引用:http://blog.csdn.net/ccanan/article/details/7935183

http://www.humus.name/Articles/Persson_CreatingVastGameWorlds.pptx
http://www.humus.name/Articles/Persson_GraphicsGemsForGames.pptx
humus在siggraph12上做的关于just cause 2的渲染技术的分享,这里并不像voxel cone tracing里面会讲一个大的,一脉相承的道理,主要是各种游戏开发过程中很实用的一些做法,非常不错。
游戏的一些特点:
- 大:32kmx32km
- 动态:动态的天气,日夜变化,各种气候

uint32fixed_zs=(uint32(16777215.0f * depth + 0.5f) << 8) | stencil;
如果depth是1,返回的最终结果不是我们预想的0xffffffff,而是0,因为浮点数的精度问题,在16777215.0f这个数量级上,加0.5f会变成16777216.0f,而不是16777215.5f。
这里humus列了一个浮点数精度的一个表:
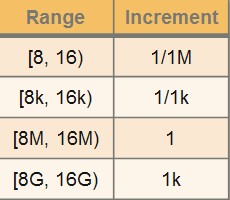
所以很自然也就引出了float的积累误差的问题,基本道理就是所有的计算,尽可能减少中间步骤,具体到实际的example,包括:
- 不要localPos乘以worldMatrix,然后乘以viewProjMatrix,最好能直接乘以MVP matrix
- 尽量不要去invert matrix,如果不得不如此的话,去构建inverse matrix
- 比如基于translation,scale, rotation的矩阵的inverse,完全可以使用-translation, 1/scale, -rotation来重新构建
- 使用3级的cascaded shadow map
- 3个light view depth,pack到一个buffer上,这样一个sample就可以搞定
- 使用snapping防止像素抖动,(http://blog.csdn.net/ccanan/article/details/7391961,这里也记录过cryengine也有同样的做法)
- 在cascade之间使用了dither来过渡自然
- 在不同的cascade中,设置object投射到屏幕空间的像素数量的阀值,小于这个阀值的就skip,这样远处的cascade可以提出大量的物件,进而提升效率
- 大量的tweak,在直升机上的时候的shadow的参数和地上跑的时候完全不同,这一点是程序和美术一起猛调
- 3张luminance的texture,会pack到一个dxt1的texture里面
- vertex format压缩
- <span style="font-family:Microsoft YaHei;">float4 angles=In.Tangents*PI2-PI;
- float4 sc0,sc1;
- sincos(angles.x,sc0.x, sc0.y);
- sincos(angles.y, sc0.z, sc0.w);
- sincos(angles.z, sc1.x, sc1.y);
- sincos(angles.w, sc1.z, sc1.w);
- float3 tangent = float3(sc0.y * abs(sc0.z), sc0.x * abs(sc0.z), sc0.w);
- float3 bitangent= float3(sc1.y * abs(sc1.z), sc1.x * abs(sc1.z), sc1.w);
- float3 normal = cross(tangent, bitangent);
- normal =(angles.w>0.0f)?normal:-normal;</span>
- <span style="font-family:Microsoft YaHei;">void UnpackQuat(float4 q, out float3 t, out float3 b, out float3 n)
- {
- t = float3(1,0,0) + float3(-2,2,2)*q.y*q.yxw + float3(-2,-2,2)*q.z*q.zwx;
- b = float3(0,1,0) + float3(2,-2,2)*q.z*q.wzy + float3(2,-2,-2)*q.x*q.yxw;
- n = float3(0,0,1) + float3(2,2,-2)*q.x*q.zwx + float3(-2,2,-2)*q.y*q.wzy;
- }
- float4 quat = In.TangentSpace * 2.0f - 1.0f;
- UnpackQuat(rotated_quat, tangent, bitangent, normal);
- </span>
particle trimming
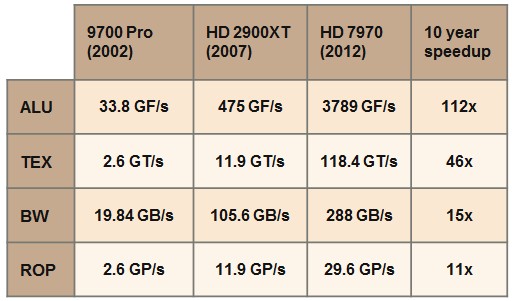
10年来,几项关键指标的变化,可以看出bandwidth和rop是变化最小的。
particle一直是消耗ROP的大户,使用接近贴图的非矩形来做particle的geometry,降低覆盖的pixel shader计算。

最右边的使用8个顶点来trim的情况,已经可以可以把面积减少到原来的%59.
有专门的工具来自动的进行trim。
draw call
节省drawcall这件事情在2003年有一个文章<batch!batch!batch!>很大声的讲了,但是到了2012年,已经不是这么回事了。
在pc上,driver model已经非常快了,尤其是在win7和dx11搭配的时候,drawcall的汇编指令是5条,而且里面没有call,是一个jmp,会立即返回。
在dx9上,还是有点小费,不过已经和我们早先听说的严重程度大不相同了,所以是否instancing的确要认真考虑,而且instancing在gpu里面会消耗更多的性能,在cull的时候会造成很大麻烦,时过境迁也。
culling
使用的brute force的cull,其中使用了simd指令。
just cause 2认为,基于hierarchy的场景管理虽然理论剔除会更高效,但是其中的执行过程非常的不cache友好,而且大量的branch会把节省的性能都吐回去。
而且hierarchy的维护和实现都麻烦和复杂很多。
最后just cause2选择的是bruce force box cull。
话说这个在之前项目里也发生过,一个哥们想测试四叉树到底比暴力做(还没用simd呢)快多少,结果是暴力更快,当然里面四叉树由于疏于维护,性能也不好。
cull的时候也用到了一些occluder,是美术摆进去的一些box,在大山里面,在大的建筑里面。。。
其他:
动态降resolution,会从720p逐渐降resolution,最低640p,群众表示比较ok。
shader performance script,这个会在相关的changelist上面,把shader的消耗(register num, instruction num。。。)和之前的版本做比较。
了解gpu的指令集,可以让shader写的更快更好。
要掂量掂量下自己的水平,不要做不成熟的优化和“高瞻远瞩”,很多预先的为以后的事情做出的设计会带来问题。
细线AA:对于很细的东西,会有比较严重的Alias情况,这里使用一个避免subpixel的方法来达到一个很不错的AA的算法:
在vertex shader里面把线所处的位置clamp到一个pixel的中心:

code:
- // Compute view-space w
- float w = dot(ViewProj[3], float4(In.Position.xyz, 1.0f));
- // Compute what radius a pixel wide wire would have
- float pixel_radius = w * PixelScale;
- // Clamp radius to pixel size. Fade with reduction in radius vs original.
- float radius = max(actual_radius, pixel_radius);
- float fade = actual_radius / radius;
- // Compute final position
- float3 position = In.Position + radius * normalize(In.Normal);