环境:Python2.7.10, selenium3.141.0, pytest4.6.6, pytest-html1.22.0, Windows-7-6.1.7601-SP1
特点:
- 二次封装了selenium,编写Case更加方便。
- 采用PO设计思想,一个页面一个Page.py,并在其中定义元素和操作方法;在TestCase中直接调用页面中封装好的操作方法操作页面。
- 一次测试只启动一次浏览器,节约时间提高效率(适合公司业务的才是最好的)。
- 增强pytest-html报告内容,加入失败截图、用例描述列、运行日志。
- 支持命令行参数。
- 支持邮件发送报告。
目录结构:
- config
- config.py:存放全局变量,各种配置、driver等
- drive:各浏览器驱动文件,如chromedriver.exe
- file
- download:下载文件夹
- screenshot:截图文件夹
- upload:上传文件夹
- page_object:一个页面一个.py,存放页面对象、操作方法
- base_page.py:基础页面,封装了selenium的各种操作
- hao123_page.py:hao123页面
- home_page.py:百度首页
- news_page.py:新闻首页
- search_page.py:搜索结果页
- report:
- report.html:pytest-html生成的报告
- test_case
- conftest.py:pytest特有文件,在里面增加了报告失败截图、用例描述列
- test_home.py:百度首页测试用例
- test_news.py:新闻首页测试用例
- test_search.py:搜索结果页测试用例
- util:工具包
- log.py:封装了日志模块
- mail.py:封装了邮件模块,使用发送报告邮件功能需要先设置好相关配置,如用户名密码
- run.py:做为运行入口,封装了pytest运行命令;实现所有测试用例共用一个driver;实现了运行参数化(结合Jenkins使用);log配置初始化;可配置发送报告邮件。
代码实现:


1 # coding=utf-8 2 3 import os 4 5 6 def init(): 7 global _global_dict 8 _global_dict = {} 9 10 # 代码根目录 11 root_dir = os.getcwd() 12 13 # 存放程序所在目录 14 _global_dict['root_path'] = root_dir 15 # 存放正常截图文件夹 16 _global_dict['screenshot_path'] = "{}\file\screenshot\".format(root_dir) 17 # 下载文件夹 18 _global_dict['download_path'] = "{}\file\download\".format(root_dir) 19 # 上传文件夹 20 _global_dict['upload_path'] = "{}\file\upload\".format(root_dir) 21 # 存放报告路径 22 _global_dict['report_path'] = "{}\report\".format(root_dir) 23 24 # 保存driver 25 _global_dict['driver'] = None 26 27 # 设置运行环境网址主页 28 _global_dict['site'] = 'https://www.baidu.com/' 29 # 运行环境,默认preview,可设为product 30 _global_dict['environment'] = 'preview' 31 32 33 def set_value(name, value): 34 """ 35 修改全局变量的值 36 :param name: 变量名 37 :param value: 变量值 38 """ 39 _global_dict[name] = value 40 41 42 def get_value(name, def_val='no_value'): 43 """ 44 获取全局变量的值 45 :param name: 变量名 46 :param def_val: 默认变量值 47 :return: 变量存在时返回其值,否则返回'no_value' 48 """ 49 try: 50 return _global_dict[name] 51 except KeyError: 52 return def_val
定义了全局的字典,用来存放全局变量,其key为变量名,value为变量值,可跨文件、跨用例传递参数。
其中set_value、get_value分别用来存、取全局变量。
1 # coding=utf-8 2 3 import logging 4 import time 5 import config.config as cf 6 7 8 class Logger(object): 9 """封装的日志模块""" 10 11 def __init__(self, logger, cmd_level=logging.DEBUG, file_level=logging.DEBUG): 12 try: 13 self.logger = logging.getLogger(logger) 14 self.logger.setLevel(logging.DEBUG) # 设置日志输出的默认级别 15 '''pytest报告可以自动将log整合进报告,不用再自己单独设置保存 16 # 日志输出格式 17 fmt = logging.Formatter( 18 '%(asctime)s[%(levelname)s] %(message)s') 19 # 日志文件名称 20 curr_time = time.strftime("%Y-%m-%d %H.