码字好辛苦的,这篇文章反反复复修改了好几天,如果荣幸被转载的话, 请注明来源 https://www.cnblogs.com/snow-man/p/10062394.html
用途,背景
--------Kafka--------
是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务(行为跟踪,日志收集等)。
默认通讯接口9092
-------RabbitMQ------
是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。本身支持很多的协议:AMQP,XMPP, SMTP, STOM它变的非常重量级,更适合于企业级的开发。同时实现了一个经纪人(Broker)构架,这意味着消息在发送给客户端时先在中心队列排队。对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持。
特点: 通过交换机(Exchange)实现消息的灵活路由。
默认通讯接口5672,webui端口15672
-------RocketMQ------
是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
特点:
1 亿级别消息堆积能力; 2 采用零拷贝的原理,顺序写盘,随机读; 3 底层通信框架采用Netty NIO; 4 NameServer代替Zookeeper,实现服务寻址和服务协调; 5 消息失败重试机制、消息可查询;经过多次双十一的考验
默认端口9876
集群对比
--------Kafka--------
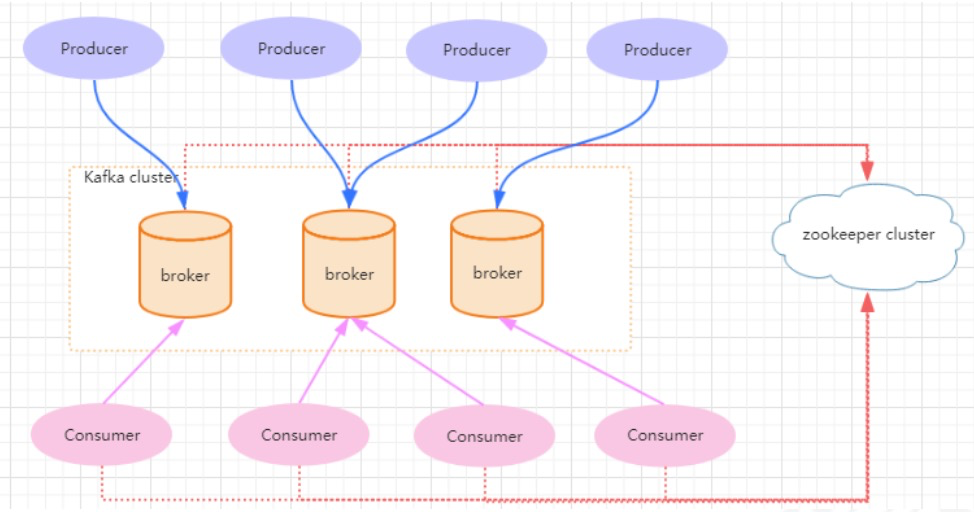
一个典型的kafka集群包含若干Producer(可以是应用节点产生的消息,也可以是通过Flume收集日志 产生的事件),若干个Broker(kafka支持水平扩展)、若干个Consumer Group,以及一个 zookeeper集群。
kafka通过zookeeper管理集群配置及服务协同。Producer使用push模式将消息发布到broker,consumer通过监听使用pull模式从broker订阅并消费消息。
多个broker协同工作,producer和consumer部署在各个业务逻辑中。三者通过zookeeper管理协调请 求和转发。这样就组成了一个高性能的分布式消息发布和订阅系统。
-------RabbitMQ------
因为 Erlang 天生具备分布式的特性, 所以 RabbitMQ 天然支持集群,不需要通过引入 ZK 或者数据库来实现数据同步。RabbitMQ 通过/var/lib/rabbitmq/.erlang.cookie 来验证身份
RabbitMQ 分两种节点
一种是磁盘节点(Disc Node),一种是内存节点(RAM Node)。
集群中至少需要一个磁盘节点用来持久化元数据,否则全部内存节点崩溃时,就无 从同步元数据。未指定类型的情况下,默认为磁盘节点。
RabbitMQ集群分两种:普通集群、镜像集群
普通集群模式:
不同的节点之间只会相互同步元数据,队列不同步,只在自己的broker中,普通集群模式不能保证队列的高可用性,因为队列内容不会复制。如果节点失效将导致相关队列不可用
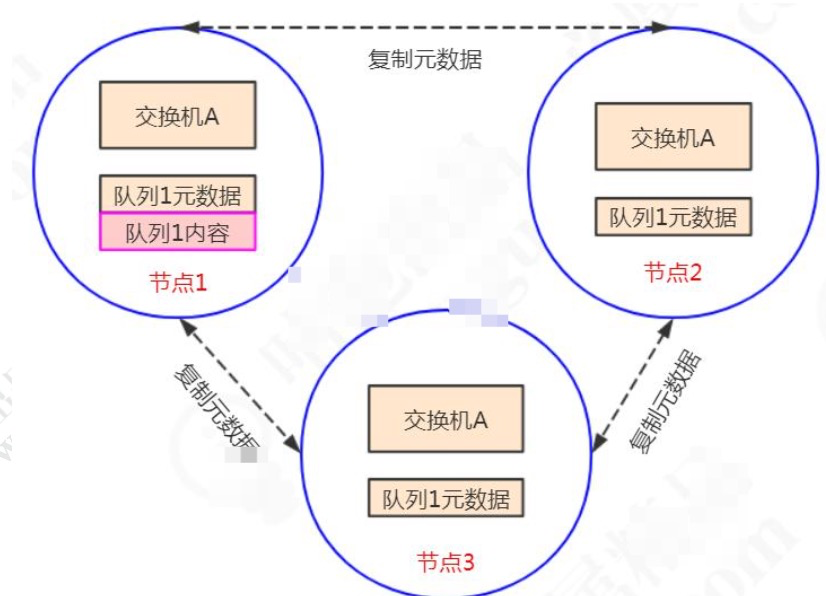
镜像队列模式:
消息内容会在镜像节点间同步,保证 100% 数据不丢失。在实际工作中也是用得最多的,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群模式。
mirror 镜像队列,目的是为了保证 rabbitMQ 数据的高可靠性解决方案,主要就是实现数据的同步,一般来讲是 2-3个节点实现数据同步。对于 100% 数据可靠性解决方案,一般是采用3个节点。

