启动并查看集群的状况
第一步:启动Hadoop集群,这个在第二讲中讲解的非常细致,在此不再赘述:
启动之后在Master这台机器上使用jps命令,可以看到如下进程信息:
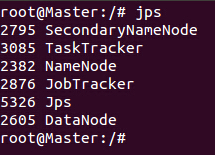
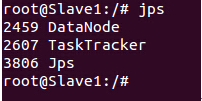
在Slave1 和Slave2上使用jps会看到如下进程信息:

第二步:启动Spark集群
在Hadoop集群成功启动的基础上,启动Spark集群需要使用Spark的sbin目录下“start-all.sh”:
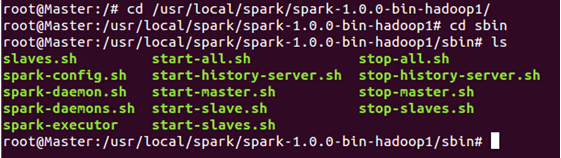
接下来使用“start-all.sh”来启动Spark集群!
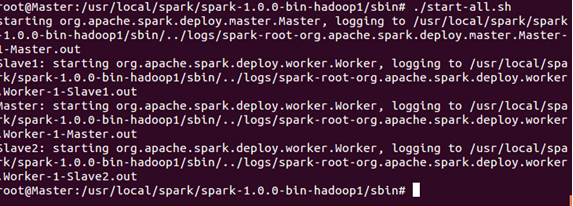
读者必须注意的是此时必须写成“./start-all.sh”来表明是当前目录下的“start-all.sh”,因为我们在配置Hadoop的bin目录中也有一个“start-all.sh”文件!
此时使用jps发现我们在主节点正如预期一样出现了“Master”和“Worker”两个新进程!
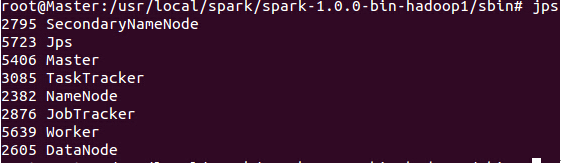
此时的Slave1和Slave2会出现新的进程“Worker”:

此时,我们可以进入Spark集群的Web页面,访问“http://Master:8080”: 如下所示:
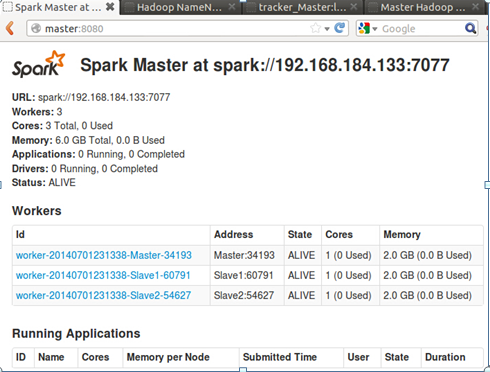
从页面上我们可以看到我们有三个Worker节点及这三个节点的信息。
此时,我们进入Spark的bin目录,使用“spark-shell”控制台:
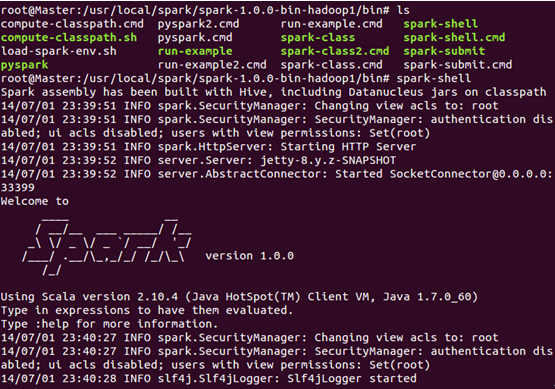
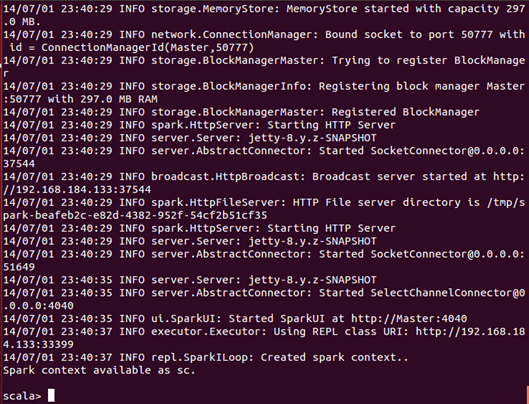
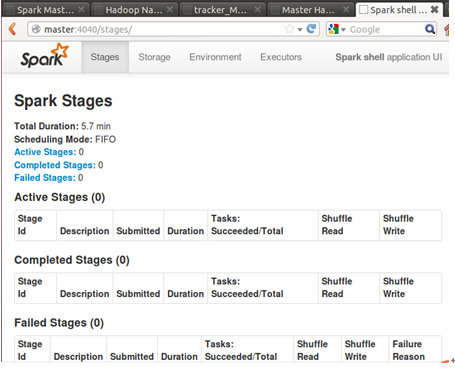
此时我们进入了Spark的shell世界,根据输出的提示信息,我们可以通过“http://Master:4040” 从Web的角度看一下SparkUI的情况,如下图所示:
当然,你也可以查看一些其它的信息,例如Environment:


同时,我们也可以看一下Executors:
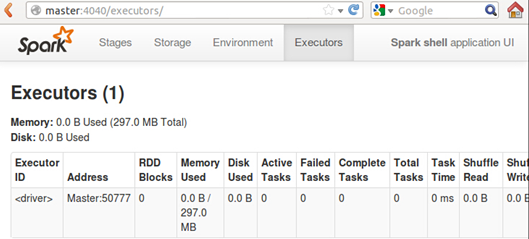
可以看到对于我们的shell而言,Driver是Master:50777.
至此,我们 的Spark集群搭建成功,Congratulations!