%M.%S") 21 log_path = cf.get_value('log_path') 22 self.log_file = '{}log{}.txt'.format(log_path, curr_time) 23 # 设置控制台输出 24 sh = logging.StreamHandler() 25 sh.setFormatter(fmt) 26 sh.setLevel(cmd_level) 27 # 设置文件输出 28 fh = logging.FileHandler(self.log_file) 29 fh.setFormatter(fmt) 30 fh.setLevel(file_level) 31 # 添加日志输出方式 32 self.logger.addHandler(sh) 33 self.logger.addHandler(fh) 34 ''' 35 except Exception as e: 36 raise e 37 38 def debug(self, msg): 39 self.logger.debug(msg) 40 41 def info(self, msg): 42 self.logger.info(msg) 43 44 def error(self, msg): 45 self.logger.error(msg) 46 47 def warning(self, msg): 48 self.logger.warning(msg)
封装的log模块
1 # coding=utf-8 2 3 import smtplib 4 from email.mime.text import MIMEText 5 from email.mime.multipart import MIMEMultipart 6 from email.header import Header 7 import config.config as cf 8 9 10 def send_mail(sendto): 11 """ 12 发送邮件 13 :param sendto:收件人列表,如['22459496@qq.com'] 14 """ 15 mail_host = 'smtp.sohu.com' # 邮箱服务器地址 16 username = 'test@sohu.com' # 邮箱用户名 17 password = 'test' # 邮箱密码 18 receivers = sendto # 收件人 19 20 # 创建一个带附件的实例 21 message = MIMEMultipart() 22 message['From'] = Header(u'UI自动化', 'utf-8') 23 message['subject'] = Header(u'UI自动化测试结果', 'utf-8') # 邮件标题 24 message.attach(MIMEText(u'测试结果详见附件', 'plain', 'utf-8'))# 邮件正文 25 # 构造附件 26 report_root = cf.get_value('report_path') # 获取报告路径 27 report_file = 'report.html' # 报告文件名称 28 att1 = MIMEText(open(report_root + report_file, 'rb').read(), 'base64', 'utf-8') 29 att1["Content-Type"] = 'application/octet-stream' 30 att1["Content-Disposition"] = 'attachment; filename={}'.format(report_file) 31 message.attach(att1) 32 33 try: 34 smtp = smtplib.SMTP() 35 smtp.connect(mail_host, 25) # 25为 SMTP 端口号 36 smtp.login(username, password) 37 smtp.sendmail(username, receivers, message.as_string()) 38 print u'邮件发送成功' 39 except Exception, e: 40 print u'邮件发送失败' 41 raise e
封装的邮件模块,报告HTML文件会做为附件发送,这里需要把最上面的4个变量全改成你自己的。
1 # coding=utf-8 2 3 from selenium.common.exceptions import TimeoutException 4 from selenium.webdriver.support.ui import WebDriverWait 5 from selenium.webdriver.common.keys import Keys 6 from selenium.webdriver.common.action_chains import ActionChains 7 import os 8 import inspect 9 import config.config as cf 10 import logging 11 import time 12 13 log = logging.getLogger('szh.BasePage') 14 15 16 class BasePage(object): 17 def __init__(self): 18 self.driver = cf.get_value('driver') # 从全局变量取driver 19 20 def split_locator(self, locator): 21 """ 22 分解定位表达式,如'css,.username',拆分后返回'css selector'和定位表达式'.username'(class为username的元素) 23 :param