-------RocketMQ------
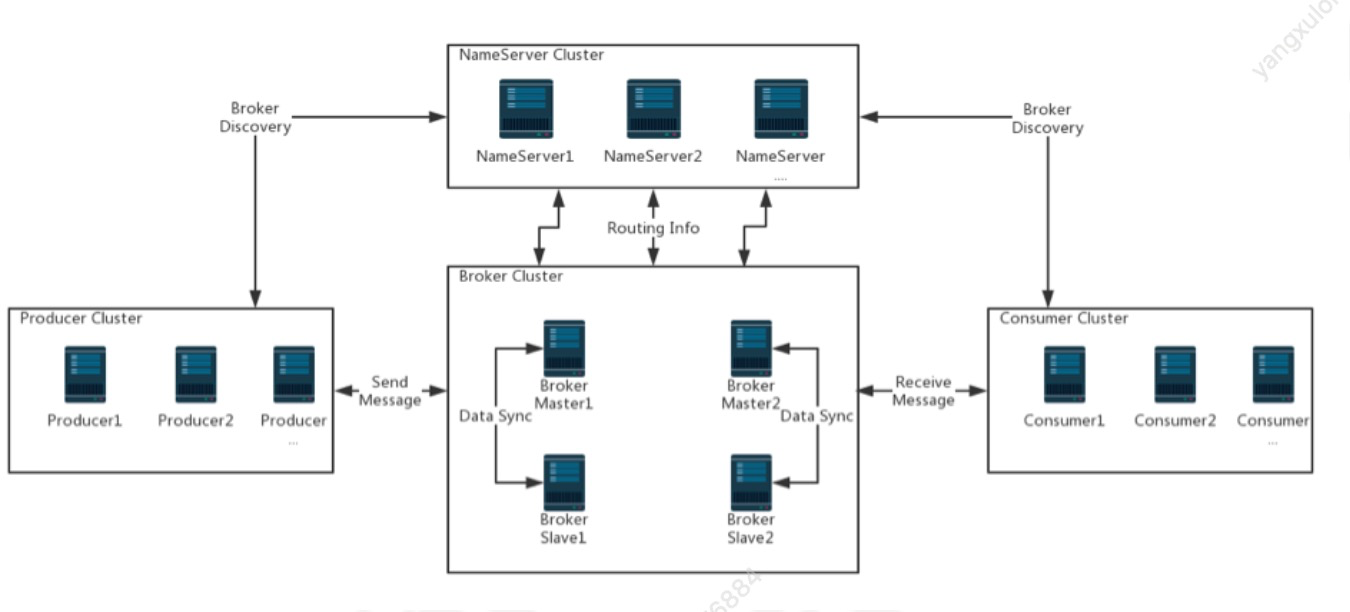
RocketMQ由四部分组成
1)、Name Server 可集群部署,节点之间无任何信息同步。提供轻量级的服务发现和路由
2)、Broker(消息中转角色,负责存储消息,转发消息) 部署相对复杂,Broker 分为Master 与Slave,一 个Master 可以对应多个Slave,但是一个Slave 只能对应一个Master,
Master 与Slave 的对应关系通过 指定相同的BrokerName,不同的BrokerId来定 义,BrokerId为0 表示Master,非0 表示Slave。 Master 也可以部署多个。
3)、Producer,生产者,拥有相同 Producer Group 的 Producer 组成一个集群, 与Name Server 集群 中的其中一个节点(随机选择)建立长连接,
定期从Name Server 取Topic 路由信息,并向提供Topic 服务的Master 建立长连接,且定时向Master 发送心跳。Producer 完全无状态,可集群部署。
4)、Consumer,消费者,接收消息进行消费的实例,拥有相同 Consumer Group 的 Consumer 组成 一个集群,与Name Server 集群中的其中一个节点(随机选择)建立长连接,
定期从Name Server 取 Topic 路由信息,并向提供Topic 服务的Master、Slave 建立长连接,且定时向Master、Slave 发送心跳。
Consumer既可以从Master 订阅消息,也可以从Slave 订阅消息,订阅规则由Broker 配置决定。
要使用rocketmq,至少需要启动两个进程,nameserver、broker,前者是各种topic注册中心,后者是真正的broker。
其他一些概念:
NameServer可以部署多个,相互之间独立,其他角色同时向多NameServer机器上报状态信息,从而达到热备份的目的。
NameServer本身是无状态的,也就是说NameServer中的Broker、Topic等状态信息不会持久存储,都是由各个角色定时上报并 存储到内存中的(NameServer支持配置参数的持久化,一般用不到)。
为何不用ZooKeeper?
ZooKeeper的功能很强大,包括自动Master选举等,RocketMQ的架构设计决定了它不需要进行Master选举, 用不到这些复杂的功能,只需要一个轻量级的元数据服务器就足够了。
值得注意的是,NameServer并没有提供类似Zookeeper的watcher机制, 而是采用了每30s心跳机制。
心跳机制
- 单个Broker跟所有Namesrv保持心跳请求,心跳间隔为30秒,心跳请求中包括当前Broker所有的Topic信息。Namesrv会反查Broer的心跳信息, 如果某个Broker在2分钟之内都没有心跳,则认为该Broker下线,调整Topic跟Broker的对应关系。但此时Namesrv不会主动通知Producer、Consumer有Broker宕机。
- Consumer跟Broker是长连接,会每隔30秒发心跳信息到Broker。Broker端每10秒检查一次当前存活的Consumer,若发现某个Consumer 2分钟内没有心跳, 就断开与该Consumer的连接,并且向该消费组的其他实例发送通知,触发该消费者集群的负载均衡(rebalance)。
- 生产者每30秒从Namesrv获取Topic跟Broker的映射关系,更新到本地内存中。再跟Topic涉及的所有Broker建立长连接,每隔30秒发一次心跳。 在Broker端也会每10秒扫描一次当前注册的Producer,如果发现某个Producer超过2分钟都没有发心跳,则断开连接.
