神经网络理论
BP神经网络(Back Propagation Neural Network)为多层前馈神经网络用得比较广泛,该神经网络先通过前向传播取得估计值,后再使用误差进行反向传播通过梯度下降来不断地更新权重从而取得最小误差从中学习得最佳权重系数;从BP神经网络的名字也知道该算法的核心为反向传播算法,神经网络由多个神经元组成神经元结构如下:
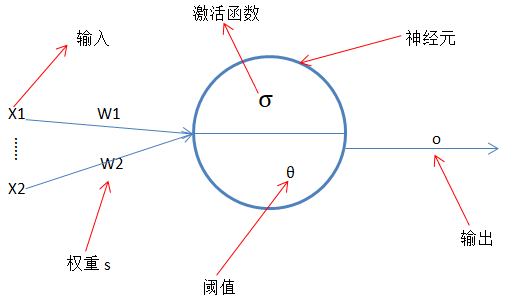
如上图每个神经元结构由输入、权重、阈值、激活函数、输出组成;
输入:接受上层的输出作为该神经元的输入
权重:连接上层神经元与该神经元
阈值:现在通常把该阈值独立为每层的一个偏置神经元参与权重与输入的加权和运算
输出:输入与权重加权和并通过激活函数产生的结果,并且该输出为下层神经元的输入
激活函数:作用为神经网络添加非线性因素,解决线性不可分问题,使神经网络能够处理更复杂的问题;
下图为两层神经网络,该网络的结构为:输入层、隐含层、输出层,称为两层神经网络是因为去掉输入层就只有两层,圆圈中为1的为偏置神经元,输入层节点数据属性并非神经元;神经网络可以有一个或多个隐含层,超过两个隐含层通过就可以称作深度神经网络,BP神经网络通常隐含层不会超过两个;
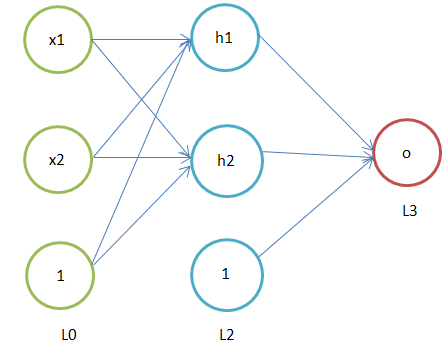
BP神经网络结构:



训练
一个BP神经网络流程主要以下几个步骤:正向传播、反向传播、计算误差、更新权重;下面通过一个示例来说明 BP神经网络的整个训练过程; 数据集:D={(x_1,y_1 ),(x_2,y_2 )},x_1∈R^2,y_1∈R^2,数据集包含2两个属性,2维输出向量;根据该数据集构建了神经网络结构如下图,两层神经网络拥有两个输入属性、两个输出神经元、两个隐含神经元、两个偏置神经元,总共2 x 2 x 2 = 8条权重; BP神经网络为迭代算法,我们通过不断的反向传播迭代更新权重w,从而神经元的输出也会随着调整,直到输出层得到的值与数据集的真实值误差总和最小或达到了迭代次数,此时终止模型训练,这些得到的权重w便是该神经网络的最佳参数;
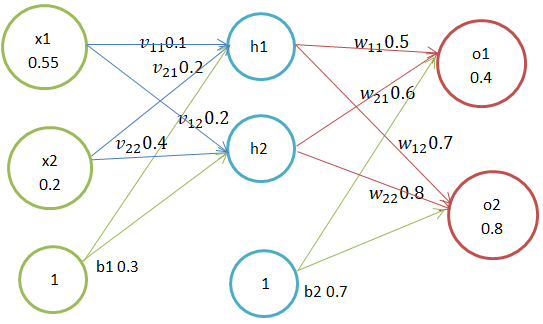
符号定义:
1、x1、x2...为输入层属性
2、h1、h2...为隐含层神经元
3、o1、o2...为输出层神经元
4、输入层节点中的数字为该输入属性值
5、v_xh为输入层第x个节点与隐含层第h个神经元的权重
6、w_ho为隐含层第h个神经元与输出层第o个神经元的权重
由于使用实数运算描述会有所复杂并且在代码层面实现时会存在大量的循环操作,所以这里会在有些地方使用向量来代替,下面看到加粗大写字母均为向量;如X表示为该神经网络的输入向量;
正向传播
通过从输入层、隐含层、输出层逐层计算每层神经元输出值;

1、输入层——》隐含层
计算隐含层h1、h2神经元的输入加权和:
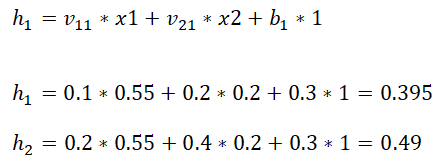
神经元h1输出:

2、隐含层——》输出层
计算输出层o1的输入加权和
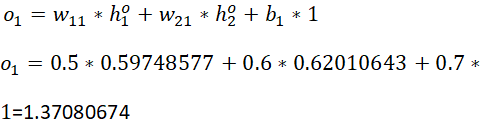
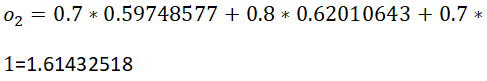
神经元o1输出:

此时求得的输出为:[0.79751046、0.83401102]
反向传播
上一步在正向传播时已经求得初步的估计值,现在先求出O1、O2的误差、总误差:
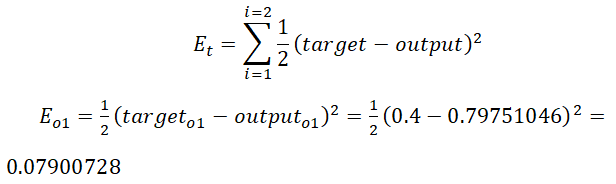
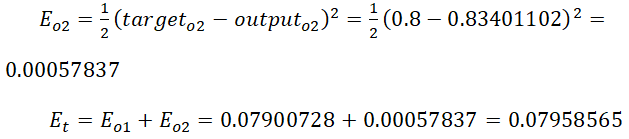
1、隐含层到输出层权重更新
通过求出总误差关于输出层权重的偏导,可以得到每个权重对总误差的影响,便可用于更新输出层权重;
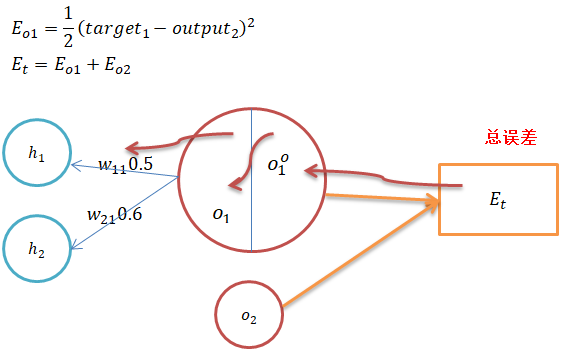
从上图可以看出总误差关于权重的偏导数可以应用微积分的链式法则,可分解为:总误差关于输出的偏导、输出关于加权和的偏导、加权和关于权重的偏导,三者的乘积;
总误差关于权重w11的偏导:
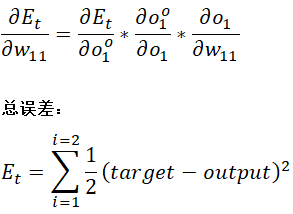
总误差关于输出的偏导:
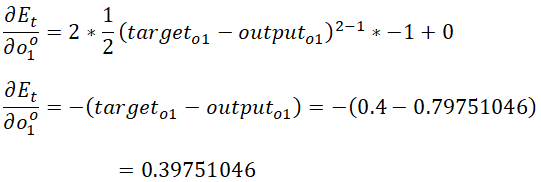
输出关于加权和的偏导:
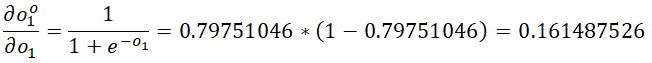
加权和关于权重的偏导:
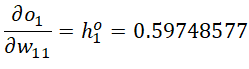
总误差关于权重的偏导数:
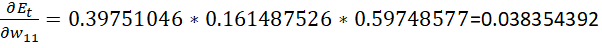

同理,连接隐含层与输出层其他权重更新如下:
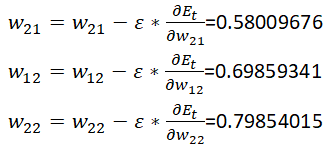
2、输入层到隐含层权重更新
与上面求隐含层到输出层权重的更新一样,这里也是求总误差关于权重的偏导;
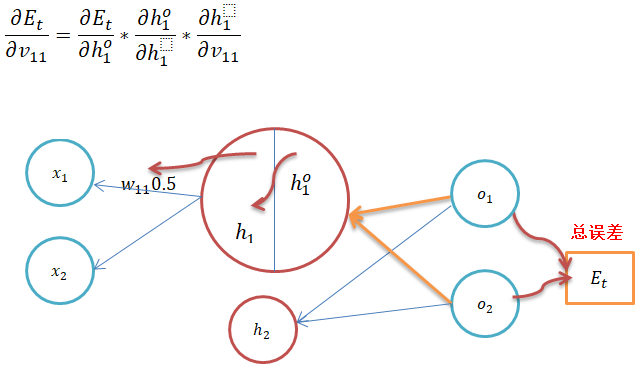
从上图可以看出隐含层h1神经元的输出有来自输出层O1、O2神经元传来的误差; 总误差关于h1输出的偏导数=O1误差关于h1输出的偏导数+ O2s误差关于h1输出的偏导数:
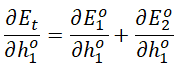
输出层O1神经元误差关于隐含层h1神经元输出的偏导:

**输出层O2神经元误差关于隐含层h1神经元输出的偏导: **

总误差关于h1输出的偏导数

隐含层输出关于加权和的偏导:
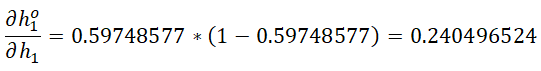
加权和关于权重的偏导:
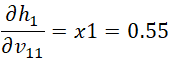
总误差关于权重的偏导数:
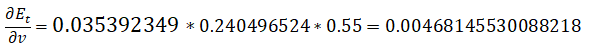
w_11权重更新(ε为学习率):
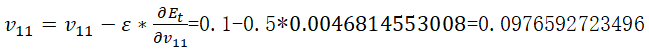
同理输入层与隐含层其他权重更新:

参考资料:
周志华 西瓜书
https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/