locator: 定位方法+定位表达式组合字符串,如'css,.username' 24 :return: locator_dict[by], value:返回定位方式和定位表达式 25 """ 26 by = locator.split(',')[0] 27 value = locator.split(',')[1] 28 locator_dict = { 29 'id': 'id', 30 'name': 'name', 31 'class': 'class name', 32 'tag': 'tag name', 33 'link': 'link text', 34 'plink': 'partial link text', 35 'xpath': 'xpath', 36 'css': 'css selector', 37 } 38 if by not in locator_dict.keys(): 39 raise NameError("wrong locator!'id','name','class','tag','link','plink','xpath','css',exp:'id,username'") 40 return locator_dict[by], value 41 42 def wait_element(self, locator, sec=30): 43 """ 44 等待元素出现 45 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 46 :param sec:等待秒数 47 """ 48 by, value = self.split_locator(locator) 49 try: 50 WebDriverWait(self.driver, sec, 1).until(lambda x: x.find_element(by=by, value=value), 51 message='element not found!!!') 52 log.info(u'等待元素:%s' % locator) 53 return True 54 except TimeoutException: 55 return False 56 except Exception, e: 57 raise e 58 59 def get_element(self, locator, sec=60): 60 """ 61 获取一个元素 62 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 63 :param sec:等待秒数 64 :return: 元素可找到返回element对象,否则返回False 65 """ 66 if self.wait_element(locator, sec): 67 by, value = self.split_locator(locator) 68 print by, value 69 try: 70 element = self.driver.find_element(by=by, value=value) 71 log.info(u'获取元素:%s' % locator) 72 return element 73 except Exception, e: 74 raise e 75 else: 76 return False 77 78 def get_elements(self, locator): 79 """ 80 获取一组元素 81 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 82 :return: elements 83 """ 84 by, value = self.split_locator(locator) 85 try: 86 elements = WebDriverWait(self.driver, 60, 1).until(lambda x: x.find_elements(by=by, value=value)) 87 log.info(u'获取元素列表:%s' % locator) 88 return elements 89 except Exception, e: 90 raise e 91 92 def open(self, url): 93 """ 94 打开网址 95 :param url: 网址连接 96 """ 97 self.driver.get(url) 98 log.info(u'打开网址:%s' % url) 99 100 def clear(self, locator): 101 """ 102 清除元素中的内容 103 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 104 """ 105 self.get_element(locator).clear() 106 log.info(u'清空内容:%s' % locator) 107 108 def type(self, locator, text): 109 """ 110 在元素中输入内容 111 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 112 :param text: 输入的内容 113 """ 114 self.get_element(locator).send_keys(text) 115 log.info(u'向元素 %s 输入文字:%s' % (locator, text)) 116 117 def enter(self, locator): 118 """ 119 在元素上按回车键 120 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 121 """ 122 self.get_element(locator).send_keys(Keys.ENTER) 