原文链接:https://blog.csdn.net/javahongxi/article/details/84931747
RocketMQ天生对集群的支持非常友好
1)单Master
优点:除了配置简单没什么优点
缺点:不可靠,该机器重启或宕机,将导致整个服务不可用
2)多Master
优点:配置简单,性能最高
缺点:可能会有少量消息丢失(配置相关),单台机器重启或宕机期间,该机器下未被消费的消息在机 器恢复前不可订阅,影响消息实时性
3)多Master多Slave,每个Master配一个Slave,有多对Master-Slave,集群采用异步复制方式,主备有短暂消息延迟,毫秒级
优点:性能同多Master几乎一样,实时性高,主备间切换对应用透明,不需人工干预
缺点:Master宕机或磁盘损坏时会有少量消息丢失
4)多Master多Slave,每个Master配一个Slave,有多对Master-Slave,集群采用同步双写方式,主备都写成功,向应用返回成功
优点:服务可用性与数据可用性非常高
缺点:性能比异步集群略低,当前版本主宕备不能自动切换为主
Broker特点及分区容错、副本机制
--------Kafka--------
1. Broker 不维护数据消费状态,只是负责数据的顺序读写,功能单一,不需要创建对象及GC操作,效率高。
2. kafka各broker关系: 各broker之间关系平等, 只有具体topic下的partition才有主从关系,其中master节点负责client的读写,follower不负责备份(ISR机制)。
3. Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把 这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个 Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。【分区是为了性能,副本是为了容错】
4. kafka包括一个默认的topic: consumer__*, 默认是50个分区,分区时机是(分区位置= groupid.hascode()%50)记录每个ConsumerGroup的offset信息,这个之前是存储在zk中的。后来考虑的ZK性能问题,改村到kafka自己的topic中
partition 分区副本
kafka 一个Topic下分成若干个partition(partition数量不得超过broker数量),每个partition可以有若干个副本。
好处是便于数据横向扩展,提高相率,同时支持灾难恢复。 副本集中只有一个leader,若干个follower, leader负责数据的读写,follower只负责数据备份。
几个概念
leader副本:响应clients端读写请求的副本
follower副本:被动地备份leader副本中的数据,不能响应clients端读写请求。 ISR副本:(In Sync Relica)包含了leader副本和所有与leader副本保持同步的follower副本 LEO:即日志末端位移(log end offset),告诉producer,数据已经录入 HW:即上面提到的水位值。HW值不会大于LEO值。用来对应consumer--数据可以消费了,
leader分区中 HW~LEO 之间的的表示leader已经存储,但是还没有同步到follower
producer写入流程大体如下:
1. producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader 2. producer 将消息发送给该 leader 3. leader 将消息写入本地 log 4. followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK 5. leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
ISR必须满足如下条件:
leader leo与follower leo同步时间不能太长replica.lag.time.max.min,如果该follower在此时间间隔内一直没有追 上过leader的所有消息,则该follower就会被剔除isr列表
副本Leader选举
当partition leader宕机时,zk会启动Leader选举
a) 优先从isr列表中选出第一个作为leader副本,这个叫优先副本,理想情况下有限副本就是该分区的leader副本
b) 如果isr列表为空,则查看该topic的unclean.leader.election.enable配置。
为true则代表允许选用非isr列表的副本作为leader,那么此时就意味着数据可能丢失,为false的话,则表示不允许,直接抛出NoReplicaOnlineException异常,造成leader副本选举失败。
c) 如果上述配置为true,则从其他副本中选出一个作为leader副本,并且isr列表只包含该leader 副本。一旦选举成功,则将选举后的leader和isr和其他副本信息写入到该分区的对应的zk路径上。
-------RabbitMQ------
消息从交换机路由到队列如果保证可靠性。
有两种方式处理交换机无法路由队列的问题,一种就是让服务端重发给生产者,一种是让 交换机路由到另一个备份的交换机。
第一种方式是消息回发,添加ReturnListener,同时Mandatory=false.
channel.addReturnListener(new ReturnListener() { public void handleReturn(int replyCode, String replyText, String exchange, String routingKey, AMQP.BasicProperties properties, byte[] body) throws IOException { System.out.println("=========监听器收到了无法路由,被返回的消息============"); } }); // 第三个参数是设置的mandatory,如果mandatory是false,消息也会被直接丢弃 channel.basicPublish("","gupaodirect",true, properties,"只为更好的你".getBytes());
第二种方式:
消息路由到备份交换机的方式:在创建交换机的时候,从属性中指定备份交换机。
