耳的操作数看做一个小号的自动机(或者说是状态图),而操作符的效果是对状态图进行修饰,或者连接两个状态图,当我们执行完表达式解析后,就可以得到一个完整的表达式的状态图了。
像是算术表达式这种给定输入只有一个结果的,表示成树的形式就可以满足要求了,而正则表达式对给定输入会有多个结果(虽然通常我们只要第一个结果),也确实只能用图表示。
操作数有三种,连续字符;包含;分组提取比较。都用如下状态图表示:
 注意我把所有的操作都放在边上,状态节点处不做任何行为。
注意我把所有的操作都放在边上,状态节点处不做任何行为。
每一个操作数所对应的状态图,都各有唯一的进入节点和退出节点(我们不需要关系状态图内部的情况)
'?'操作符,也即是可选操作符,它的效果如下(从操作数修饰的来):
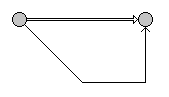 '??'的效果类似,但是ε边的优先级较高(图中靠上的边优先级高)
'??'的效果类似,但是ε边的优先级较高(图中靠上的边优先级高)
类似的,还有'*'、'*?':
 输入输出节点为新建节点,'*?'的ε边的优先级较高
输入输出节点为新建节点,'*?'的ε边的优先级较高
以及'+'、'+?':
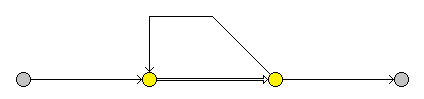 输入输出节点为新建节点,'+?'的ε边的优先级较高
输入输出节点为新建节点,'+?'的ε边的优先级较高
隐藏的“连接”操作符:
 左俩操作数1,右俩操作数2
左俩操作数1,右俩操作数2
选择操作符,"|":
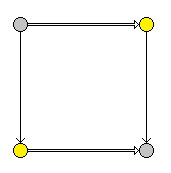 上面一排为操作数1,下面一排为操作数2
上面一排为操作数1,下面一排为操作数2
分组"( )":
 黑色分别表示报告分组的起止点的字符串位置
黑色分别表示报告分组的起止点的字符串位置
一般不分组的括号"(: )",这个完全没啥操作,不用修饰,直接返回操作数就好了
限定次数的操作符(是的,看做操作符)"{a,b}":
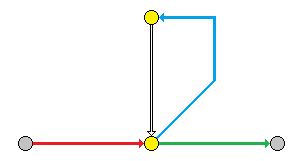 红色表示进入循环,蓝色累计次数,绿色退出循环
红色表示进入循环,蓝色累计次数,绿色退出循环
如此,我们就得到了生成操作数的方法,以及所有操作符的操作效果
结合这些,我们就可以通过分析表达式来生成一个完整的有限自动机了。
分析表达式的方法么,自然是很多的,算术表达式分析器稍微改改就能拿来分析之前得到的列表了,无非是新的运算符,新的运算函数(函数指针真是棒啊真是棒)、新的操作数而已,整体架构变化极小。
当然,我是用的我之前写的一个可定制的表达式解析器,那是一个模板类,支持一元运算符(前置、后置)、二元运算符(左结合、右结合)、括号(普通括号、后缀括号),只要把这些运算符和它们对应的处理函数注册进去就行了。(还可以注册操作数生成函数、操作符生成函数、销毁函数等一系列函数)
所以具体写法就不多说了,拿个算术表达式解析器慢慢改就是。
第四步,消去ε边
理论上,即使不消ε边也是没有问题的,顶天多转移两次状态,多花点时间罢了,对匹配的影响,嗯,不大。
不过出于效率,我们还是要消一下的。
只要在纸上写写画画几次,就能看出来了,消ε边的规则如下:
1)遍历状态图,找到一个ε边,设其起点为A,终点为B
2)如果A==B,也就是起点终点重合,这个ε边是坏边,删掉它