123 log.info(u'在元素 %s 上按回车' % locator) 124 125 def click(self, locator): 126 """ 127 在元素上单击 128 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 129 """ 130 self.get_element(locator).click() 131 log.info(u'点击元素:%s' % locator) 132 133 def right_click(self, locator): 134 """ 135 鼠标右击元素 136 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 137 """ 138 element = self.get_element(locator) 139 ActionChains(self.driver).context_click(element).perform() 140 log.info(u'在元素上右击:%s' % locator) 141 142 def double_click(self, locator): 143 """ 144 双击元素 145 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 146 """ 147 element = self.get_element(locator) 148 ActionChains(self.driver).double_click(element).perform() 149 log.info(u'在元素上双击:%s' % locator) 150 151 def move_to_element(self, locator): 152 """ 153 鼠标指向元素 154 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 155 """ 156 element = self.get_element(locator) 157 ActionChains(self.driver).move_to_element(element).perform() 158 log.info(u'指向元素%s' % locator) 159 160 def drag_and_drop(self, locator, target_locator): 161 """ 162 拖动一个元素到另一个元素位置 163 :param locator: 要拖动元素的定位 164 :param target_locator: 目标位置元素的定位 165 """ 166 element = self.get_element(locator) 167 target_element = self.get_element(target_locator) 168 ActionChains(self.driver).drag_and_drop(element, target_element).perform() 169 log.info(u'把元素 %s 拖至元素 %s' % (locator, target_locator)) 170 171 def drag_and_drop_by_offset(self, locator, xoffset, yoffset): 172 """ 173 拖动一个元素向右下移动x,y个偏移量 174 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 175 :param xoffset: X offset to move to 176 :param yoffset: Y offset to move to 177 """ 178 element = self.get_element(locator) 179 ActionChains(self.driver).drag_and_drop_by_offset(element, xoffset, yoffset).perform() 180 log.info(u'把元素 %s 拖至坐标:%s %s' % (locator, xoffset, yoffset)) 181 182 def click_link(self, text): 183 """ 184 按部分链接文字查找并点击链接 185 :param text: 链接的部分文字 186 """ 187 self.get_element('plink,' + text).click() 188 log.info(u'点击连接:%s' % text) 189 190 def alert_text(self): 191 """ 192 返回alert文本 193 :return: alert文本 194 """ 195 log.info(u'获取弹框文本:%s' % self.driver.switch_to.alert.text) 196 return self.driver.switch_to.alert.text 197 198 def alert_accept(self): 199 """ 200 alert点确认 201 """ 202 self.driver.switch_to.alert.accept() 203 log.info(u'点击弹框确认') 204 205 def alert_dismiss(self): 206 """ 207 alert点取消 208 """ 209 self.driver.switch_to.alert.dismiss() 210 log.info(u'点击弹框取消') 211 212 def get_attribute(self, locator, attribute): 213 """ 214 返回元素某属性的值 215 