Map<String,Object> arguments = new HashMap<String,Object>(); arguments.put("alternate-exchange","ALTERNATE_EXCHANGE"); // 指定交换机的备份交换机 channel.exchangeDeclare("TEST_EXCHANGE","topic", false, false, false, arguments);
-------RocketMQ------
消息类型
Broker上存Topic信息,Topic由多个队列组成,队列会平均分散在多个Broker上。Producer的发送机制保证消息尽量平均分布到 所有队列中,最终效果就是所有消息都平均落在每个Broker上。
1.普通消息
2.有序消息
有序消息就是按照一定的先后顺序的消息类型。
- 全局有序消息:只有一个队列一个消费者,效率受限
- 局部有序消息:配置算法,让所有相关消息进入同一个队列。
3.延时消息
延时消息,简单来说就是当 producer 将消息发送到 broker 后,会延时一定时间后才投递给 consumer 进行消费。
消息分发策略
--------Kafka--------
消息是kafka中最基本的数据单元,在kafka中,一条消息由key、value两部分构成,
在发送一条消息时,我们可以指定这个key,那么producer会根据key和partition机制来判断当前这条消息应该发送并存储到哪个partition中。
我们可以根据需要进行扩展producer的partition机制。
一个topic下多个partition对应consumer group的分配策略包括三种
1. RangeAssignor(范围分区):
分区按照序号进行排序,消费者按照字 母顺序进行排序
2. RoundRobinAssignor(轮询分区):
轮询分区策略是把所有partition和所有consumer线程都列出来,然后按照hashcode进行排序。最后通过轮询算法分配partition给消费线程
3. StrickyAssignor 分配策略
粘性策略的目的是两个:分区的分配尽可能的均匀,分区的分配尽可能和上次分配保持相同
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
1. 指定了 patition,则直接使用; 2. 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition 3. patition 和 key 都未指定,使用轮询选出一个 patition。
什么时候会引起kafka consumer的rebalance
1. 同一个consumer group内新增了消费者
2. 消费者离开当前所属的consumer group,比如主动停机或者宕机
3. topic新增了分区(也就是分区数量发生了变化)
小结:
消费者和分区的绑定关系是固定的,除非其他原因引起的Rebalance操作, 这样最大的好处是不需要考虑leader选举的情况,更不用开率并发的情况,一切为了效率。
-------RabbitMQ------
除了AMQP 之外,RabbitMQ 支持多种协议,STOMP、MQTT、HTTP and WebSockets。
特有组件,VHost,Exchange,Channel
VHost: VHOST 除了可以提高硬件资源的利用率之外,还可以实现资源的隔离和权限的控制,它的作用类似于编程语言中的 namespace 和 package,不同的 VHOST 中可以有 同名的 Exchange 和 Queue,它们是完全透明的。 Exchange: 交换机是一个绑定列表,用来查找匹配的绑定关系。队列使用绑定键(Binding Key)跟交换机建立绑定关系。 生产者发送的消息需要携带路由键(Routing Key),
交换机收到消息时会根据它保存的绑定列表,决定将消息路由到哪些与它绑定的队列上
Channel:
AMQP 里面引入了 Channel 的概念,它是一个虚拟的连接。我们就可以在保持的 TCP 长连接里面去创建和释放 Channel,大大了减少了资源消耗.
Queue:
队列是真正用来存储消息的,是一个独立运行的进程,有自己的数据库(Mnesia)。
路由方式有三种:Direct,Topic,Fanout
Direct : Exchange+bingKey 精确绑定 Topic: Exchange+bingKey(绑定键中使用通配符) Fanout 只需要Exchange,不需要bingKey
-------RocketMQ------
消息过滤:
在 RocketMQ 中消费者是可以按照 Tag 对消息进行过滤。对于消息分类,我们可以选择创建多个 Topic 来区分,也可以选择在同一个 Topic 下创建多个 tag 来区分。这两种方式都是可行的,但是一般情况下,不同的 Topic 之间的消息是没有什么必然联系的,使用 tag 来区分同一个 Topic 下相互关联的消息则更加合适一些。
消息重试:
概念:就是当消费者消费消息失败后,broker 会重新投递该消息,直到消费成功,消息重试只针对集群消费模式,广播消费没有消息重试的特性。如果消费重试一直失败,最终消息会进入死信队列,我们还需要对死信队列做单独的补偿机制。
消费重试来源:
返回 ConsumeConcurrentlyStatus.RECONSUME_LATER 返回 null 抛出异常
Producer => Broker可靠性投递
--------Kafka--------
kafka对于消息的发送,可以支持同步和异步。
从本质上来说,kafka都是采用异步的方式来发送消息到broker,但是kafka并不是每次发送消息都会直接发送到broker上,而是把消息放到了一个发送队列中,然后通过一个后台线程不断从队列取出消息进行发送,发送成功后会触发callback。
kafka客户端会积累一定量的消息统一组装成一个批量消息发送出 去,触发条件是前面提到的batch.size和linger.ms
batch.size和linger.ms这两个参数是kafka性能优化的关键参数
生产者发送消息的可靠性
也就是我要保证我这个消息一定是到了broker并且完成了多副本的持久化,配置项为request.required.acks,如:properties.put("request.required.acks","-1");。
它有几个可选项
1: 生产者把消息发送到leader副本,leader副本在成功写入到本地日志之后就告诉生产者消息提交成功,但是如果isr集合中的follower副本还没来得及同步leader副本的消息, leader挂了,就会造成消息丢失。