3)如果B只有ε边一个输入边,那么我们只需要将B的所有输出转移到A上,取代ε边的位置即可
4)如果A只有ε边一个输出边,那么我们只需要将所有指向A的边的目标都改成B并删掉ε边就行了
5)否则,我们就只好复制B的所有输出,插入A的ε边的位置(删掉ε边)
遍历状态图完成上述的操作后,ε边是消去了,但是还有大量的无用节点(没有输入边的节点)保留了下来,所以我们还要删掉这些节点。
注意在消去ε边之前要现在起点添加一个输入边(进入匹配),终点要添加一个输出边(匹配成功,指向NULL即可),以免在消ε边时将正常节点误删。
另外,我们在出列"(: )"是,只是添加了报告位置的输出边,那么现在,我们需要对这些边进行编号了,以方便讲报告的数据写入相应的分组里。(分组进行编号要在消去ε边之前!不然会因为边的复制出现错误)
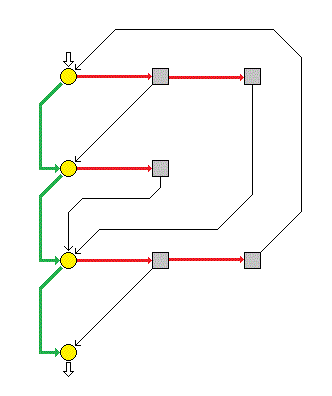
我不是使用列表来表示状态图的,那样实在是不够直观,不好理解,我使用的是梳状链表,分别有节点和路径两种类型,然后节点形成一个链表,每个节点下有一个路径的链表(表示以该节点为起点的路径),每个路径都包含着目标节点的指针(和条件、操作)。于是,不考虑目标路径的指针的话,整个结构就好像是参差不齐的梳子一样。
这样的好处是比较直观,利于插入删除节点和边,缺点是打字较多……,还有一个好处,就是保持了节点的相对位置——于是我们可以正确的对报告边进行编号,至于这个编号就比较简单了,堆栈也好,状态数组也好,实现起来都简单的很,不多说。
第五步,进行匹配
匹配么,有了有限自动机,反而容易多了,vczh的有限自动机是没有我另加的三个边(进入重复、累计重复、退出重复——这三个边是配合起来实现限定次数重复的)的,他只需要记录当前节点、当前匹配位置、分组数据即可,而我还需要记录重复堆栈和当前重复指示,效率无疑是低了些。
匹配的方法,相当简单。
首先,我们需要一个堆栈,堆栈的成员是上述的数据(当前节点、当前匹配位置、分组数据、重复堆栈和当前重复指示),我使用的是一个定长的struct,相对简单,但缺点是对分组数目和重复的嵌套次数都有限制。
先往堆栈里加入最初状态;随后进入循环。每一次循环,都从堆栈里取出一个成员,然后根据成员的当前节点下的路径,凡是能走通的都生成新的状态加入堆栈里。这个循环不断进行,直到堆栈清空(匹配失败),或者到达最后结束节点为止(我使用的就是NULL)。
如此,这个正则表达式引擎已经基本完成了。只要再做一下包装(比如我用一个类进行了封装,添加了一些基于基本匹配的进阶方法),就可以投入使用了。
总结
其实,整个表达式写下来,包括数据结构和各种函数等等等等,也不过不到1000行,20kb左右大小。
但是,不是这么计算的。
写正则表达式,我有了不少以前的积累:
使用了List(类似python的列表)、Graph(梳状链表)、BlockStack(块状数组堆栈)三个容器模板;
使用了Label(char*的封装,差不多等于C++的string)这个类;
使用了Operator(可定制表达式解析器类模板)来第二次分析表达式构建自动机;
而Operator使用了Cast类来实现映射,Cast类是使用RBT(红黑树)和Item(映射)类实现的……
使用了Environment(利用类的构造函数和全局变量模拟预处理函数)来进行数据的预处理和注册函数。
全部加起来,即使去掉无关部分,估计也要2000-3000行,50kb左右吧。
以前的积累真的救了我一命。