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 216 :param attribute: 属性名称 217 :return: 属性值 218 """ 219 value = self.get_element(locator).get_attribute(attribute) 220 log.info(u'获取元素 %s 的属性值 %s 为:%s' % (locator, attribute, value)) 221 return value 222 223 def get_ele_text(self, locator): 224 """ 225 返回元素的文本 226 :param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username' 227 :return: 元素的文本 228 """ 229 log.info(u'获取元素 %s 的文本为:%s' % (locator, self.get_element(locator).text)) 230 return self.get_element(locator).text 231 232 def frame_in(self, locator): 233 """ 234 进入frame 235 :param locator: 定位方法+定位表达式组合字符串,如'css,.username' 236 """ 237 e = self.get_element(locator) 238 self.driver.switch_to.frame(e) 239 log.info(u'进入frame:%s' % locator) 240 241 def frame_out(self): 242 """ 243 返回主文档 244 """ 245 self.driver.switch_to.default_content() 246 log.info(u'退出frame返回默认文档') 247 248 def open_new_window_by_locator(self, locator): 249 """ 250 点击元素打开新窗口,并将句柄切换到新窗口 251 :param locator: 定位方法+定位表达式组合字符串,如'css,.username' 252 """ 253 self.get_element(locator).click() 254 self.driver.switch_to.window(self.driver.window_handles[-1]) 255 log.info(u'点击元素 %s 打开新窗口' % locator) 256 257 # old_handle = self.driver.current_window_handle 258 # self.get_element(locator).click() 259 # all_handles = self.driver.window_handles 260 # for handle in all_handles: 261 # if handle != old_handle: 262 # self.driver.switch_to.window(handle) 263 264 def open_new_window_by_element(self, element): 265 """ 266 点击元素打开新窗口,并将句柄切换到新窗口 267 :param element: 元素对象 268 """ 269 element.click() 270 self.driver.switch_to.window(self.driver.window_handles[-1]) 271 log.info(u'点击元素打开新窗口') 272 273 def js(self, script): 274 """ 275 执行JavaScript 276 :param script:js语句 277 """ 278 self.driver.execute_script(script) 279 log.info(u'执行JS语句:%s' % script) 280 281 def scroll_element(self, locator): 282 """ 283 拖动滚动条至目标元素 284 :param locator: 定位方法+定位表达式组合字符串,如'css,.username' 285 """ 286 script = "return arguments[0].scrollIntoView();" 287 element = self.get_element(locator) 288 self.driver.execute_script(script, element) 289 log.info(u'滚动至元素:%s' % locator) 290 291 def scroll_top(self): 292 """ 293 滚动至顶部 294 """ 295 self.js("window.scrollTo(document.body.scrollHeight,0)") 296 log.info(u'滚动至顶部') 297 298 def scroll_bottom(self): 299 """ 300 滚动至底部 301 """ 302 self.js("window.scrollTo(0,document.body.scrollHeight)") 303 log.info(u'滚动至底部') 304 305 def back(self): 306 """ 307 页面后退 308 """ 309 self.driver.back() 310 log.info(u'页面后退') 311 312 def forward(self): 313 """ 314 页面向前 315 """ 316 self.driver.forward() 317 log.info(u'页面向前') 