-1 :消息不仅仅写入到leader副本,并且被ISR集合中所有副本同步完成之后才告诉生产者已 经提交成功,这个时候即使leader副本挂了也不会造成数据丢失。
0:表示producer不需要等待broker的消息确认。这个选项时延最小但同时风险最大(因为 当server宕机时,数据将会丢失)。
Kafka delivery guarantee(message传送保证):
(1)At most once消息可能会丢,绝对不会重复传输;
(2)At least once 消息绝对不会丢,但是可能会重复传输;
(3)Exactly once每条信息肯定会被传输一次且仅传输一次,这是用户想要的。
说明:当 producer 向 broker 发送消息时,一旦这条消息被 commit,由于 replication 的存在,它就不会丢。但是如果 producer 发送数据给 broker 后,遇到网络问题而造成通信中断,那 Producer 就无法判断该条消息是否已经 commit。虽然 Kafka 无法确定网络故障期间发生了什么,但是 producer 可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了 Exactly once,但目前还并未实现。所以目前默认情况下一条消息从 producer 到 broker 是确保了 At least once,可通过设置 producer 异步发送实现At most once。
-------RabbitMQ------
整个RabbitMQ的架构如下

在Producer发送消息到Broker整个流程中,Broker确认机制有两种。第一种是 Transaction(事务)模式,第二种 Confirm(确认)模式。
1. 事务机制:
我们通过一个 channel.txSelect()开启事务了,发送成功之后 channel.txCommit();否则使用channel.txRollback()
spring boot中设置rabbitTemplate.setChannelTransacted(true);
try {
channel.txSelect();
channel.basicPublish("", QUEUE_NAME, null, (msg).getBytes());
channel.txCommit();
System.out.println("消息发送成功");
} catch (Exception e) {
channel.txRollback();
System.out.println("消息已经回滚");
}
缺点:它是阻塞的,一条消息没有发送完毕,不能发送下一条消息,它会榨干 RabbitMQ 服务器的性能。所以不建 议大家在生产环境使用。
2. 确认(Confirm)模式
有三种
1. 是普通确认模式。 channel.confirmSelect() ,缺点:发送 1 条确认 1 条
2. 批量确认模式:channel.waitForConfirmsOrDie();
3. 异步确认: 添加ConfirmListener , channel.addConfirmListener(new ConfirmListener())
demo:
channel.addConfirmListener(new ConfirmListener() {
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("Broker未确认消息,标识:" + deliveryTag);
if (multiple) {
// headSet表示后面参数之前的所有元素,全部删除
confirmSet.headSet(deliveryTag + 1L).clear();
} else {
confirmSet.remove(deliveryTag);
}
// 这里添加重发的方法
}
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
// 如果true表示批量执行了deliveryTag这个值以前(小于deliveryTag的)的所有消息,如果为false的话表示单条确认
System.out.println(String.format("Broker已确认消息,标识:%d,多个消息:%b", deliveryTag, multiple));
if (multiple) {
// headSet表示后面参数之前的所有元素,全部删除
confirmSet.headSet(deliveryTag + 1L).clear();
} else {
// 只移除一个元素
confirmSet.remove(deliveryTag);
}
System.out.println("未确认的消息:"+confirmSet);
}
});
-------RocketMQ------
SendResult中,有一个sendStatus状态,表示消息的发送状态。一共有四种状态
1. FLUSH_DISK_TIMEOUT : 表示没有在规定时间内完成刷盘(需要Broker 的刷盘策Ill创立设置成 SYNC_FLUSH 才会报这个错误) 。
2. FLUSH_SLAVE_TIMEOUT :表示在主备方式下,并且Broker 被设置成SYNC_MASTER 方式,没有 在设定时间内完成主从同步。
3. SLAVE_NOT_AVAILABLE : 这个状态产生的场景和FLUSH_SLAVE_TIMEOUT 类似, 表示在主备方 式下,并且Broker 被设置成SYNC_MASTER ,但是没有找到被配置成Slave 的Broker 。
4. SEND OK :表示发送成功。
RocketMQ消息支持的模式
1.NormalProducer(普通) /消息同步发送
普通消息的发送和接收在前面已经演示过了,在上面的案例中是基于同步消息发送模式。也就是说消息 发送出去后,producer会等到broker回应后才能继续发送下一个消息
2.消息异步发送
MQ 的异步发送,需要用户实现异步发送回调接口(SendCallback)。
3.OneWay
单向(Oneway)发送特点为发送方只负责发送消息,不等待服务器回应且没有回调函数触发,即只发送请求不等待应答.效率最高
半消息(HalfMessage):
指的是发送方已经将消息发送给MQ服务器,但是服务器端未收到生产者对该消息的二次确认,此时消息就会被标记成 "暂不能投递状态" ,处于该状态的消息即
半消息消息回查(MessageStatusCheck):
