学习资源:慕课网liyubobobo老师的《玩儿转数据结构》
1、简介
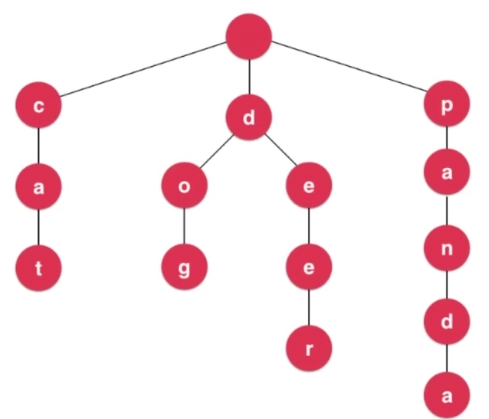
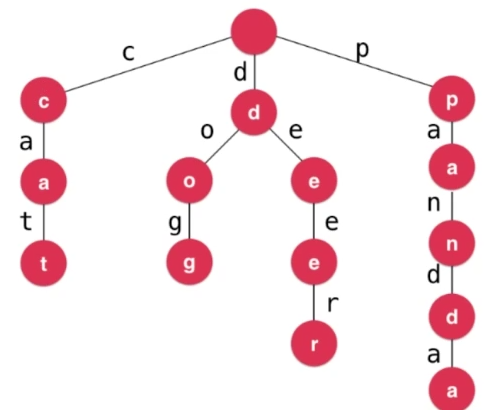
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。查询每个条目的时间复杂度,和字典中一共有多少条目无关,只与说查询的条目的长度有关。时间复杂度为O(w),w为查询单词的长度!
- 根结点不包含字符,除根结点外每一个结点都只包含一个字符
- 从根结点到某一结点,路径上经过的字符连接起来,为该结点对应的字符串;所以这条分支上可能有一个字符串,也可能有若干个字符串
- 每个结点的所有子结点包含的字符都不相同
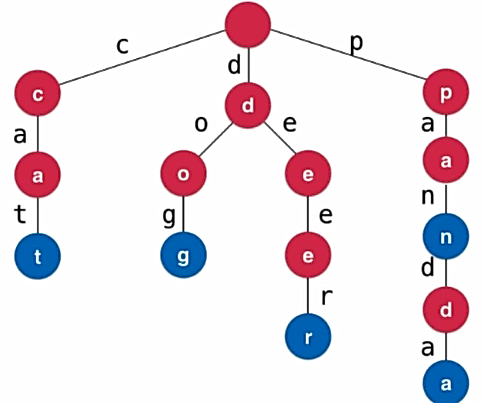
- 从根结点遍历到叶子结点即是一个单词;也有的单词不是到叶子结点,此时这个单词的最后一个结点需要特殊标记
2、原理分析
- 如果字典树中只储存英文单词,那每个结点至多有26个指向下个结点的"指针"
class Node{
char C; // 当前结点存储的字符
Node next[26]; // 当前结点的"指针",指向下一个结点的映射
}
- 如果存储情况复杂(语种多样),那么每个结点应有若干个指向下个结点的指针,此时可以使用一个Map记录当前结点的"指针"
class Node{
char C;
Map<char, Node> next;
}
- 每一个结点不需要存储具体的字符,在"指针"上存储当前结点指向的字符更合理
class Node{
char C;
Map<char, Node> next;
}
- 每一个结点需要设计一个标记,来记录从根结点到当前结点是否为一个单词
class Node{
boolean isWord;
Map<char, Node> next;
}
3、实现
3.1、基础部分代码
public class Trie {
private class Node{
boolean isWord;
TreeMap<Character, Node> next ;
public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
}
public Node(){
this(false);
}
}
private Node root;
private int size;
public Trie(){
root = new Node();
size = 0;
}
public int getSize() {
return size;
}
}
3.2、添加字符串
从根结点,向下遍历需要添加单词的每一个字符,如果当前结点存在指向字符的"指针"就跳过,不存在则创建(向Map中put)。
public void add(String word){
Node cur = root;
for(int i = 0; i< word.length(); i++){
char c = word.charAt(i);
if(cur.next.get(c) == null){
cur.next.put(c, new Node());
}
cur = cur.next.get(c);
}
if (!cur.isWord){
cur.isWord = true;
size++;
}
}
3.3、查询字符串
和添加操作差不多
public boolean contains(String word){
Node cur = root;
for(int i = 0; i<word.length(); i++){
char c = word.charAt(i);
if(cur.next.get(c) == null){
return false;
}
cur = cur.next.get(c);
}
return cur.isWord;
}
3.4、前缀搜索
查询在Trie中是否有单词以prefix为前缀
public boolean isPrefix(String prefix){
Node cur = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if(cur.next.get(c) == null){
return false;
}
cur = cur.next.get(c);
}
return true;
}