318 319 def is_text_on_page(self, text): 320 """ 321 返回页面源代码 322 :return: 页面源代码 323 """ 324 if text in self.driver.page_source: 325 log.info(u'判断页面上有文本:%s' % text) 326 return True 327 else: 328 log.info(u'判断页面上没有文本:%s' % text) 329 return False 330 331 def refresh(self): 332 """ 333 刷新页面 334 """ 335 self.driver.refresh() 336 log.info(u'刷新页面') 337 338 def screenshot(self, info='-'): 339 """ 340 截图,起名为:文件名-方法名-注释 341 :param info: 截图说明 342 """ 343 catalog_name = cf.get_value('screenshot_path') # 从全局变量取截图文件夹位置 344 if not os.path.exists(catalog_name): 345 os.makedirs(catalog_name) 346 class_object = inspect.getmembers(inspect.stack()[1][0])[-3][1]['self'] # 获得测试类的object 347 classname = str(class_object).split('.')[1].split(' ')[0] # 获得测试类名称 348 testcase_name = inspect.stack()[1][3] # 获得测试方法名称 349 filepath = catalog_name + classname + "@" + testcase_name + info + ".png" 350 self.driver.get_screenshot_as_file(filepath) 351 log.info(u'截图:%s.png' % info) 352 353 def close(self): 354 """ 355 关闭当前页 356 """ 357 self.driver.close() 358 self.driver.switch_to.window(self.driver.window_handles[0]) 359 log.info(u'关闭当前Tab') 360 361 def sleep(self, sec): 362 time.sleep(sec) 363 log.info(u'等待%s秒' % sec)
二次封装了selenium常用操作,做为所有页面类的基类。
本框架支持selenium所有的定位方法,为了提高编写速度,改进了使用方法,定义元素时方法名和方法值为一个用逗号隔开的字符串,如:
- xpath定位:i_keyword = 'xpath,//input[@id="kw"]' # 关键字输入框
- id定位:b_search = 'id,su' # 搜索按钮
- 其他定位方法同上,不再一一举例
使用时如上面代码中type()方法,是在如输入框中输入文字,调用时输入type(i_keyword, "输入内容")
type()中会调用get_element()方法,对输入的定位表达式进行解析,并且会等待元素一段时间,当元素出现时立即进行操作。
另外可以看到每个基本操作都加入了日志,下图即是用例运行后报告中记录的日志
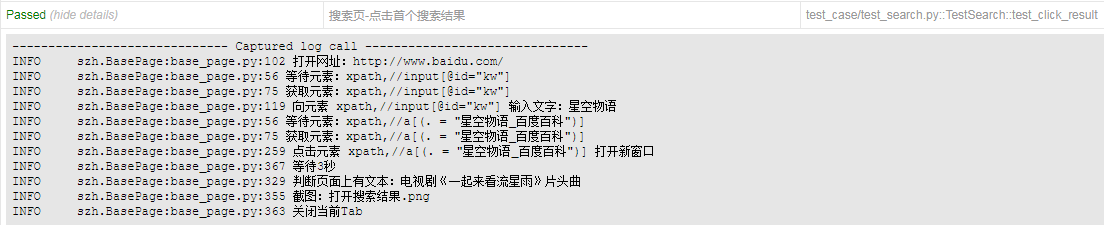
1 # coding=utf-8 2 3 from page_object.base_page import BasePage 4 5 6 class SearchPage(BasePage): 7 def __init__(self, driver): 8 self.driver = driver 9 10 # i=输入框, l=链接, im=图片, t=文字控件, d=div, lab=label 11 # 含_百度百科的搜索结果 12 l_baike = 'xpath,//a[(. = "星空物语_百度百科")]' 13 14 # 下一页 15 b_next_page = 'link,下一页>' 16 17 # 上一页 18 b_up_page = 'xpath,//a[(. = "<上一页")]' 19 20 # 点击搜索结果的百科 21 def click_result(self): 22 self.open_new_window_by_locator(self.l_baike) 23 self.sleep(3) 24 25 # 点击下一页 26 def click_next_page(self): 27 self.click(self.b_next_page)
PO模式中封装的百度的搜索页,继承了上面的BasePage类;每个页面类中上面定义各控件的表达式,下面将页面上的各种操作封装为方法。这样如果在多个用例中调用了控件或操作方法,将来更新维护只需要在页面类中改一下,所有用例就都更新了。