由于网络闪断,生产者应用重启等原因,导致某条事务消息的二次确认丢失。MQ服务器通过扫描发现某条消息长时间处于 "半消息" 时,需要主动向消息生产者询问该消息的最终状态(Commit还是Rollback),该过程就是消息回查。
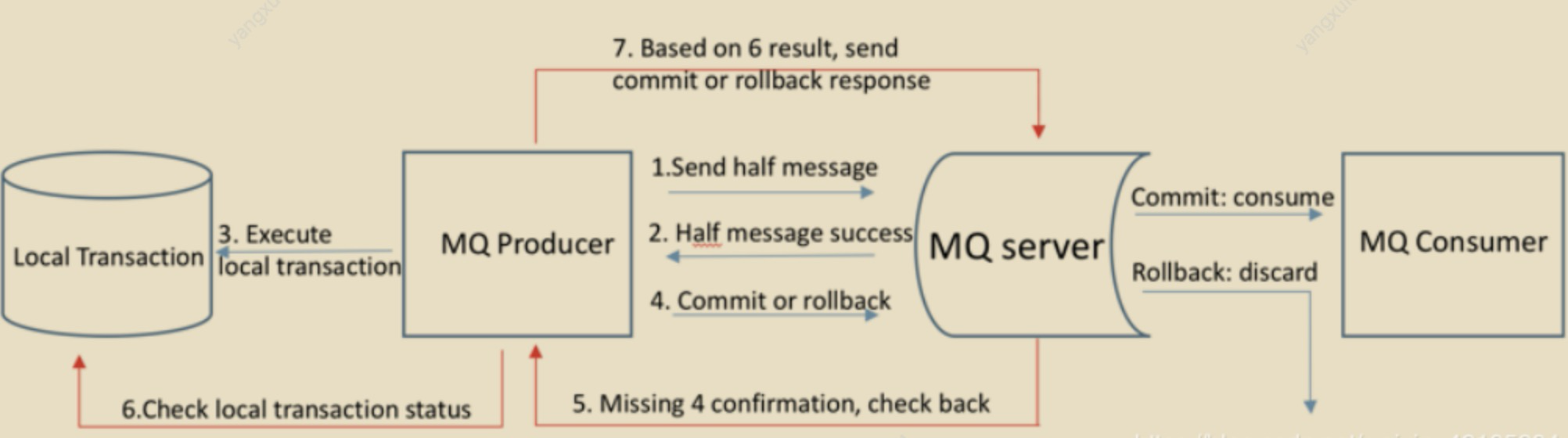
RocketMQ事务消息的三种返回状态
1. ROLLBACK_MESSAGE:回滚事务
2. COMMIT_MESSAGE: 提交事务
3. UNKNOW: broker会定时的回查Producer消息状态,直到彻底成功或失败。
当executeLocalTransaction方法返回ROLLBACK_MESSAGE时,表示直接回滚事务,当返回 COMMIT_MESSAGE提交事务
当返回UNKNOW时,Broker会在一段时间之后回查checkLocalTransaction,根据 checkLocalTransaction返回状态执行事务的操作(回滚或提交),
RocketMQ消息的事务架构设计
1.生产者执行本地事务,修改订单支付状态,并且提交事务
2.生产者发送事务消息到broker上,消息发送到broker上在没有确认之前,消息对于consumer是不可见状态
3.生产者确认事务消息,使得发送到broker上的事务消息对于消费者可见
4.消费者获取到消息进行消费,消费完之后执行ack进行确认
5.这里可能会存在一个问题,生产者本地事务成功后,发送事务确认消息到broker上失败了怎么办?这个时候意味着消费者无法正常消费到这个消息。所以RocketMQ提供了消息回查机制,如果 事务消息一直处于中间状态,broker会发起重试去查询broker上这个事务的处理状态。一旦发现事务处理成功,则把当前这条消息设置为可见。
Broker => Consumer 可靠性消费
--------Kafka--------
consumer group中所有consumer平均消费同一个topic下的消息,并且每个consumer只能消费一个分区。
coordinator(负载最小的broker)来执行对于consumer group的管理(Rebalance),以及确定整个consumer group的使用的分区策略
(每个消费者可以有自己的分区策略,但最终策略呦coordinator确定)
enable.auto.commit:默认为true,也就是自动提交offset,自动提交是批量执行的,但会带来重复提交或者消息丢失的问题,
对于高可靠性要求的程序,要使用手动提交。 对于高可靠要求的应用来说,宁愿重复消费也不应该因为消费异常而导致消息丢失
Properties props = new Properties(); props.put("bootstrap.servers", "xxxxxx");//服务器ip:端口号,集群用逗号分隔 props.put("group.id", "test"); //取消自动回复 props.put("enable.auto.commit", "false"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("itsm-test")); //消费 while(true){ ConsumerRecords<String, String> records = consumer.poll(100); if (records.count() > 0) { for (ConsumerRecord<String, String> record : records) { String message = record.value(); System.out.println("从kafka接收到的消息是:" + message); } } //同步或者异步提交 consumer.commitSync() //异步 //consumer.commitAsync()
auto.offset.reset:这个参数是针对新的groupid中的消费者而言的,
auto.offset.reset=latest情况下,新的消费者将会从其他消费者最后消费的offset处开始消费Topic下的消息 auto.offset.reset= earliest情况下,新的消费者会从该topic最早的消息开始消费 auto.offset.reset=none情况下,新的消费者加入以后,由于之前不存在offset,则会直接抛出异常。
-------RabbitMQ------
RabbitMQ 提供了消费者的消息确认机制(message acknowledgement),消费 者可以自动或者手动地发送 ACK 给服务端。
消费者在订阅队列时,可以指定 autoAck 参数,当 autoAck 等于 false 时,RabbitMQ 会等待消费者显式地回复确认信号后才从队列中移去消息。
设置:
factory.setAcknowledgeMode(AcknowledgeMode.MANUAL);
或者在spring 配置文件中设置
spring.rabbitmq.listener.direct.acknowledge-mode=manual spring.rabbitmq.listener.simple.acknowledge-mode=manual
akg返回值有三种
NONE:自动 ACK MANUAL: 手动 ACK
AUTO:如果方法未抛出异常,则发送 ack。
当抛出 AmqpRejectAndDontRequeueException 异常的时候,则消息会被拒绝且不重新入队。 当抛出 ImmediateAcknowledgeAmqpException 异常,则消费者会发送 ACK。 其他的异常,则消息会被拒绝,且 requeue = true 会重新入队。
其他:
生产者如何确认消息已经被确认:
1) 消费者收到消息,处理完毕后,调用生产者的 API(思考:是否破坏解耦?)
2) 消费者收到消息,处理完毕后,发送一条响应消息给生产者
-------RocketMQ------
RocketMQ提供了两种消息消费模型,一种是pull主动拉去,另一种是push,被动接收。但实际上 RocketMQ都是pull模式,只是push在pull模式上做了一层封装,也就是pull到消息以后触发业务消费 者注册到这里的callback. RocketMQ是基于长轮训来实现消息的pull。
存储方式对比
从主流的几种MQ消息队列采用的存储方式来看,主要会有三种
-
分布式KV存储,比如ActiveMQ中采用的levelDB、Redis, 这种存储方式对于消息读写能力要求不高的情况下可以使用
