Spark作为分布式的大数据处理框架必然或涉及到大量的作业调度,如果能够理解Spark中的调度对我们编写或优化Spark程序都是有很大帮助的;
在Spark中存在转换操作(Transformation Operation)与 行动操作(Action Operation)两种;而转换操作只是会从一个RDD中生成另一个RDD且是lazy的,Spark中只有行动操作(Action Operation)才会触发作业的提交,从而引发作业调度;在一个计算任务中可能会多次调用 转换操作这些操作生成的RDD可能存在着依赖关系,而由于转换都是lazy所以当行动操作(Action Operation )触发时才会有真正的RDD生成,这一系列的RDD中就存在着依赖关系形成一个DAG(Directed Acyclc Graph),在Spark中DAGScheuler是基于DAG的顶层调度模块;
相关名词
Application:使用Spark编写的应用程序,通常需要提交一个或多个作业;
Job:在触发RDD Action操作时产生的计算作业
Task:一个分区数据集中最小处理单元也就是真正执行作业的地方
TaskSet:由多个Task所组成没有Shuffle依赖关系的任务集
Stage:一个任务集对应的调度阶段 ,每个Job会被拆分成诺干个Stage
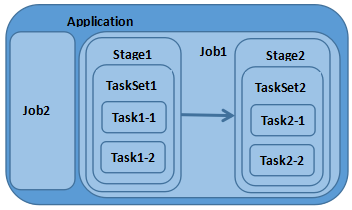
1.1 作业调度关系图
RDD Action作业提交流程
这里根据Spark源码跟踪触发Action操作时触发的Job提交流程,Count()是RDD中的一个Action操作所以调用Count时会触发Job提交;
在RDD源码count()调用SparkContext的runJob,在runJob方法中根据partitions(分区)大小创建Arrays存放返回结果;
RDD.scala
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
SparkContext.scala
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:
" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
}
在SparkContext中将调用DAGScheduler的runJob方法提交作业,DAGScheduler主要任务是计算作业与任务依赖关系,处理调用逻辑;DAGScheduler提供了submitJob与runJob方法用于 提交作业,runJob方法会一直等待作业完成,submitJob则返回JobWaiter对象可以用于判断作业执行结果;
在runJob方法中将调用submitJob,在submitJob中把提交操作放入到事件循环队列(DAGSchedulerEventProcessLoop)中;
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
......
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
......
}
在事件循环队列中将调用eventprocessLoop的onReceive方法;
Stage拆分
提交作业时DAGScheduler会从RDD依赖链尾部开始,遍历整个依赖链划分调度阶段;划分阶段以ShuffleDependency为依据,当没有ShuffleDependency时整个Job 只会有一个Stage;在事件循环队列中将会调用DAGScheduler的handleJobSubmitted方法,此方法会拆分Stage、提交Stage;
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
......
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
......
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
......
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
submitWaitingStages()
}
调度阶段提交
在提交Stage时会先调用getMissingParentStages获取父阶段Stage,迭代该阶段所依赖的父调度阶段如果存在则先提交该父阶段的Stage 当不存在父Stage或父Stage执行完成时会对当前Stage进行提交;
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
if (missing.isEmpty) {
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
}
......
}