1 # coding=utf-8 2 3 import sys 4 reload(sys) 5 sys.setdefaultencoding('utf8') 6 from page_object.home_page import HomePage 7 from page_object.search_page import SearchPage 8 import pytest 9 import config.config as cf 10 11 12 class TestSearch(): 13 """ 14 pytest: 15 测试文件以test_开头 16 测试类以Test开头,并且不能带有__init__方法 17 测试函数以test_开头 18 断言使用assert 19 """ 20 driver = cf.get_value('driver') # 从全局变量取driver 21 home_page = HomePage(driver) 22 search_page = SearchPage(driver) 23 24 def test_click_result(self): 25 """搜索页-点击首个搜索结果""" 26 try: 27 self.home_page.open_homepage() 28 self.home_page.input_keyword(u'星空物语') # 输入关键字 29 self.search_page.click_result() # 点击百科 30 assert self.home_page.is_text_on_page(u'电视剧《一起来看流星雨》片头曲') # 验证页面打开 31 self.home_page.screenshot(u'打开搜索结果') 32 self.search_page.close() # 关闭百科页面 33 except Exception, e: 34 self.home_page.screenshot(u'打开搜索结果失败') 35 raise e 36 37 def test_click_next_page(self): 38 """搜索页-搜索翻页""" 39 try: 40 self.search_page.click_next_page() # 点下一页 41 assert self.home_page.wait_element(self.search_page.b_up_page) # 上一页出现 42 self.search_page.scroll_element(self.search_page.b_up_page) # 滚到上一页 43 self.home_page.screenshot(u'搜索翻页') 44 except Exception, e: 45 self.home_page.screenshot(u'搜索翻页失败') 46 raise e
百度搜索页的测试用例,这里我简单写了2个用例,第1个是搜索后点击首个搜索结果可打开,第2个是搜索结果可翻页。用例中的具体操作均是使用的上面页面类中封装好的操作方法。
1 # coding=utf-8 2 3 import pytest 4 from py._xmlgen import html 5 import config.config as cf 6 import logging 7 8 log = logging.getLogger('szh.conftest') 9 10 11 @pytest.mark.hookwrapper 12 def pytest_runtest_makereport(item): 13 """当测试失败的时候,自动截图,展示到html报告中""" 14 pytest_html = item.config.pluginmanager.getplugin('html') 15 outcome = yield 16 report = outcome.get_result() 17 extra = getattr(report, 'extra', []) 18 19 if report.when == 'call' or report.when == "setup": 20 xfail = hasattr(report, 'wasxfail') 21 if (report.skipped and xfail) or (report.failed and not xfail): 22 file_name = report.nodeid.replace("::", "_") + ".png" 23 driver = cf.get_value('driver') # 从全局变量取driver 24 screen_img = driver.get_screenshot_as_base64() 25 if file_name: 26 html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="600px;height:300px;" ' 27 'onclick="window.open(this.src)" align="right"/></div>' % screen_img 28 extra.append(pytest_html.extras.html(html)) 29 report.extra = extra 30 report.description = str(item.function.__doc__)#.decode('utf-8', 'ignore') # 不解码转成Unicode,生成HTML会报错 31 # report.nodeid = report.nodeid.encode("utf-8").decode("unicode_escape") 32 33 34 @pytest.mark.optionalhook 35 def pytest_html_results_table_header(cells): 36 cells.insert(1, html.th('Description')) 37 cells.pop() # 删除报告最后一列links 38 39 40 @pytest.mark.optionalhook 41 def pytest_html_results_table_row(report, cells): 42 cells.insert(1, html.td(report.description)) 43 cells.pop() # 删除报告最后一列links
conftest.py是pytest提供数据、操作共享的文件,其文件名是固定的,不可以修改。
conftest.py文件所在目录必须存在__init__.py文件。