-
文件系统存储,常见的比如kafka、RocketMQ、RabbitMQ都是采用消息刷盘到所部署的机器上的文件系统来做持久化,这种方案适合对于有高吞吐量要求的消息中间件,因为消息刷盘是一种高效率,高可靠、高性能的持久化方式,除非磁盘出现故障,否则一般是不会出现无法持久化的问题
-
关系型数据库,比如ActiveMQ可以采用mysql作为消息存储,关系型数据库在单表数据量达到千 万级的情况下IO性能会出现瓶颈,所以ActiveMQ并不适合于高吞吐量的消息队列场景。
总的来说,对于存储效率,文件系统要优于分布式KV存储,分布式KV存储要优于关系型数据库
--------Kafka--------
Topic的多个partition在物理磁盘上的保存路径为/tmp/kafka-logs/topic_partition,kafka是通过分段的方式将Log分为多个LogSegment,LogSegment是一个逻辑上的概念,一个 LogSegment对应磁盘上的一个日志文件和一个索引文件,其中日志文件是用来记录消息的。
索引文件是稀疏索引(索引项中只对应主文件中的部分记录),用来保存一段index的区间。
一个消息的查找算法:
1. 根据offset的值,查找segment段中的index索引文件。由于索引文件命名是以上一个文件的最后 一个offset进行命名的,所以,使用二分查找算法能够根据offset快速定位到指定的索引文件。 2. 找到索引文件后,根据offset进行定位,找到索引文件中的符合范围的索引。(kafka采用稀疏索 引的方式来提高查找性能) 3. 得到position以后,再到对应的log文件中,从position出开始查找offset对应的消息,将每条消息 的offset与目标offset进行比较,直到找到消息
因为Kafka是使用文件存储,采用的是顺序写顺序读,针对这种情况,kafka的优化方案包括:
零拷贝:
在Linux中,是通过sendfile系 统调用来完成的。Java提供了访问这个系统调用的方法:FileChannel.transferTo API
页缓存:
Kafka中大量使用了页缓存, 这是Kafka实现高吞吐的重要因素之一 。
包括同步刷盘及间断性强制刷盘(fsync), 可以通过 log.flush.interval.messages 和 log.flush.interval.ms 参数来控制。
同步刷盘能够保证消息的可靠性,避免因为宕机导致页缓存数据还未完成同步时造成的数据丢失。但是实际使用上,我们没必要去考虑这样的因素以及这种问题带来的损失,消息可靠性可以由多副本来解决,同步刷盘会带来性能的影响。 刷盘的操作由操作系统去完成即可

-------RabbitMQ------
不管是持久化的消息还是非持久化的消息都可以被写入到磁盘。持久化的消息在到达队列时就被写入到磁盘,并且如果可以,持久化的消息也会在内存中保存一个备份,这样就可以提高一定的性能,当内存吃紧的时候会从内存中清除。非持久化的消息一般只保存在内存中,在内存吃紧的时候会被换入到磁盘中,以节省内存空间。这两种类型的消息的落盘处理都在RabbitMQ的“持久层”中完成。
RabbitMQ的持久层只是一个逻辑上的概念,实际包含两个部分:
- 队列索引(rabbit_queue_index):负责维护队列中落盘消息的信息,包括消息的存储地点、是否己被交付给消费者、是否己被消费者ack等。 每个队列都有与之对应的一个rabbit_queue_index
- 消息存储(rabbit_msg_store):以键值对的形式存储消息,它被所有vhost中的队列共享,在每个vhost中有且只有一个。rabbit_msg_store具体还可以分为 msg_store_persistent和msg_store_transient,msg_store_persistent负责持久化消息的持久化,重启后消息不会丢失;msg_store_transient负责 非持久化消息的持久化,重启后消息会丢失。
-------RocketMQ------
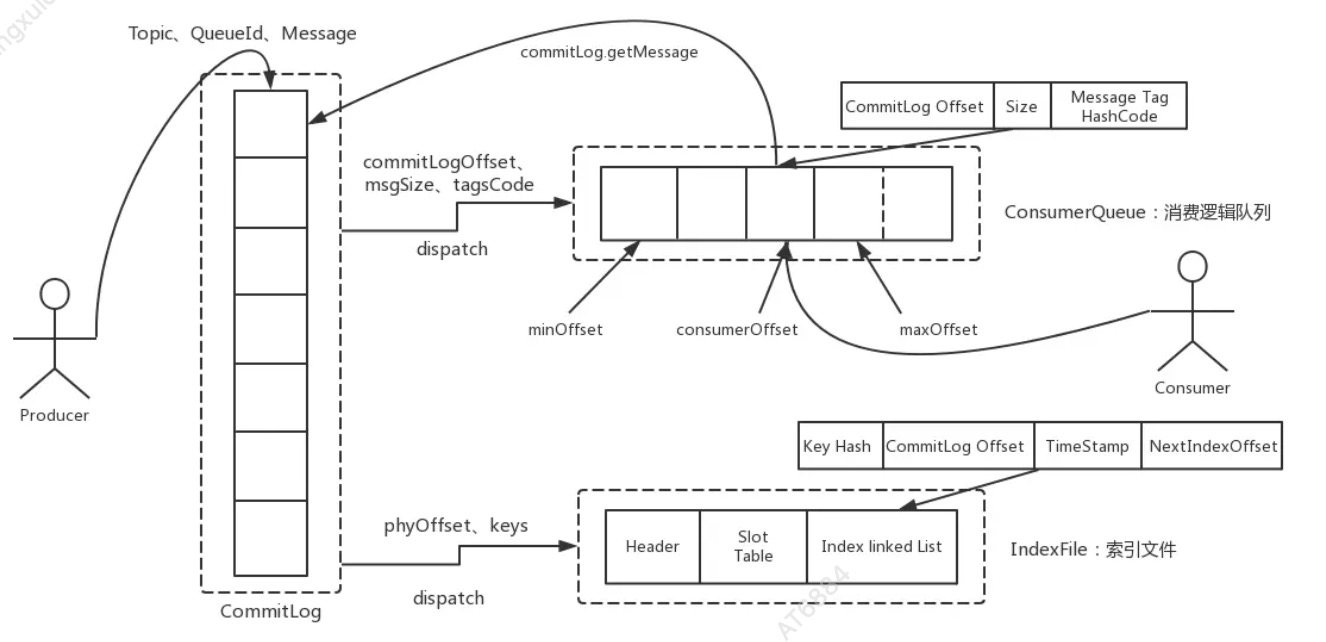
RocketMQ就是采用文件系统的方式来存储消息,消息的存储是由ConsumeQueue和CommitLog配合完成的。
CommitLog
CommitLog是用来存放消息的物理文件,有点类似于数 据库的索引文件,每个broker上的commitLog本当前机器上的所有 consumerQueue共享,不做任何的区分。
CommitLog中的文件默认大小为1G,可以动态配置; 当一个文件写满以后,会生成一个新的 commitlog文件。所有的Topic数据是顺序写入在CommitLog文件中的。
文件名的长度为20位,左边补0,剩余未起始偏移量,比如00000000000000000000 表示第一个文件, 文件大小为102410241024,当第一个文件写满之后,生成第二个文件
ConsumeQueue
consumeQueue表示消息消费的逻辑队列,这里面包含MessageQueue在commitlog中的其实物理位 置偏移量offset,消息实体内容的大小和Message Tag的hash值。
对于实际物理存储来说, consumeQueue对应每个topic和queueid下的文件,每个consumeQueue类型的文件也是有大小,每个文件默认大小约为600W个字节,如果文件满了后会也会生成一个新的文件
- RocketMQ的高性能在于顺序写盘(CommitLog)、零拷贝和跳跃读(尽量命中PageCache),高可靠性在于刷盘和Master/Slave,
- 另外NameServer 全部挂掉不影响已经运行的Broker,Producer,Consumer。
- 发送消息负载均衡,且发送消息线程安全(可满足多个实例死循环发消息),集群消费模式下消费者端负载均衡,这些特性加上上述的高性能读写, 共同造就了RocketMQ的高并发读写能力。
- 刷盘和主从同步均为异步(默认)时,broker进程挂掉(例如重启),消息依然不会丢失,因为broker shutdown时会执行persist。 当物理机器宕机时,才有消息丢失的风险。
- 另外,master挂掉后,消费者从slave消费消息,但slave不能写消息。
与Kafka消息队列的比较
kafka中Topic的Partition数量过多,队列文件会过多,那么会给磁盘的IO读写造成比较大的压力,也就造成了性能瓶颈。所以RocketMQ进行了优化,消息主题统一存储在CommitLog中。
当然,这种设计并不是银弹,它也有它的优缺点