其他文件不需要import导入conftest.py,pytest用例会自动查找
所有同目录测试文件运行前都会执行conftest.py文件
我只在conftest.py中加入了报错截图的功能,如果你有需要在用例前、后执行一些操作,都可以写在这里。
1 # coding=utf-8 2 3 import pytest 4 import config.config as cf 5 from util.log import Logger 6 import argparse 7 from selenium import webdriver 8 from util.mail import send_mail 9 10 11 def get_args(): 12 """命令行参数解析""" 13 parser = argparse.ArgumentParser(description=u'可选择参数:') 14 parser.add_argument('-e', '--environment', choices=['preview', 'product'], default='preview', help=u'测试环境preview,线上环境product') 15 args = parser.parse_args() 16 if args.environment in ('pre', 'preview'): 17 cf.set_value('environment', 'preview') 18 cf.set_value('site', 'http://www.baidu.com/') 19 elif args.environment in ('pro', 'product'): 20 cf.set_value('environment', 'preview') 21 cf.set_value('site', 'https://www.baidu.com/') 22 else: 23 print u"请输入preview/product" 24 exit() 25 26 27 def set_driver(): 28 """设置driver""" 29 # 配置Chrome Driver 30 chrome_options = webdriver.ChromeOptions() 31 chrome_options.add_argument('--start-maximized') # 浏览器最大化 32 chrome_options.add_argument('--disable-infobars') # 不提醒chrome正在受自动化软件控制 33 prefs = {'download.default_directory': cf.get_value('download_path')} 34 chrome_options.add_experimental_option('prefs', prefs) # 设置默认下载路径 35 # chrome_options.add_argument(r'--user-data-dir=D:ChromeUserData') # 设置用户文件夹,可免登陆 36 driver = webdriver.Chrome('{}\driver\chromedriver.exe'.format(cf.get_value('root_path')), options=chrome_options) 37 cf.set_value('driver', driver) 38 39 40 def main(): 41 """运行pytest命令启动测试""" 42 pytest.main(['-v', '-s', 'test_case/', '--html=report/report.html', '--self-contained-html']) 43 44 45 if __name__ == '__main__': 46 cf.init() # 初始化全局变量 47 get_args() # 命令行参数解析 48 log = Logger('szh') # 初始化log配置 49 set_driver() # 初始化driver 50 main() # 运行pytest测试集 51 cf.get_value('driver').quit() # 关闭selenium driver 52 53 # 先将util.mail文件send_mail()中的用户名、密码填写正确,再启用发送邮件功能!!! 54 send_mail(['22459496@qq.com']) # 将报告发送至邮箱
run.py用来做一些初始化的工作,运行测试,以及测试收尾,具体可以看代码中的注释。
我将浏览器driver的初始化放在了这里,并将driver存入全局变量,这样浏览器只需打开一次即可运行所有的测试。如果你想每个用例都打开、关闭一次浏览器,那可以把定义driver的方法放在conftest.py中。
get_args()是封装的命令行参数解析,方便集成Jenkins时快速定义运行内容。目前只定义了一个环境参数-e, 可设置测试环境preview,线上环境product,你可以根据需要添加更多参数。
调用方法:python run.py -e product
main()封装了pytest的命令行执行模式,你也可以按需修改。
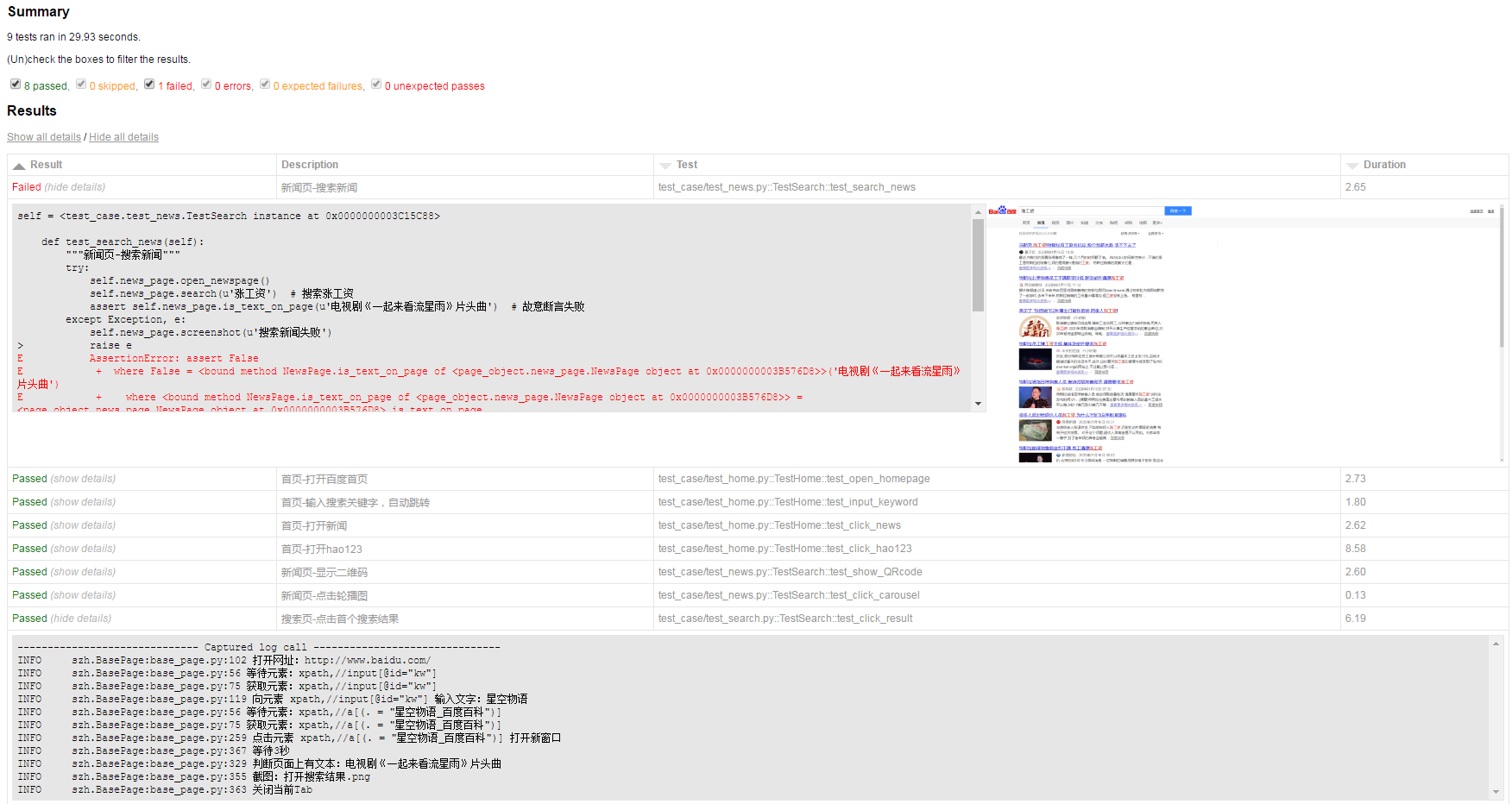
最后放一张运行后的测试报告的截图,我故意将某个用例写错,可以看到,报告中显示了具体的报错信息以及出错时页面的截图
所有代码可去GitHub获取:https://github.com/songzhenhua/selenium_ui_auto
---------------------------------------------------------------------------------
关注微信公众号即可在手机上查阅,并可接收更多测试分享~