优点在于:由于消息主题都是通过CommitLog来进行读写,ConsumerQueue中只存储很少的数据, 所以队列更加轻量化。对于磁盘的访问是串行化从而避免了磁盘的竞争
缺点在于:消息写入磁盘虽然是基于顺序写,但是读的过程确是随机的。读取一条消息会先读取 ConsumeQueue,再读CommitLog,会降低消息读的效率。
过期方式,消除策略对比
--------Kafka--------
日志的清理策略有两个
1. 根据消息的保留时间,当消息在kafka中保存的时间超过了指定的时间,就会触发清理过程
2. 根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阀值,则可以开始删除最旧的消息。kafka会启动一个后台线程,定期检查是否存在可以删除的消息
-------RabbitMQ------
数据消费完了,就会被移除,不能重复消费
-------RocketMQ------
1. 消息文件过期(默认72小时),且到达清理时点(默认是凌晨4点),删除过期文件。
2. 消息文件过期(默认72小时),且磁盘空间达到了水位线(默认75%),删除过期文件。
3. 磁盘已经达到必须释放的上限(85%水位线)的时候,则开始批量清理文件(无论是否过期),直
到空间充足。 注:若磁盘空间达到危险水位线(默认90%),出于保护自身的目的,broker会拒绝写入服务。
UI
--------Kafka--------
kafka-eagle
-------RabbitMQ------
RabbitMQ 可以通过命令(RabbitMQ CLI)、HTTP API 管理,也可以通过可视化 的界面去管理,这个网页就是 managment 插件。
ul默认地址是15672
linux启动插件。 cd /usr/lib/rabbitmq/bin ./rabbitmq-plugins enable rabbitmq_management
-------RocketMQ------
rocket官方提供了一个可视化控制台,地址:https://github.com/apache/rocketmq-externals
这个是rocketmq的扩展,里面不仅包含控制台的扩展,也包含对大数据flume、hbase等组件的对接和 扩展。
消息容错-死信队列
-------RabbitMQ------
TTL(Time To Live)
过期时间设置分两种
1) 通过队列属性设置消息过期时间 所有队列中的消息超过时间未被消费时,都会过期。
2)设置单条消息的过期时间 在发送消息的时候指定消息属性。
//第一种 @Bean("ttlQueue") public Queue queue() { Map<String, Object> map = new HashMap<String, Object>(); map.put("x-message-ttl", 11000); // 队列中的消息未被消费 11 秒后过期 return new Queue("GP_TTL_QUEUE", true, false, false, map); } //第二种 MessageProperties messageProperties = new MessageProperties(); messageProperties.setExpiration("4000"); // 消息的过期属性,单位 ms Message message = new Message("这条消息 4 秒后过期".getBytes(), messageProperties); rabbitTemplate.send("GP_TTL_EXCHANGE", "gupao.ttl", message);
什么情况下消息会变成死信?
1)消息被消费者拒绝并且未设置重回队列:(NACK || Reject ) && requeue == false
2)消息过期
3)队列达到最大长度,超过了 Max length(消息数)或者 Max length bytes (字节数),最先入队的消息会被发送到 DLX。
如何使用?
在声明正常队列的时候配置好死信队列(交换机)
//声明队列时,指定死信队列 @Bean("oriUseQueue") public Queue queue() { Map<String, Object> map = new HashMap<String, Object>(); map.put("x-message-ttl", 10000);
// 10 秒钟后成为死信map.put("x-dead-letter-exchange", "DEAD_LETTER_EXCHANGE");
// 队列中的消息变成死信后,进入死信交换机,找到匹配死信队列 return new Queue(“commonQueue”, true, false, false, map); }
扩展:
如何构造延迟队列?总的来说有三种实现方案
1、 先存储到数据库,用定时任务扫描
2、 利用 RabbitMQ 的死信队列(Dead Letter Queue)实现
3、 利用 rabbitmq-delayed-message-exchange 插件
流量控制
-------Kafka------
max.poll.records:
此设置限制每次调用poll返回的消息数,这样可以更容易的预测每次poll间隔要处理的最大值。通过调 整此值,可以减少poll间隔
-------RabbitMQ------
服务端流控(Flow Control)
队列有两个控制长度的属性:
x-max-length:队列中最大存储最大消息数,超过这个数量,队头的消息会被丢 弃。
x-max-length-bytes:队列中存储的最大消息容量(单位 bytes),超过这个容 量,队头的消息会被丢弃。
消费端限流
可以基于 Consumer 或者 channel 设置 prefetch count 的值,含义为 Consumer 端的最大的 unacked messages 数目。当超过这个数值的消息未被确认,RabbitMQ 会 停止投递新的消息给该消费者。
channel.basicQos(2); // 如果超过 2 条消息没有发送 ACK,当前消费者不再接受队列消息 channel.basicConsume(QUEUE_NAME, false, consumer); //SimpleMessageListenerContainer 配置 container.setPrefetchCount(2); //Spring Boot 配置: spring.rabbitmq.listener.simple.prefetch=2
好文章参考: